我們得到資料後,最後一步就是視覺化了!因為重點是程式碼,所以沒有每張圖片都上傳,可以一張張研究!
library(gt)
df_year_word_top_wide %>% select(-year) %>%
rename(`年份` = year_full) %>%
rename(`總統` = president) %>%
gt::gt() %>%
tab_header(
title = "歷年總統國慶演說熱詞",
) %>%
tab_options(
heading.title.font.size = 24,
heading.subtitle.font.size = 14,
table.margin.left = 5,
table.margin.right = 5
) %>%
cols_align(align = "center", columns = everything()) %>%
opt_align_table_header(align = "center")
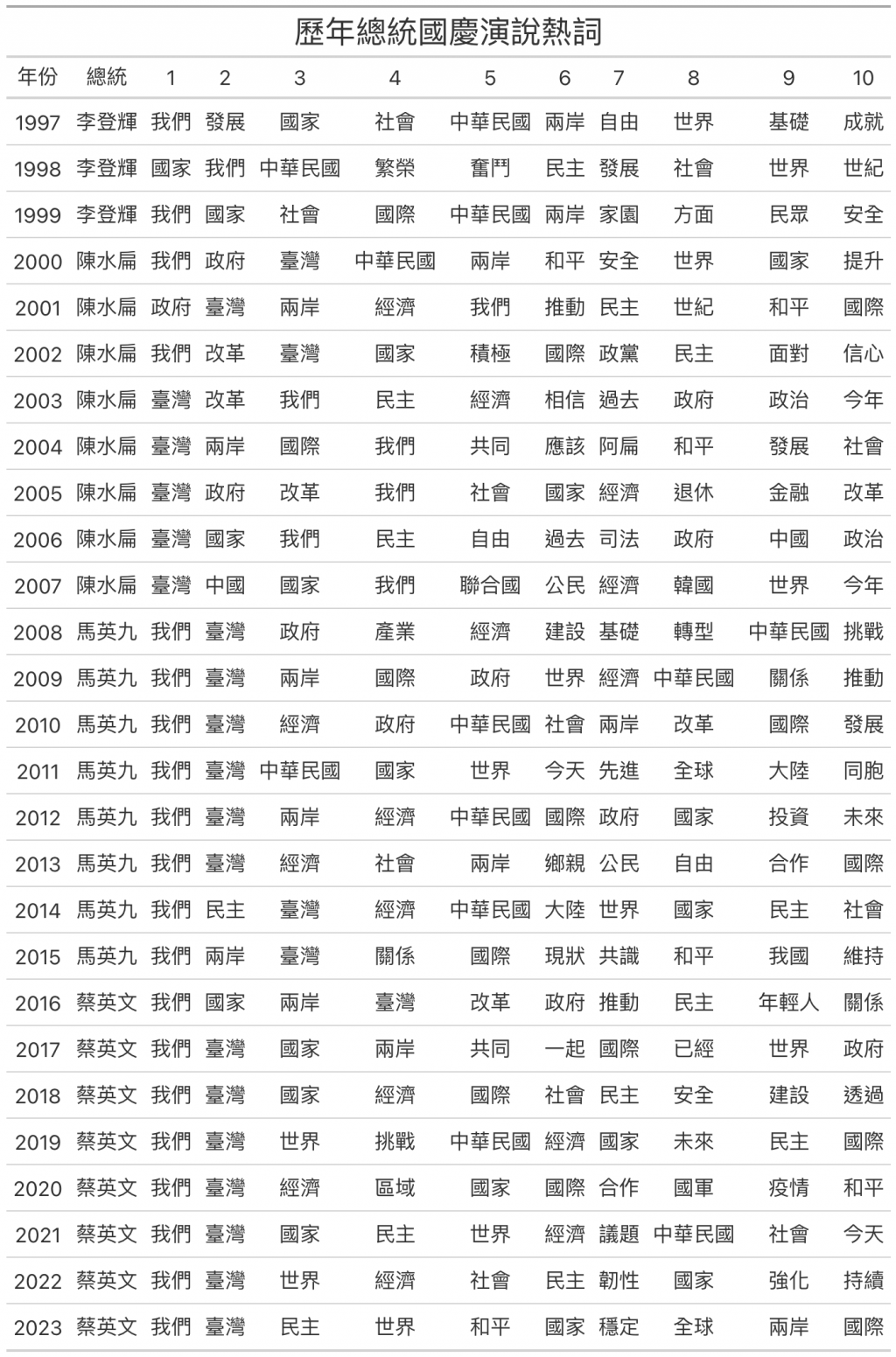
df_year_word_tfidf_top_wide %>%
rename(`年份` = year_full) %>%
rename(`總統` = president) %>%
gt::gt() %>%
tab_header(
title = "歷年總統國慶演說TF-IDF",
) %>%
tab_options(
heading.title.font.size = 24,
heading.subtitle.font.size = 14,
table.margin.left = 5,
table.margin.right = 5
) %>%
cols_align(align = "center", columns = everything()) %>%
opt_align_table_header(align = "center")
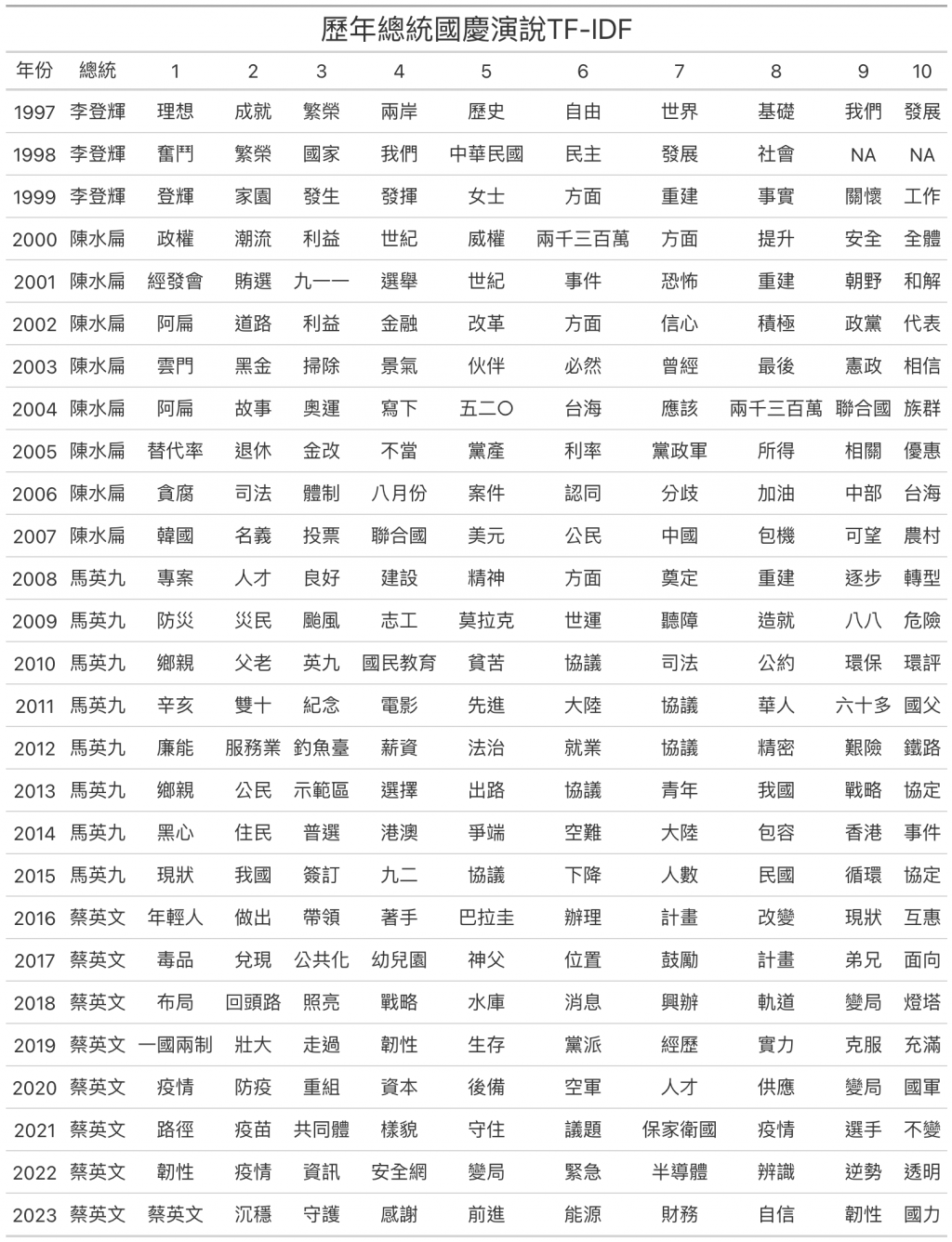
df_president_word_top_wide %>%
mutate(president = fct_relevel(as_factor(president), "李登輝","陳水扁","馬英九", "蔡English")) %>%
arrange(president) %>%
rename(`總統` = president) %>%
gt::gt() %>%
tab_header(
title = "總統任內國慶演說熱詞",
) %>%
tab_options(
heading.title.font.size = 24,
heading.subtitle.font.size = 14,
table.margin.left = 5,
table.margin.right = 5
) %>%
cols_align(align = "center", columns = everything()) %>%
opt_align_table_header(align = "center")
df_president_word_tfidf_top_wide %>%
mutate(president = fct_relevel(as_factor(president), "李登輝","陳水扁","馬英九", "蔡English")) %>%
arrange(president) %>%
rename(`總統` = president) %>%
gt::gt() %>%
tab_header(
title = "總統任內國慶演說TF-IDF",
) %>%
tab_options(
heading.title.font.size = 24,
heading.subtitle.font.size = 14,
table.margin.left = 5,
table.margin.right = 5
) %>%
cols_align(align = "center", columns = everything()) %>%
opt_align_table_header(align = "center")
tibble(`李登輝` = nearest_to(model_01,model_01[["中國"]]) %>% names() %>% `[`(2:4),
