
今天來介紹有關在mapping時可以設置的參數,其中也有一些坑需要大家注意
前半部會先介紹相關的一些參數以及如何設定
後半部則會說明在設置mapping時如何進行最佳化處理
那我們就開始吧~
properties:
像是object或是nested field,有包含sub_field時調用
"field_name": {
"type": "nested",
"properties": {
"age": { "type": "integer" },
"name": { "type": "text" }
}
}
在查詢或是聚合等,需要調用inner field時可以用.來使用
"query": {
"match": {
"field_name.inner_field_name": ""
}
}
format:
在document中,如果有date相關的欄位通常是string的形式
設置format可以讓ES去解析這些string轉成date type
{
"mappings": {
"properties": {
"date": {
"type": "date",
"format": "yyyy-MM-dd"
}
}
}
}
PUT /test_date
{
"mappings": {
"properties": {
"my_date_field": {
"type": "date",
"format": "strict_date"
}
}
}
}
如果你想讓多種date format能使用,用||來分隔兩種形式,即使寫在array中也是(雖然我用array創建都會有mapper_parsing_exception,但是官方文檔是用array示範,可能是要注意的點)
"format": "yyyy/MM||dd/MM/yyyy"
Coerce:
在開始介紹之前,我們先來做個測試
PUT /test_coerce/_doc/1
{
"id": 1
}
GET /test_coerce/_mapping
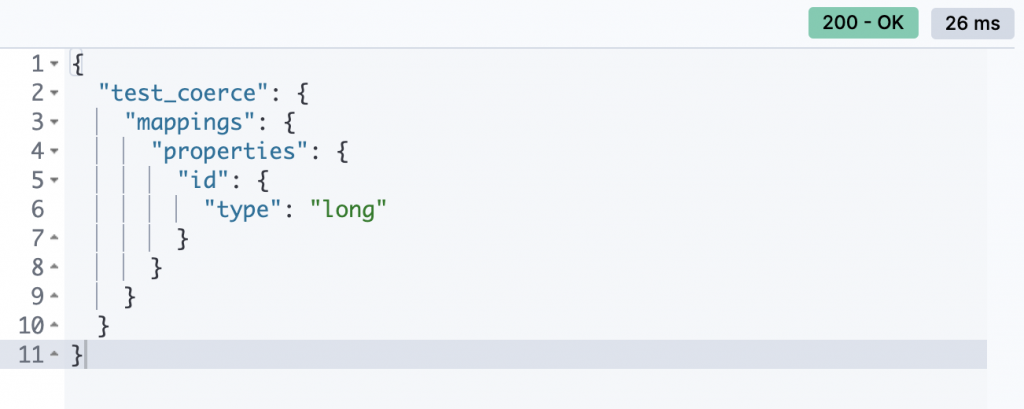
我們看到type是long,那我們輸入另外一個document試試看
PUT /test_coerce/_doc/2
{
"id": "2"
}

居然成功了~ 明明我們輸入的是字串
這就是coerce,如果欄位的mapping已經是long了
如果輸入的文檔中有這種髒數據,ES還是會藉由coerce將其轉換成欄位應該的映射
但是你去看_source當然還是字串的樣子,因為他是放原始數據
並且要注意,這樣的強制轉換,不是創建index時發生的
代表如果我一開始存
PUT /test_coerce/_doc/1
{
"id": "1"
}
id欄位的mapping如下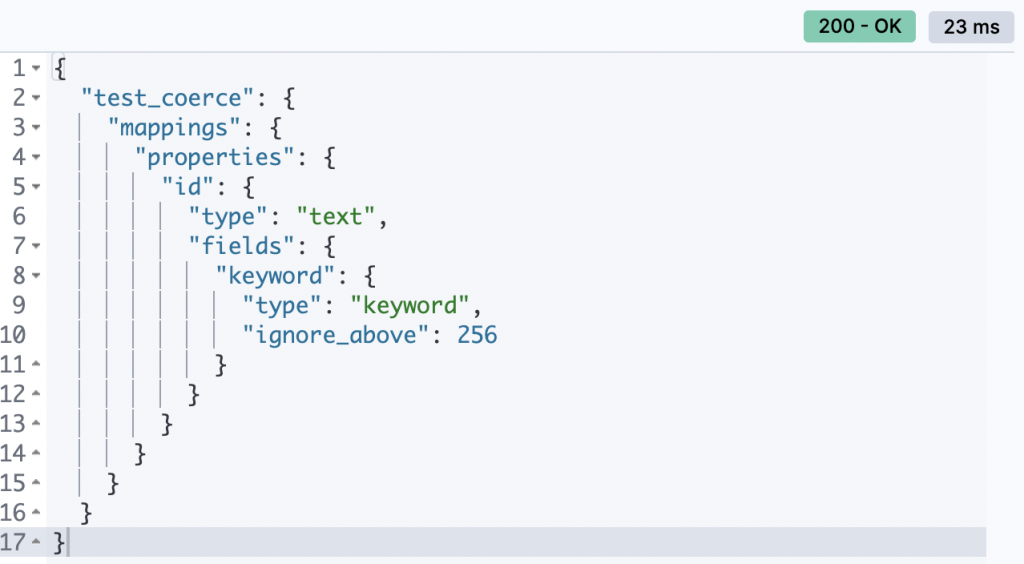
如果要關閉的話
PUT /test_coerce
{
"mappings": {
"properties": {
"id": {
"type": "keyword",
"coerce": false
}
}
}
}
index:
PUT /test_index
{
"mappings": {
"properties": {
"test_score": {
"type": "integer",
"index": false
}
}
}
}
index_option:
| 參數名稱 | 描述 |
|---|---|
| docs | 僅存doc number,代表該內容是否有在特定欄位中 |
| freqs | 除上面之外,還儲存出現的頻率。計算相關分數時,頻率越高分數越高 |
| positions | 除上面之外,還儲存位置與排序資料。對於proximity與phrase query有幫助(後面會介紹) |
| offsets | 會計算term的起始與結束的偏移量,幫助hightlighting |
以下為設置方法與示範offsets功能:
