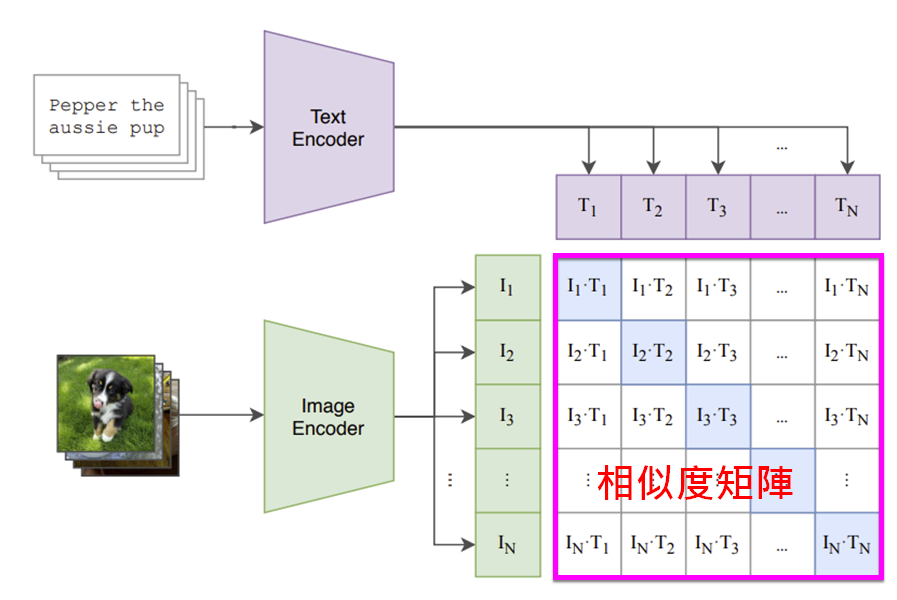
在CLIP裡,以矩陣運算來計算出相似度,並以矩陣來呈現,如下圖:
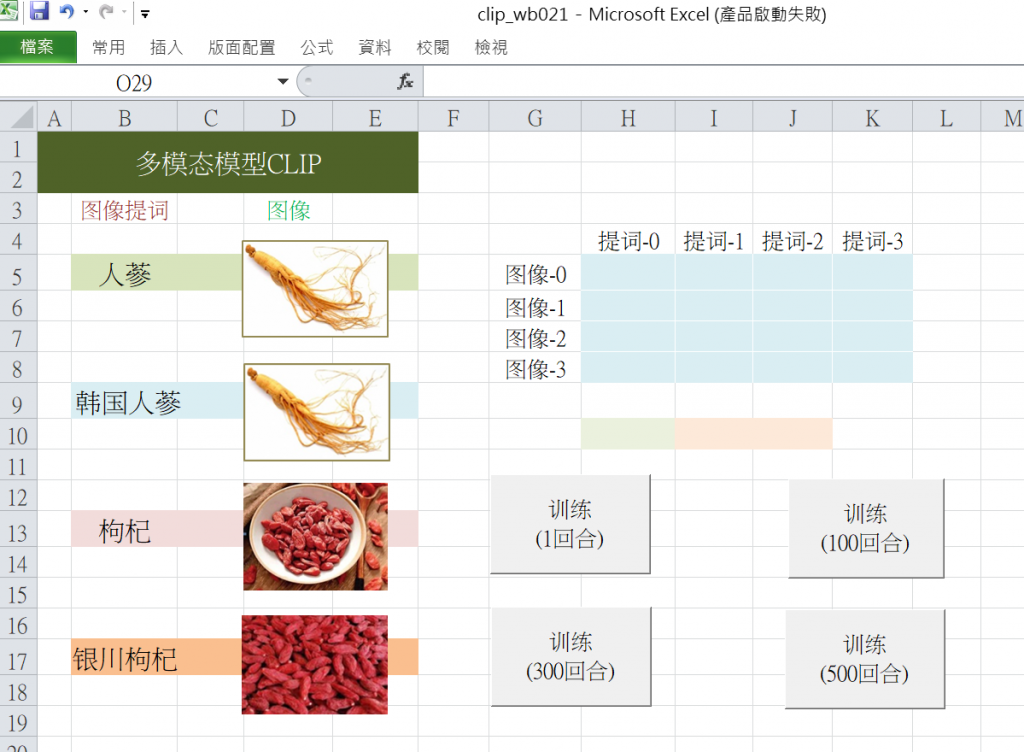
我們拿CLIP源代碼來實際進行訓練,在其過程中逐漸地修正CLIP模型裡的參數(即weight和bias值),也就是逐漸地調整潛藏空間裡各點的位置(座標),並以陣列運算來計算出各圖像與各文本之間的相似度。在本範例裡,我們把CLIP程式碼包裝於Excel後面,如下圖:
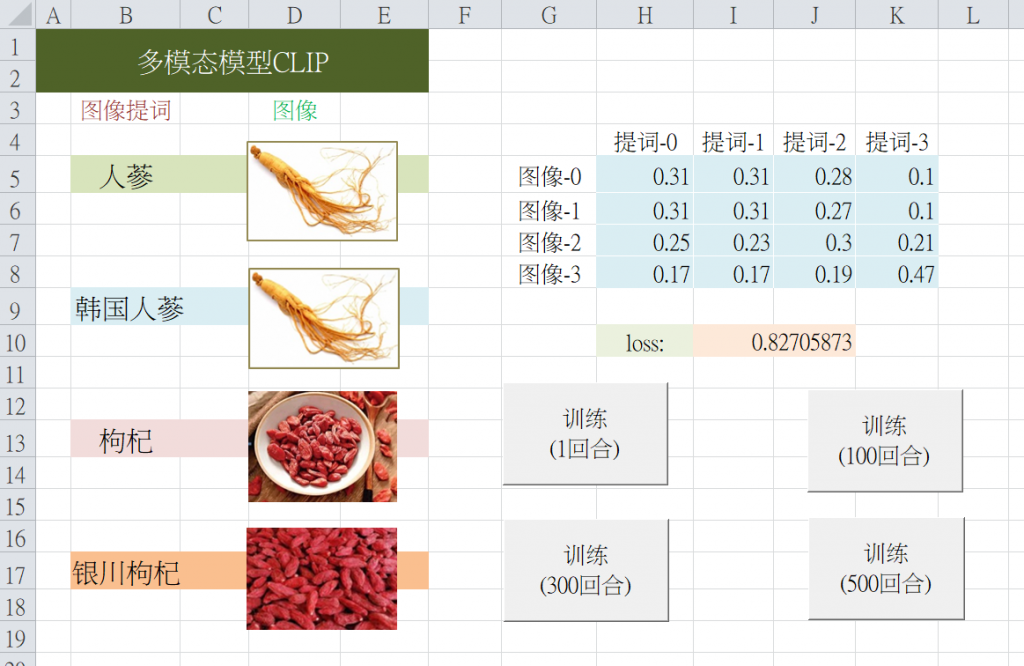
首先按下<訓練1回合>,就輸出各圖像與各文本之間的相似度,如下圖:

從上圖的相似度矩陣裡的值,還看不出來明顯的相似度差異。於是來加碼進行100回合訓練,完成之後,再以陣列呈現最新的相似度。如下圖:
上圖的相似度矩陣裡的值,仍然看不出來明顯的相似度差異。於是加碼進行300回合的訓練,完成之後,再以陣列呈現最新的相似度。如下圖:
這時從相似度矩陣已經可以看出來,明顯的相似度差異。例如,<圖像-3>與<提詞-3>相似度提高了。接著,再加碼進行500回合的訓練,完成之後,再以陣列呈現最新的相似度。如下圖:

這時從相似度矩陣可以更明顯地看出來其相似度的差異。例如,<圖像-2>與<提詞-2>相似度提高了。


 iThome鐵人賽
iThome鐵人賽