`陳水扁` = nearest_to(model_02,model_02[["中國"]]) %>% names() %>% `[`(2:4),
`馬英九` = nearest_to(model_03,model_03[["中國"]]) %>% names() %>% `[`(2:4),
`English` = nearest_to(model_04,model_04[["中國"]]) %>% names() %>% `[`(2:4)) %>%
gt::gt() %>%
tab_header(
title = "跟「中國」距離最近的詞彙",
) %>%
tab_options(
heading.title.font.size = 24,
heading.subtitle.font.size = 14,
table.margin.left = 5,
table.margin.right = 5
) %>%
cols_align(align = "center", columns = everything()) %>%
opt_align_table_header(align = "center")
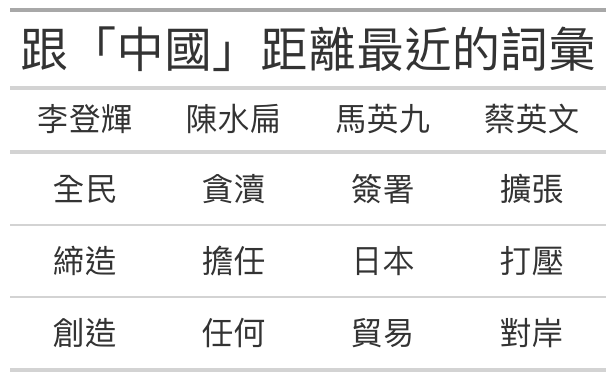
tibble(`李登輝` = nearest_to(model_01,model_01[["臺灣"]]) %>% names() %>% `[`(2:4),
`陳水扁` = nearest_to(model_02,model_02[["臺灣"]]) %>% names() %>% `[`(2:4),
`馬英九` = nearest_to(model_03,model_03[["臺灣"]]) %>% names() %>% `[`(2:4),
`English` = nearest_to(model_04,model_04[["臺灣"]]) %>% names() %>% `[`(2:4)) %>%
gt::gt() %>%
tab_header(
title = "跟「臺灣」距離最近的詞彙",
) %>%
tab_options(
heading.title.font.size = 24,
heading.subtitle.font.size = 14,
table.margin.left = 5,
table.margin.right = 5
) %>%
cols_align(align = "center", columns = everything()) %>%
opt_align_table_header(align = "center")
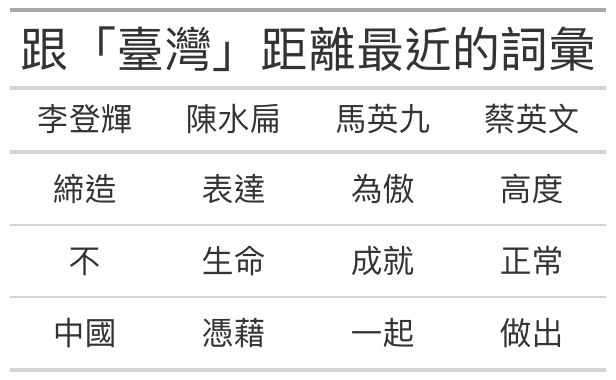
### 圖表
source("theme_vt_mac2.R")
### 中華民國與台灣
p_president_year_roc <-
df_president_year_roc %>%
mutate(n = as.integer(n)) %>%
mutate(year = as_date(str_c(year_full, "/1/1"))) %>%
ggplot(aes(x = year, y = n, group = text_type)) +
geom_col(position = "dodge", aes(fill = text_type)) +
facet_wrap(text_type ~ ., nrow = 2) +
scale_x_date(date_labels = "'%y", date_breaks = "2 years") +
scale_y_continuous(limits = c(0,100), breaks = seq(0,100,20)) +
scale_fill_manual(values = c("#000095", "#1B9431")) +
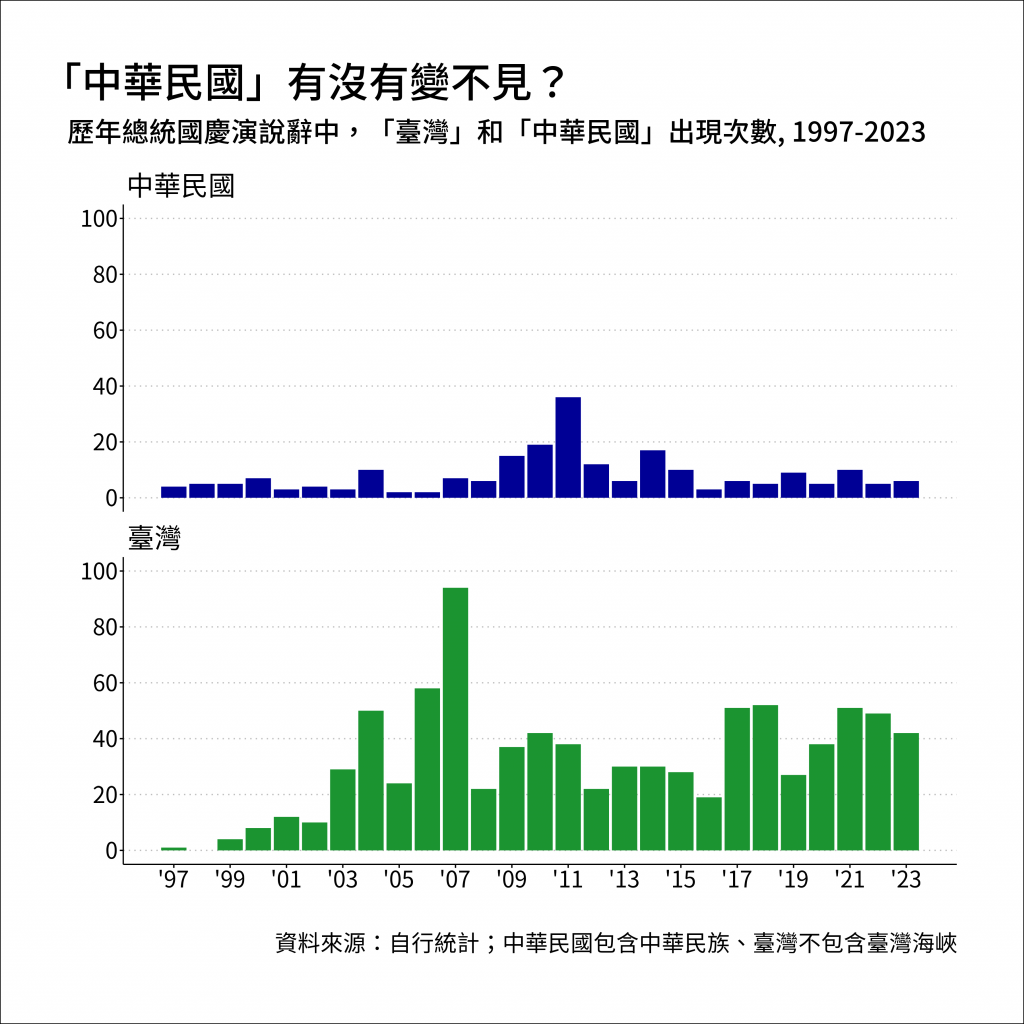
labs(x= "",y= "",
color = "學校類型",
title = "「中華民國」有沒有變不見?",
subtitle = "歷年總統國慶演說辭中,「臺灣」和「中華民國」出現次數, 1997-2023",
caption = "資料來源:自行統計;中華民國包含中華民族、臺灣不包含臺灣海峽") +
theme_vt +
theme(legend.position = "none",
