開發者們打造許多套件,替人們處理文字探勘。有些針對特定任務,例如在主題模型章節中我會介紹stm、LDA,在詞向量章節中則以gensim、word2vec為範例;也有些套件能夠貫穿整個文字探勘流程,例如這篇文章將要介紹的tidytext和quanteda。
雖然它們只是套件(library),但因爲開發者在設計套件時,已經預想到後續和專門任務的串接,同時也在套件中準備了泛用的文字探勘功能,因此,我特別以分析框架(framework)的規格,拉出一個章節說明。
在這篇介紹文中,會使用同一筆資料,這樣才能好好對比使用兩個框架時,流程和資料長相上的差異。我使用的資料是「歷年總統國慶大會演說」資料,資料來自維基百科文庫,從民國86年開始,一直到民國109年結束,共有24筆資料。
library(tidytext)
library(tidyverse)
df_speech_clean <- read_csv("data/df_speech_clean.csv")
df_speech_clean %>% glimpse()
## Rows: 24
## Columns: 5
## $ id <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23…
## $ text <chr> "大會主席、各位貴賓、各位親愛的父老兄弟姐妹:\n今天是中華民國八十六年國慶日,海內…
## $ title <chr> "總統蒞臨中華民國八十六年國慶大會致詞", "總統蒞臨中華民國八十七年國慶大會致詞", "…
## $ date <date> 1997-10-15, 1998-10-14, 1999-10-13, 2000-10-18, 2001-10-17, 2002-10-16, 2003-10-…
## $ president <chr> "李登輝", "李登輝", "李登輝", "陳水扁", "陳水扁", "陳水扁", "陳水扁", "陳水扁", "…
tidytexttidytext套件介紹看到這個標題,一定會讓你想到R語言當中著名的tidyverse宇宙。
沒錯,tidytext其實和tidyverse一樣,都遵守所謂的tidy data
principle,在相同的世界觀裡之中處理資料、分析資料。
舉例來說,在tidytext裡面利用函數unnest_tokens()分詞的時候,預設的資料結構為dataframe/tibble,斷詞(tokenization)後的產出同樣也是dataframe/tibble,相比之下,quanteda慣用的資料結構則是list,有很大對比。
在英文世界中,因為tidyverse的普及,又因為tidytext處理英文的方便,採用tidytext框架的分析非常之多,R語言相關著作裡,也以Julia Silge和David Robinson合著的這本Text Mining with R最為知名。
後來Julia Silge和Emil Hvitfeldt有另外合著一本Supervised Machine Learning for Text Analysis in R,但無論是內容的實用程度,或者是名氣都比不上前一本著作。不過,因為R語言中與自然語言處理(natural language processing)相關的高品質書籍並不多,這兩本都已經是箇中翹楚。
選用tidytext,你將可以預期自己的資料大部分時間都會是整齊的,即使要切換成其他資料格式例如語料(corpus),也有專門的函數幫助你;又因為還有tidymodels和ggplot2等tidyverse生態系底下的套件支援,你可以輕鬆將資料餵到模型裡,接著跑回歸或者分類,又或者排序出文字重要性後,立刻以ggplot視覺化呈現。
不過,tidytext在處理中文時,斷詞結果並不精準,尤其是對比專門為中文設計的jiebaR,更是相形見絀。因此,你可以直接啟用完全不同的框架如quanteda,或者是在其他套件中先處理好文字,接著再將成品重新導回tidyverse的世界。
就我自己來說,因為熟悉tidyverse,所以多半採用這個方法;但因為研究/工作需要,也有用quanteda跑過一次不同的流程,就看個人習慣和應用場景的特性!
