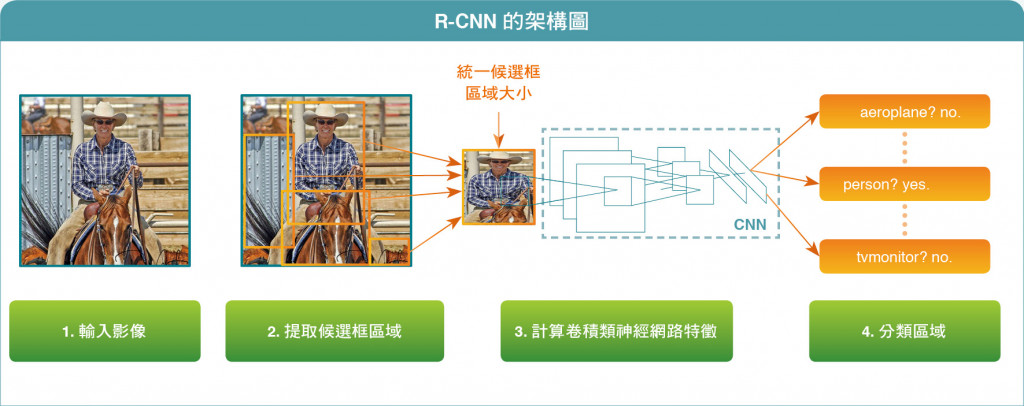
接續昨天說的OD的兩種主要模型。
一種OD演算法利用單一CNN,點對點可同時一次偵測一個圖像內是否有物件、其位置與大小。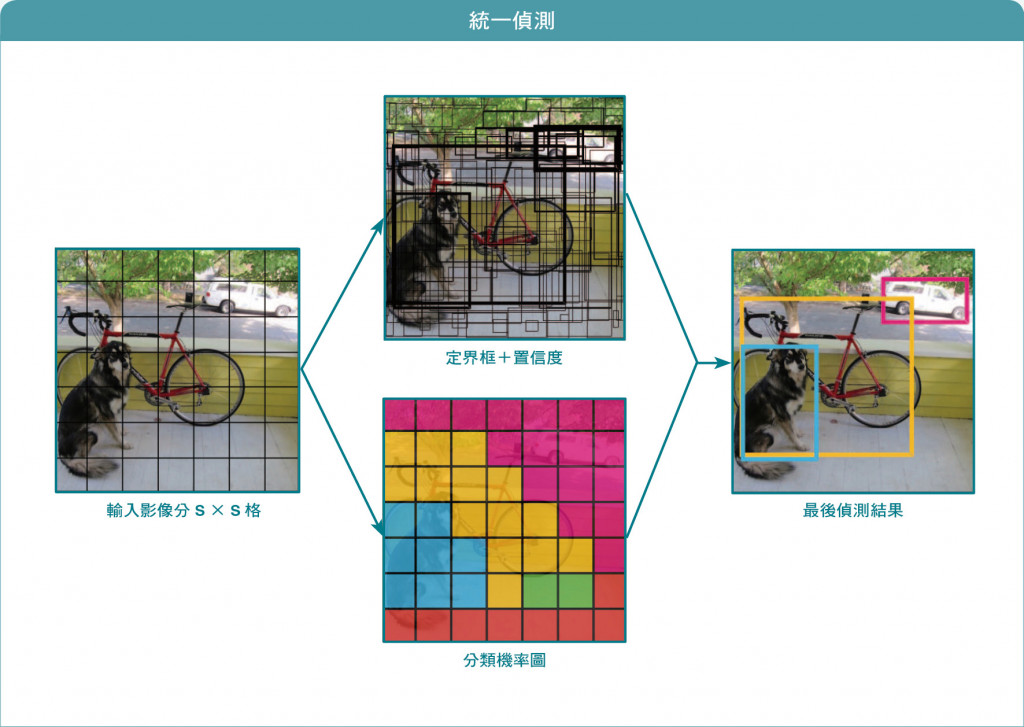
資料來源:https://scitechvista.nat.gov.tw/Article/C000003/detail?ID=b2b22689-9744-466c-a102-2fce20d7ab41
步驟:
①將整個圖像分割為SxS
②以CNN掃描所有格子,各個格子負責偵測自己內部是否有物件
③物件✅➜每個格子利用數個邊界框來試圖正確涵蓋所發現到的物件(此為不斷訓練學習,而預測出來的)
④利用交並集(Intersection Over Union,IOU)來選擇涵蓋正確率最高的預測邊界框:IOU(A,B)=((A∩B)/(A∪B))
IOU=1 ➜預測的邊界框與實際物件重疊率100%,完全涵蓋所要預測的物件
IOU=0.1 ➜預測的邊界框與實際物件重疊率10%,10%物件被涵蓋到而已
IOU必須大於0.5➜才會選擇來判斷物件的種類
⑤輸出位置、尺寸、分類與其為此分類的概率
參考來源:人工智慧:概念應用與管理 林東清


 iThome鐵人賽
iThome鐵人賽