strip.text = element_text(size = 72))
### 中美
p_president_year_foreign <-
df_president_year_foreign %>%
mutate(n = as.integer(n)) %>%
mutate(year = as_date(str_c(year_full, "/1/1"))) %>%
ggplot(aes(x = year, y = n, group = text_type)) +
geom_col(position = "dodge", aes(fill = text_type)) +
facet_wrap(text_type ~ ., nrow = 2) +
scale_x_date(date_labels = "'%y", date_breaks = "2 years") +
scale_y_continuous(limits = c(0,40), breaks = seq(0,40,10)) +
scale_fill_manual(values = c("#E9292B", "#3E346E")) +
labs(x= "",y= "",
color = "學校類型",
title = "兩岸關係仍是焦點,盟友偶爾出現",
subtitle = "歷年總統國慶演說辭中,「中國」和「美國」出現次數, 1997-2023",
caption = "資料來源:自行統計;中國包含大陸、北京、兩岸、中共,美國包含華府") +
theme_vt +
theme(legend.position = "none",
strip.text = element_text(size = 72))
word_cors_tsai %>%
filter(correlation > 0.3) %>%
igraph::graph_from_data_frame() %>%
ggraph(layout = "fr") +
geom_edge_link(aes(edge_alpha = correlation), show.legend = FALSE) +
geom_node_point(color = "lightblue", size = 10) +
geom_node_text(aes(label = name, family = "Noto Sans CJK TC Medium"), size = 32, repel = TRUE) +
labs(title = "宣示捍衛民主自由、維護區域和平是重點",
subtitle = "蔡English國慶演說詞彙關係網絡, 2016-2023",
caption = "資料來源:自行統計;相關係數達到0.3以上才列入") +
theme(plot.margin = margin(2, 2, 2, 2, "cm"),
plot.background = element_rect(fill = "white"), ##FFFAFA
strip.background = element_rect(fill = "white"), ##FFFAFA
panel.background = element_blank(),
panel.grid = element_blank(),
panel.grid.major = element_blank(), panel.grid.minor = element_blank(),
panel.grid.major.y = element_blank(),
text = element_text(family = "Noto Sans CJK TC Medium"),
plot.title = element_text(size = 108, family = "Noto Sans CJK TC Medium", hjust = 0, margin = margin(0,0,12,0)),
plot.subtitle = element_text(size = 84, family = "Noto Sans CJK TC Medium", hjust = 0, margin = margin(0,0,15,0)),
plot.caption = element_text(size = 60, family = "Noto Sans CJK TC Medium", margin = margin(40,0,0,0)),
