今天來講 Flink 提供的 Web UI 有哪些功能,首先先看一下它的首頁
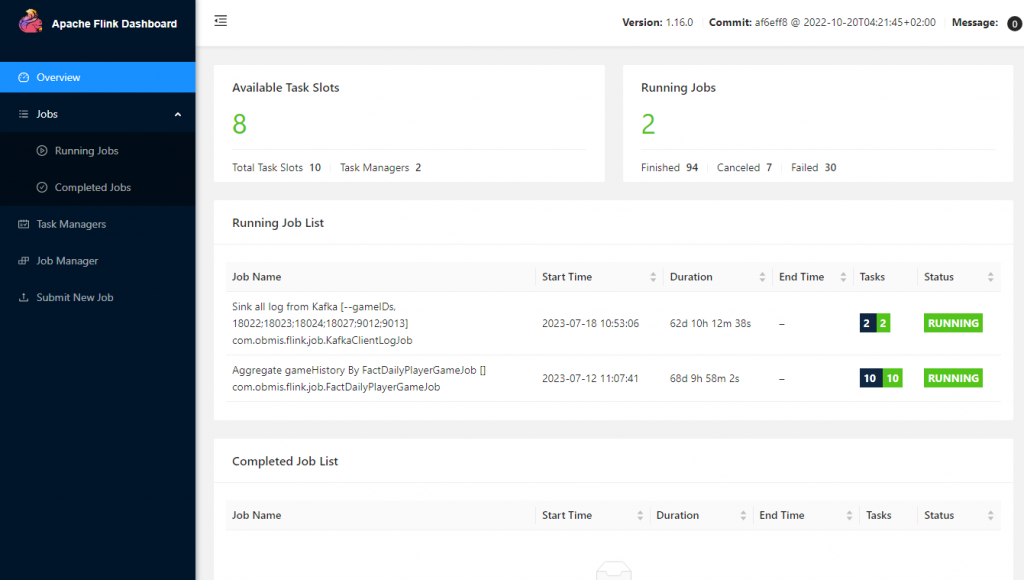
左邊有:
有幾個詞,要先解釋一下,你才好理解這些功能
就…一個工作,可以是 batch 也可以是 streaming,類似於 Airflow 的 DAG 層級
硬要翻的話,叫插槽,不過沒什麼意義,就還是叫 slot 吧。概念上就是可以執行幾個 job x 平行數量。我說過 Flink 也是有設計分佈式計算的,每個 Job 都是可以支援平行運算,但依賴於你有幾個 slot 跟設定要開幾個 pipeline。
通常是指主要的 master 節點,提供 Web UI 跟監控 Task
一般來說就是子節點 slave,會提供 slot。由於是分佈計算,你可以提供很多台 task 機器,依主機的性能決定要提供幾個 slot。一般來說,就是看 CPU core 數比較保險。
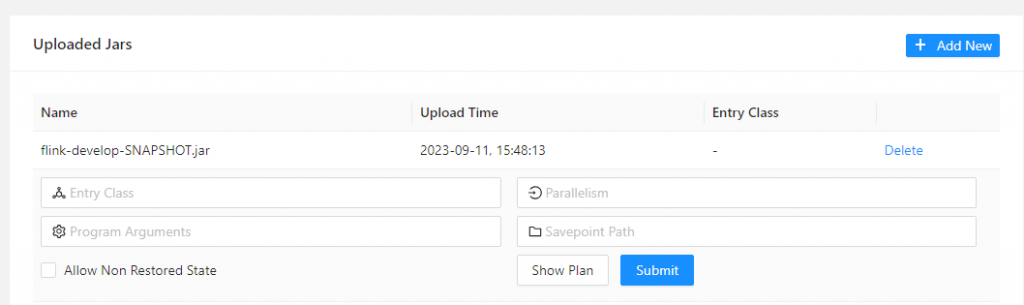
你要先按 Add New 來上傳一個 jar 檔,這個jar 檔內要包含你寫好的 flink 程式,最好是將依賴的 libs 一起打包起來。
像上圖中,就是已上傳一個 flink-develop-SNAPSHOT.jar
當我們上傳完,點了這個 jar 檔後,就可以再輸入一些參數
提供 job 的完整 package 新徑,像是 com.kk.my.package.ExampleJob
前面說的平行度,這個值預設會看設定檔,但你也可以在這裡設定。另外程式內也可以讀到這個值做調整。例如你可以寫死成 1,也可以設定是 2 倍於這個參數。
越高的平行度不代表越好,你有可能浪費你的 slot,但資料量其實一個 slot 就可以消化掉了。
一些參數,可以在這裡帶入程式中。我習慣上會在程式內讀取,並提供預設值。例如 TimeWindow 的時間,或是 batch 寫入的數量,或是 query 的起始時間等等。
存檔點,算是 Flink 很重要的機制之一。它會將執行到一半的 job 寫在 disk 內,當下次你要從這個存檔點復原時,只要輸入中斷時的存檔路徑即可。
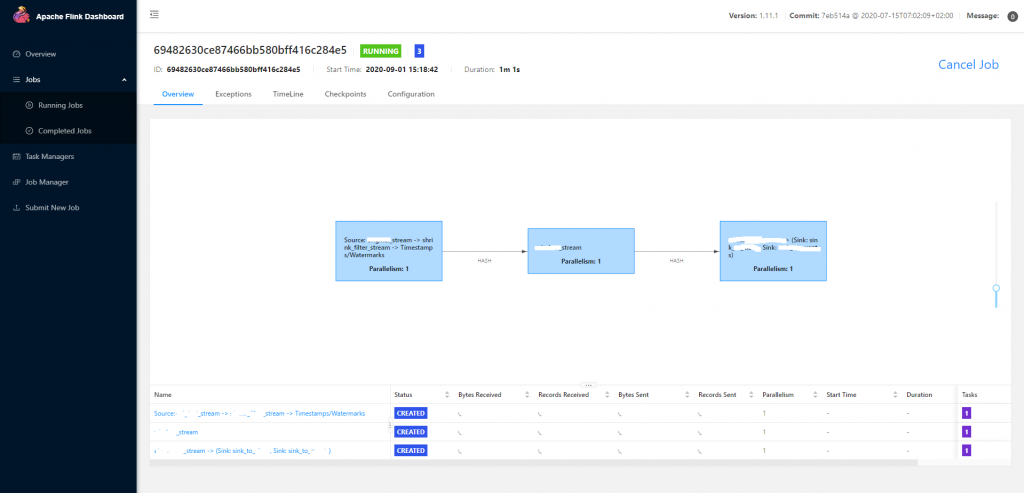
到這層就有點商業機密了,請容我使用網路上的圖片。
點開 Running Jobs 裡面正在運作的 job,就會看到上面這個畫面。類似於 DAG,job 內的 task 會顯示每個階段所做的事。預設你做的 N 件事如果是可以合併的話,會被收在一個 task 內,使用一個 slot。
在這層的意義,是要看資料卡在哪裡。有時候某些 task 處理不來上游的量,你就要在那個點多開一些 slot 來消化掉。
另外右上的 **Cancel Job** 要注意,它是「取消」而不是存檔。如果只點了「取消」,那麼連自動存檔的記錄點也會被刪掉。要保留 savepoint 必須另外下 command。
比較重要的應該就這些了,因為 Job Manager, Task Manager 都是用來看負載量比較多,常用的就上用講的這些了。

