續前一篇文章,我們談了如何利用tidytext處理「歷年總統國慶大會演說」資料,這篇文章我們同樣會利用相同資料,只是從tidytext改成使用quanteda。
quantedaquanteda套件介紹大約3年前,R User Group Taiwan曾經有幸邀請一位學者兼開發者Chung-hong Chan演講,當時我有出席,後來在學校上課時才知道,原來他是學校老師的好朋友與研究夥伴,又聽了一次他的分享。
在演講中,Chan介紹了全名為Quantitative Analysis of Textual Data的quanteda,翻譯即為文字資料量化分析。
和tidytext相同,你同樣可以利用quanteda走完一遍從前處理、斷詞、分析資料的流程,雖然使用的基本資料結構為list,但過程中並不會有任何不便,對中文的契合度也很高,是tidytext以外的好選項。
Chan另外寫有一本線上作品Automated Content Analysis,若對學術研究中的自動內容分析有興趣,也可以參考一下。
quanteda實作更改套件與框架,不代表改變我們的提問,我們關注的同樣是總統致詞有何特色。差異體現在quanteda不是在tidy
priciples底下運行,這個體系中資料用不同方式儲存,例如coprus、例如dfm,後面解釋文件資料的時候,會討論不同儲存文章/文件格式有何特色。
因為資料df_speech_clean原本是一個資料框,我們要先把它轉成quanteda熟悉的格式。
library(quanteda)
# import article
corp <- corpus(df_speech_clean)
corp
## Corpus consisting of 24 documents and 4 docvars.
## text1 :
## "大會主席、各位貴賓、各位親愛的父老兄弟姐妹: 今天是中華民國八十六年國慶日,海內外同胞用熱烈的活動,慶祝我們國家的生日;..."
##
## text2 :
## "大會主席、各位貴賓、各位親愛的父老兄弟姊妹: 今天是中華民國八十七年國慶日,海內外同胞用最歡喜的心情和最熱烈的活動,慶祝..."
##
## text3 :
## "各位女士、各位先生: 今天是中華民國八十八年國慶日。每年的這一天,我們都無比歡喜的慶祝國家的生日。但是,今天,我們卻要以..."
##
## text4 :
## "各位貴賓、各位女士、各位先生: 今天是中華民國八十九年國慶,我們以欣慰又嚴肅的心情來慶祝國家的生日。今年的雙十國慶,較之..."
##
## text5 :
## "各位貴賓、各位女士、各位先生: 今天是中華民國九十歲的生日,也是新世紀的第一個雙十國慶。一年多前,我們以實現歷史上首度的..."
##
## text6 :
## "各位貴賓、各位伙伴、各位女士、先生:大家恭喜! 今天是中華民國九十一年國慶,二千三百萬台灣人民及海內外同胞謹以最莊嚴、最..."
##
## [ reached max_ndoc ... 18 more documents ]
docvars(corp)
## id title date president
## 1 1 總統蒞臨中華民國八十六年國慶大會致詞 1997-10-15 李登輝
## 2 2 總統蒞臨中華民國八十七年國慶大會致詞 1998-10-14 李登輝
## 3 3 總統蒞臨中華民國八十八年國慶大會致詞 1999-10-13 李登輝
## 4 4 總統蒞臨中華民國八十九年國慶大會致詞 2000-10-18 陳水扁
## 5 5 總統蒞臨中華民國九十年國慶大會致詞 2001-10-17 陳水扁
## 6 6 總統蒞臨中華民國九十一年國慶大會致詞 2002-10-16 陳水扁
## 7 7 總統蒞臨中華民國九十二年國慶大會致詞 2003-10-15 陳水扁
## 8 8 總統蒞臨中華民國九十三年國慶大會致詞 2004-10-13 陳水扁
## 9 9 總統蒞臨中華民國九十四年國慶大會致詞 2005-10-12 陳水扁
## 10 10 總統蒞臨中華民國九十五年國慶大會致詞 2006-10-11 陳水扁
你可以發現corpus,或者稱其為語料、文集儲存資料的方式。「Corpus consisting of 24 documents and 4 docvars」告訴我們,corpus由文件(documents)和文件變數(docvars, document variables)組成。
不同框架,可以完成相同任務。舉例來說,你若只想看2009年以後的演說資料,我們處理資料框時,可以利用dplyr中的filter()篩選出2009年以後的演說;對應語料格式,同樣可以從docvars下手。就斷詞來說,我們也可以用quanteda達成。
# tokenize
ch_toks <- corp %>%
tokens(remove_punct = TRUE) %>%
tokens_remove(pattern = ch_stop)
# construct a dfm
ch_dfm <- dfm(ch_toks)
topfeatures(ch_dfm)
## 我們 與 台灣 臺灣 國家 經濟 民主 政府 為 人民
## 755 502 457 269 263 257 233 215 204 201
library("quanteda.textstats")
library("quanteda.textplots")
result_keyness <- textstat_keyness(ch_dfm)
textplot_keyness(result_keyness, margin = 0.2, n = 15, show_reference = F)
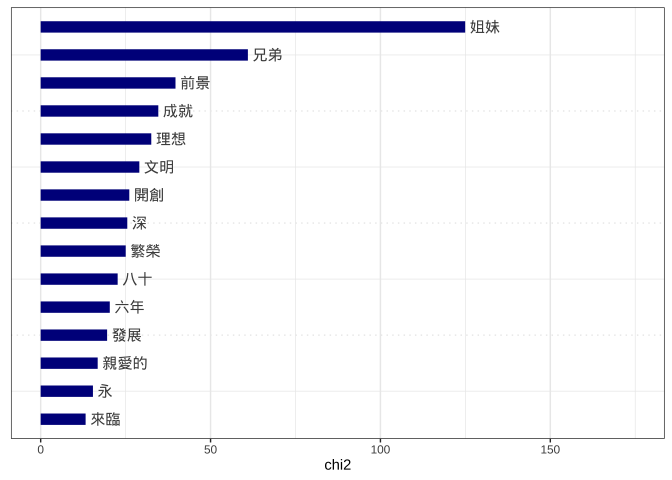
利用quanteda完全可以做到和tidytext相同的事情。事實上,它也有針對中文語料提供專門入門文章。你可以在文章中看到,quanteda可以分詞、建構建構文件特徵矩陣、計算文件相似度、訓練主題模型等任務。
不過,我必須老實承認,因為我實在太習慣跟資料框打交道,即使是使用quanteda時,我也會忍不住在途中,將成品適度轉換成資料框架確認品質,這樣做的理由在於quanteda確實提供方便的文字探勘流程。
另外我也會習慣客製化輸出的圖表,畢竟我們必須承認,上面那張圖並不是非常好看。整體來說,quanteda確實好用,只是沒那麼喜歡處理其他格式的資料,它非常值得倚重。