legend.title = element_text(size = 60, family = "Noto Sans CJK TC Medium", angle = 0, hjust = 0),
legend.text = element_text(size = 42, family = "Noto Sans CJK TC Medium", angle = 0, hjust = 0),
legend.background = element_blank(),
legend.position = "none",
legend.key = element_rect(fill = "transparent"),
axis.line.x = element_blank(), axis.line.y = element_blank(),
axis.title = element_blank(),
axis.text = element_blank(),
plot.title.position = "plot",
plot.caption.position = "plot")
word_cors_ma %>%
filter(correlation > 0.4) %>%
igraph::graph_from_data_frame() %>%
ggraph(layout = "fr") +
geom_edge_link(aes(edge_alpha = correlation), show.legend = FALSE) +
geom_node_point(color = "lightblue", size = 10) +
geom_node_text(aes(label = name, family = "Noto Sans CJK TC Medium"), size = 32, repel = TRUE) +
labs(title = "顧好兩岸關係、簽訂貿易協定並保障就業",
subtitle = "馬英九國慶演說詞彙關係網絡, 2008-2015",
caption = "資料來源:自行統計;相關係數達到0.4以上才列入") +
theme(plot.margin = margin(2, 2, 2, 2, "cm"),
plot.background = element_rect(fill = "white"), ##FFFAFA
strip.background = element_rect(fill = "white"), ##FFFAFA
panel.background = element_blank(),
panel.grid = element_blank(),
panel.grid.major = element_blank(), panel.grid.minor = element_blank(),
panel.grid.major.y = element_blank(),
text = element_text(family = "Noto Sans CJK TC Medium"),
plot.title = element_text(size = 108, family = "Noto Sans CJK TC Medium", hjust = 0, margin = margin(0,0,12,0)),
plot.subtitle = element_text(size = 84, family = "Noto Sans CJK TC Medium", hjust = 0, margin = margin(0,0,15,0)),
plot.caption = element_text(size = 60, family = "Noto Sans CJK TC Medium", margin = margin(40,0,0,0)),
legend.title = element_text(size = 60, family = "Noto Sans CJK TC Medium", angle = 0, hjust = 0),
legend.text = element_text(size = 42, family = "Noto Sans CJK TC Medium", angle = 0, hjust = 0),