PUT /test_offset
{
"mappings": {
"properties": {
"text": {
"type": "text",
"index_options": "offsets" // 設置index_options
}
}
}
}
// 匯入文檔
PUT /test_offset/_doc/1
{
"text": "test offset function"
}
// 查詢該文檔
GET /test_offset/_search
{
"query": {
"match": {
"text": "test"
}
},
"highlight": {
"fields": {
"text": {}
}
}
}
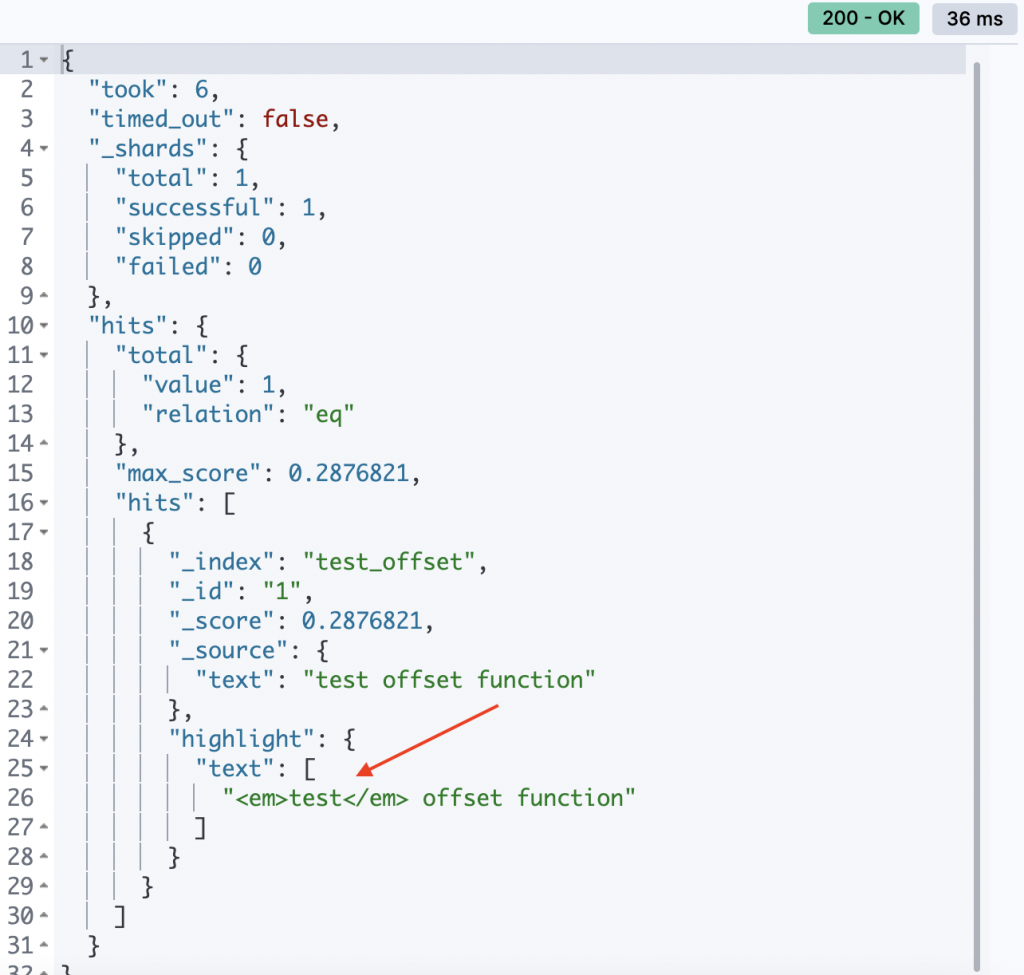
可以看到我們的查詢單字被強調顯示出來
doc_values:
PUT /test_doc_value
{
"mappings": {
"properties": {
"score": {
"type": "keyword",
"doc_values": false
}
}
}
}
norms:
"norms": false
null_value:
PUT /test_null
{
"mappings": {
"properties": {
"status_code": {
"type": "keyword",
"null_value": "NULL"
}
}
}
}
// 查詢方式
GET /test_null/_search
{
"query": {
"term": {
"status_code": "NULL"
}
}
}
接下來統整有關mapping的推薦設置:
今天大致介紹了在mapping時需要注意的參數設定
以及各種參數對於儲存優化的影響
至於更進階的管理方式,在生命週期的章節時會有更深入的介紹
明天會介紹mapping的最後一部分~Analyzer
參考資料
properties:https://www.elastic.co/guide/en/elasticsearch/reference/current/properties.html
format:
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-date-format.html
Dynamic field mapping:
https://www.elastic.co/guide/en/elasticsearch/reference/current/dynamic-field-mapping.html#dynamic-field-mapping
coerce:
https://www.elastic.co/guide/en/elasticsearch/reference/current/coerce.html
index:
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-index.html
index_option:
https://www.elastic.co/guide/en/elasticsearch/reference/current/index-options.html
doc_values:
https://www.elastic.co/guide/en/elasticsearch/reference/current/doc-values.html#
norms:
https://www.elastic.co/guide/en/elasticsearch/reference/current/norms.html
null_value:
https://www.elastic.co/guide/en/elasticsearch/reference/current/null-value.html

 iThome鐵人賽
iThome鐵人賽