輸入一段文字後,透過訓練學習與建立模型,將文字轉換成對應語音的技術。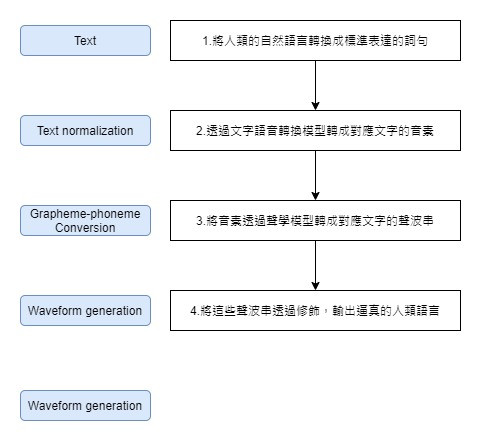
Google推出的此類系統:SV2TTS。
利用Speaker Encoder預先錄下特定人的語音,抽取其音訊特徵,接著整合至傳統文字語音網路,來一起完成並放入文字轉語音系統內,整合近兩個特徵直,再透過Wavenet,即可將輸入的文字透過這個特定人的聲音,輸出至TTS系統用在不同的應用上。
不過此系統若被不肖人士利用將會帶來負面影響,例如:詐騙集團用來模仿親人聲音或主管聲音作詐欺的事件。
架構圖: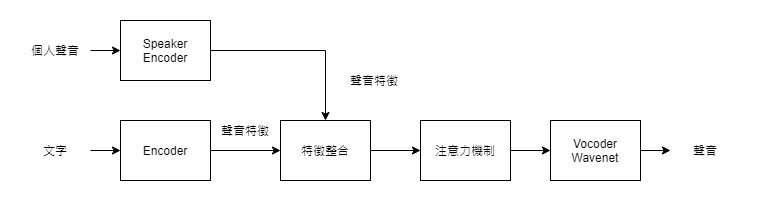
透過對圖像與影片分析處理,去識別偵測其內部有用的資訊來支援決策的技術。
核心應用分為:
參考來源:人工智慧:概念應用與管理 林東清


 iThome鐵人賽
iThome鐵人賽