legend.background = element_blank(),
legend.position = "none",
legend.key = element_rect(fill = "transparent"),
axis.line.x = element_blank(), axis.line.y = element_blank(),
axis.title = element_blank(),
axis.text = element_blank(),
plot.title.position = "plot",
plot.caption.position = "plot")
word_cors_chen %>%
filter(correlation > 0.35) %>%
igraph::graph_from_data_frame() %>%
ggraph(layout = "fr") +
geom_edge_link(aes(edge_alpha = correlation), show.legend = FALSE) +
geom_node_point(color = "lightblue", size = 10) +
geom_node_text(aes(label = name, family = "Noto Sans CJK TC Medium"), size = 32, repel = TRUE) +
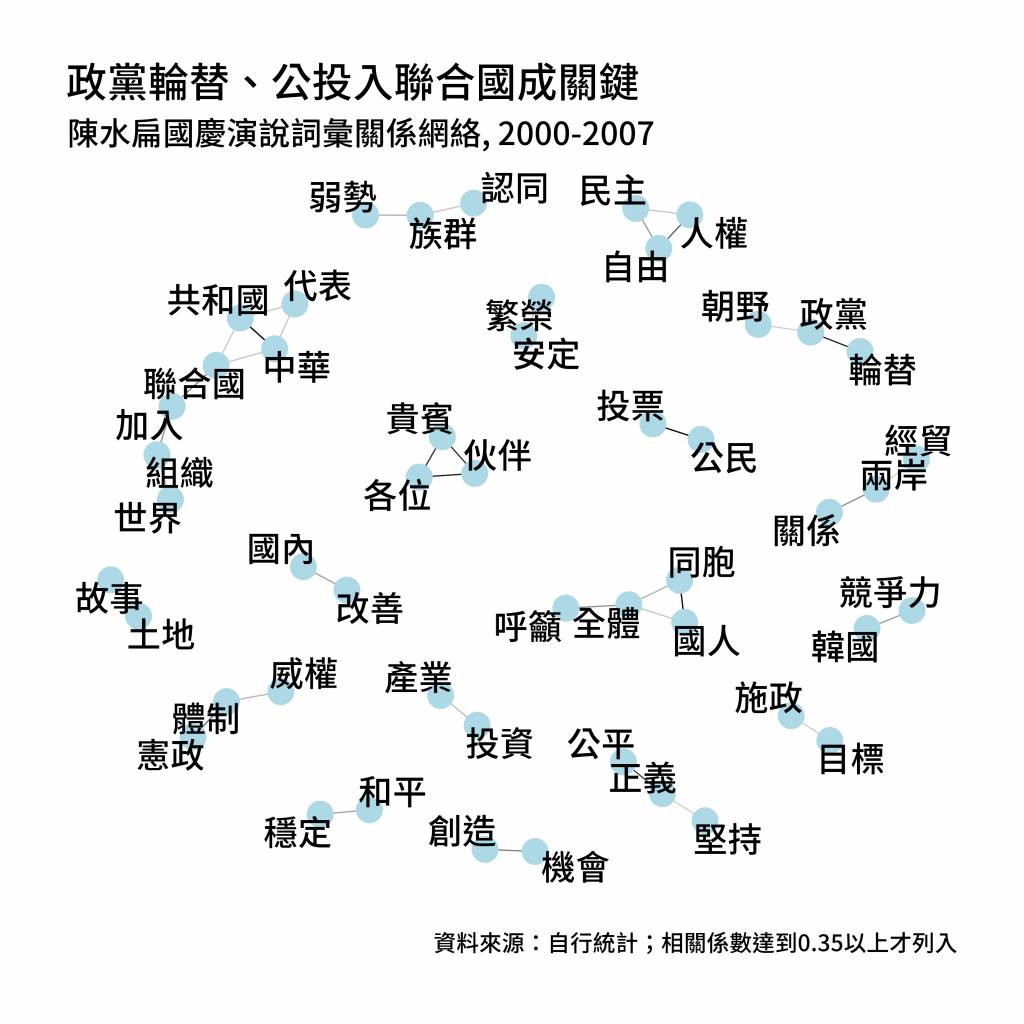
labs(title = "政黨輪替、公投入聯合國成關鍵",
subtitle = "陳水扁國慶演說詞彙關係網絡, 2000-2007",
caption = "資料來源:自行統計;相關係數達到0.35以上才列入") +
theme(plot.margin = margin(2, 2, 2, 2, "cm"),
plot.background = element_rect(fill = "white"), ##FFFAFA
strip.background = element_rect(fill = "white"), ##FFFAFA
panel.background = element_blank(),
panel.grid = element_blank(),
panel.grid.major = element_blank(), panel.grid.minor = element_blank(),
panel.grid.major.y = element_blank(),
text = element_text(family = "Noto Sans CJK TC Medium"),
plot.title = element_text(size = 108, family = "Noto Sans CJK TC Medium", hjust = 0, margin = margin(0,0,12,0)),
plot.subtitle = element_text(size = 84, family = "Noto Sans CJK TC Medium", hjust = 0, margin = margin(0,0,15,0)),
plot.caption = element_text(size = 60, family = "Noto Sans CJK TC Medium", margin = margin(40,0,0,0)),
legend.title = element_text(size = 60, family = "Noto Sans CJK TC Medium", angle = 0, hjust = 0),
legend.text = element_text(size = 42, family = "Noto Sans CJK TC Medium", angle = 0, hjust = 0),
legend.background = element_blank(),
legend.position = "none",
legend.key = element_rect(fill = "transparent"),
axis.line.x = element_blank(), axis.line.y = element_blank(),
axis.title = element_blank(),