tidytext實作在我們用的這份資料中,每一列都代表一篇文章。不過,從文章中我們很難發掘意義。跟10年前相比,最近的總統致詞有什麼樣的特色?更常提到哪些詞彙?更少用到什麼用字?詞彙之間的關係是什麼?句子是變得更長還是更簡潔?這些,都是以文章為單位的資料中,我們無法清楚看出的。
因此,我們利用tidytext中的unnest_tokens(),把原先代表文章的text欄位,以分詞函數unnest_tokens()分成詞彙word。
library(tidytext)
df_speech_token <- df_speech_clean %>%
unnest_tokens(word, text) %>%
select(word, everything())
df_speech_token %>% head(5)
## # A tibble: 5 × 5
## word id title date president
## <chr> <dbl> <chr> <date> <chr>
## 1 大會 1 總統蒞臨中華民國八十六年國慶大會致詞 1997-10-15 李登輝
## 2 主席 1 總統蒞臨中華民國八十六年國慶大會致詞 1997-10-15 李登輝
## 3 各位 1 總統蒞臨中華民國八十六年國慶大會致詞 1997-10-15 李登輝
## 4 貴賓 1 總統蒞臨中華民國八十六年國慶大會致詞 1997-10-15 李登輝
## 5 各位 1 總統蒞臨中華民國八十六年國慶大會致詞 1997-10-15 李登輝
我們可以發現,word欄位就是原本「大會主席、各位貴賓、各位親愛的父老兄弟姐妹」分詞後的模樣,差別只在標點符號於分詞過程中消失了。從原始的文字資料,經過unnest_tokens()分詞後,每筆資料都代表一個詞,這樣的資料在tidytext框架中,就被稱為「tidy text」資料(整齊、整潔的文字),這也貼合tidyverse開發者之一Hadley Wickam提過「tidy data」的精神。
得到tidy text之後,我們可以進一步利用dplyr彙整資料,得出有意義的指標,例如利用count()查看最常出現的詞彙,或者接續利用ggplot2視覺化。
library(tidyverse)
df_speech_token %>% count(word) %>%
arrange(desc(n))
## # A tibble: 6,421 × 2
## word n
## <chr> <int>
## 1 的 3163
## 2 我們 755
## 3 與 502
## 4 在 459
## 5 台灣 457
## 6 臺灣 269
## 7 國家 263
## 8 經濟 257
## 9 也 237
## 10 民主 233
## # ℹ 6,411 more rows
df_speech_token %>% count(word) %>%
arrange(desc(n)) %>%
head(10) %>%
mutate(word = fct_reorder(as_factor(word), n)) %>%
ggplot(aes(x = word, y = n)) +
geom_col() +
coord_flip() +
theme(text = element_text(family = "Noto Sans CJK TC Medium", size = 20))
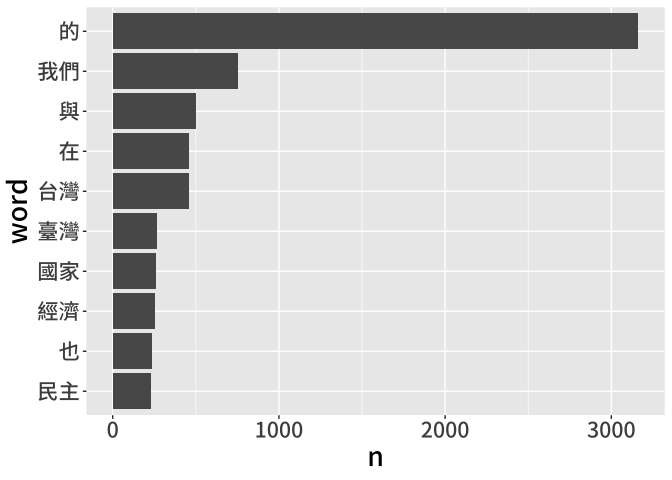
不過,你也能從上圖發現,分詞後的結果有些問題,事實上,這能夠折射出文字探勘中部分流程的必要性。舉例來說,「的」出現次數最多,但它有意義嗎?若想要從統計結果中排除,除了用肉眼篩選以外,理應能利用詞性刪除它,但現有欄位中,我們其實沒有詞性,是不是可以在分詞中加入這個詞?
再來,排名第五和第六的分別是「台灣」和「臺灣」,是不是應該事先整併?在其他語料中,可能還有繁體與簡體,以及中文國字和阿拉伯數字的相似狀況,我們也能先以字串處理技巧處理。
還有,現在出現的詞彙都是單詞,但如果我們其實想看複合詞的頻率呢?舉例來說,有學者想特別查看「台灣」「人」共同出現的次數,或者「中國」「政府」共同出現的次數,在現有資料結構底下,我們也無法完成這類的統計。
從上述三個例子可以看出,雖然unnest_tokens()分詞完,我們好像已經完成90%的任務,但實際上,沒有在事前做好字串處理,在分詞時沒有使用預寫的詞典,也沒有在分詞時貼上詞性,沒有針對結果清整,對文字探勘和後續資料分析的品質影響甚巨,後面的章節就會仔細分拆這些流程。

