2023 iThome 鐵人賽
分享至
接續前一天的部分~
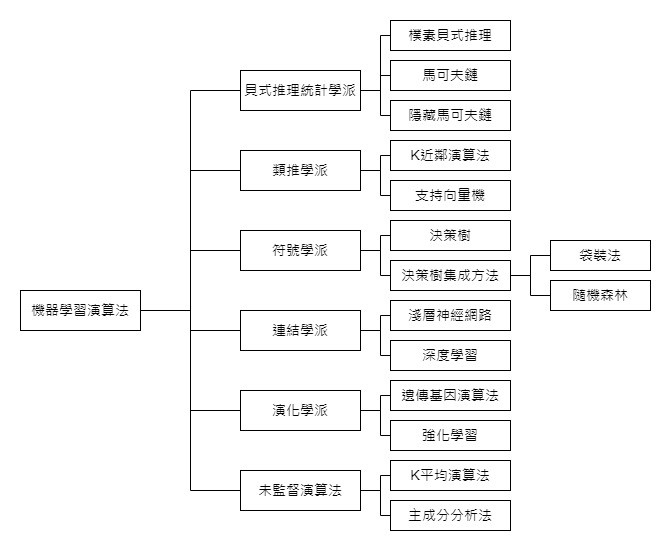
Pedro Domingos的演算法分類:
類推學派Analogical Reasoning:物以類聚的概念!用兩個物件間的相似性來作資訊分類判斷與分析。
K值是預測準確度的關鍵,但在選擇時是沒有依據的!(越大⇒可能包含到相關程度不高的樣本,越小⇒容易受到干擾)
符號學派Symbolism:重視因果關係法則。
參考來源:人工智慧:概念應用與管理 林東清
IT邦幫忙


 iThome鐵人賽
iThome鐵人賽