axis.text = element_blank(),
plot.title.position = "plot",
plot.caption.position = "plot")
word_cors_lee %>%
filter(correlation > 0.15) %>%
igraph::graph_from_data_frame() %>%
ggraph(layout = "fr") +
geom_edge_link(aes(edge_alpha = correlation), show.legend = FALSE) +
geom_node_point(color = "lightblue", size = 10) +
geom_node_text(aes(label = name, family = "Noto Sans CJK TC Medium"), size = 32, repel = TRUE) +
labs(title = "政黨輪替、公投入聯合國成關鍵",
subtitle = "李登輝國慶演說詞彙關係網絡, 2000-2007",
caption = "資料來源:自行統計;相關係數達到0.35以上才列入") +
theme(plot.margin = margin(2, 2, 2, 2, "cm"),
plot.background = element_rect(fill = "white"), ##FFFAFA
strip.background = element_rect(fill = "white"), ##FFFAFA
panel.background = element_blank(),
panel.grid = element_blank(),
panel.grid.major = element_blank(), panel.grid.minor = element_blank(),
panel.grid.major.y = element_blank(),
text = element_text(family = "Noto Sans CJK TC Medium"),
plot.title = element_text(size = 108, family = "Noto Sans CJK TC Medium", hjust = 0, margin = margin(0,0,12,0)),
plot.subtitle = element_text(size = 84, family = "Noto Sans CJK TC Medium", hjust = 0, margin = margin(0,0,15,0)),
plot.caption = element_text(size = 60, family = "Noto Sans CJK TC Medium", margin = margin(40,0,0,0)),
legend.title = element_text(size = 60, family = "Noto Sans CJK TC Medium", angle = 0, hjust = 0),
legend.text = element_text(size = 42, family = "Noto Sans CJK TC Medium", angle = 0, hjust = 0),
legend.background = element_blank(),
legend.position = "none",
legend.key = element_rect(fill = "transparent"),
axis.line.x = element_blank(), axis.line.y = element_blank(),
axis.title = element_blank(),
axis.text = element_blank(),
plot.title.position = "plot",
plot.caption.position = "plot")
### 雙英對決
df_ying_seg_count <- df_speech_seg_unnest %>%
filter(president %in% c("馬英九", "蔡English")) %>%
filter(!text_POS %in% c("Puncuation")) %>%
filter(str_length(text_segment) > 1) %>%
anti_join(df_stopwords) %>%
count(president, text_segment)
df_ying_seg_diff <- df_ying_seg_count %>%
pivot_wider(names_from = president, values_from = n, values_fill = list(n = 0)) %>%
mutate(diff_tsai = `蔡English` - `馬英九`, diff_ma = -diff_tsai)
df_ying_seg_diff %>% arrange(desc(diff_tsai)) %>%
slice(1:10) %>%
select(text_segment, diff = diff_tsai) %>% mutate(president = "蔡English") %>%
bind_rows(
df_ying_seg_diff %>% arrange(desc(diff_ma)) %>%
slice(1:10) %>%
select(text_segment, diff = diff_ma) %>% mutate(president = "馬英九")
) %>%
mutate(diff2 = if_else(president == "馬英九", -diff, diff)) %>%
mutate(text_segment = reorder(text_segment, diff2)) %>%
ggplot(aes(x = diff2, y = text_segment, fill = president)) + geom_col() +
theme_bw() +
scale_fill_manual(values = c("#1B9431", "#000095")) +
labs(x= "使用次數的差異",y= "",
title = "蔡English提到更多挑戰、馬英九談論更多經濟",
subtitle = "雙英對決:馬英九與蔡English使用次數差異最大詞彙",
caption = "資料來源:自行統計") +
theme_vt +
theme(legend.position = "none",
strip.text = element_text(size = 72))
### 熱詞
df_word_count_top <- df_speech_seg_unnest %>%
filter(!text_POS %in% c("Puncuation")) %>%
filter(str_length(text_segment) > 1) %>%
anti_join(df_stopwords) %>%
count(text_segment) %>%
arrange(desc(n)) %>% ungroup() %>%
slice(1:10) %>% select(text_segment)
df_year_word_count %>%
group_by(year_full, text_segment) %>%
summarise(n = sum(n)) %>%
mutate(year = as_date(str_c(year_full, "/1/1"))) %>%
inner_join(df_word_count_top) %>%
ggplot(aes(x = year, y = text_segment, fill = n)) + geom_tile() +
theme_bw() +
scale_x_date(date_labels = "'%y", date_breaks = "2 years") +
scale_fill_gradient(low = "white", high = "red")+
labs(x= "",y= "", title = "歷屆總統演說 - 總體使用熱詞", fill = "次數") +
theme_vt +
theme(legend.position = "none") +
theme(panel.grid.major = element_blank(), panel.grid.minor = element_blank(),
panel.background = element_blank(), axis.line = element_line(colour = "black"))
###
df_president_seg_count <- df_year_word_count %>%
filter(!text_POS %in% c("Puncuation")) %>%
anti_join(df_stopwords) %>%
group_by(president, text_segment) %>%
summarise(n = sum(n))
df_president_seg_count_top <- df_president_seg_count %>% group_by(president) %>%
arrange(president, desc(n)) %>% mutate(rn = row_number()) %>%
filter(rn <= 10) %>% ungroup() %>%
group_by(president) %>% arrange(president, n) %>% ungroup() %>%
mutate(president = fct_relevel(as.factor(president), "李登輝", "陳水扁", "馬英九", "蔡English")) %>%
mutate(text_order = str_c(text_segment, president, rn) %>% forcats::fct_inorder()) %>%
select(president, text_segment, text_order, rn, n)
df_president_seg_count_top %>%
ggplot(aes(x = text_order, y = n)) + geom_col() +
facet_wrap(president ~ ., scales = "free") +
coord_flip() +
theme_bw() +
scale_linetype(guide = "none") +
scale_x_discrete(labels = setNames(as.character(df_president_seg_count_top$text_segment), df_president_seg_count_top$text_order)) +
scale_fill_gradient(low = "white", high = "red")+
labs(x= "",y= "",
# color = "學校類型",
title = "總統之間講的熱門語彙中,都有臺灣",
subtitle = "歷任總統國慶演說辭熱門詞彙, 1997-2023",
caption = "資料來源:自行統計") +
theme_vt
### tfidf
df_president_tfidf <- df_president_seg_count %>% filter(n > 4) %>%
bind_tf_idf(text_segment, president, n) %>%
group_by(president) %>% arrange(desc(tf_idf)) %>%
slice(1:10) %>% ungroup() %>%
mutate(president = fct_relevel(as.factor(president), "李登輝", "陳水扁", "馬英九", "蔡English")) %>%
mutate(text_segment = fct_reorder(text_segment, tf_idf))
df_president_tfidf %>%
ggplot(aes(x = text_segment, y = tf_idf)) + geom_col() +
facet_wrap(president ~ ., scales = "free") +
coord_flip() +
theme_bw() +
labs(x= "年份",y= "tf-idf", title = "歷屆總統演說 - tfidf", fill = "次數") +
labs(x= "",y= "",
title = "政黨輪替、與大陸簽訂協議、再到疫情與韌性",
subtitle = "歷任總統國慶演說辭重要詞彙, 1997-2023",
caption = "資料來源:自行統計;以 tf-idf 計算重要詞彙") +
theme_vt

