在 Kubernetes 的生態系中,我們獲得了前所未有的容器彈性,這大大助益於微服務的建構與複雜的容器編排。它為我們提供了一個強大且靈活的平台,使我們能夠快速響應並適應變動多端的需求。
然而,隨著服務越來越複雜,背後所需要的技術也變得更為精密和進階。僅僅有一個完善的容器化架構是不夠的,我們還需要更深入的技術來確保整個產品能夠安全無虞地在線上運行。這也是為什麼「可視化的三本柱」— 日誌 (Logging)、追踪 (Tracing) 以及指標 (Metrics) — 變得至關重要。它們不僅提供了系統的透明度,還使我們能夠迅速地定位、解決問題,確保提供最佳的使用體驗。
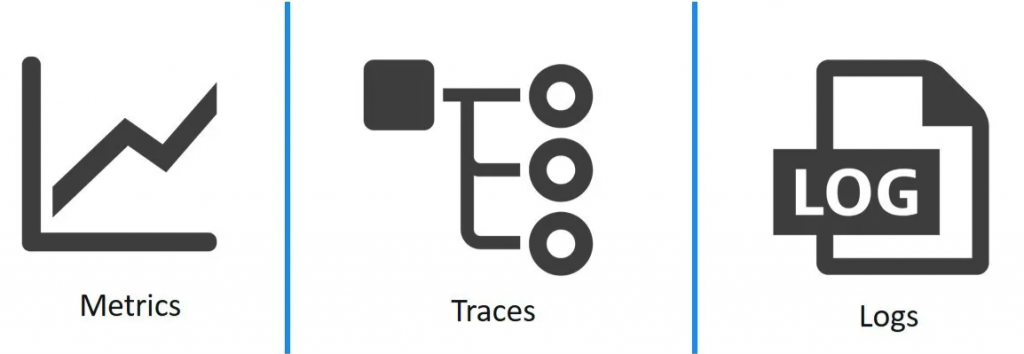
可觀測性三本柱定義為指日誌(logs)、指標(metrics)、追蹤(traces),都依賴於「事件(event)」的概念,也可以想成人們透過對事件的觀察,逐漸歸納出現代可觀測性的各種性質。
事件本質上是監控與遙測的基石,不論是已被定義的事件或是離散又獨特的事件,每個事件能有一些蛛絲馬跡來確認它曾經發生。通常我們會透過這些事件的上下文,來拼湊出事務的全貌,特別像在用戶之間的操作中,我們可以來回審視是否事件產生出來的上下文如同我們的預期,例如,一個用戶在瀏覽器中點擊「立即支付」的按鈕,那這按下「立即支付」按鈕的事件,是否如同我們的預期在理想中的 2 秒內,就跳轉到結帳成功的頁面。
可觀測性解決方案首先是追蹤在某個時間點發生的個體操作事件,在監控工具搜集的資訊下,系統管理員需要知道關於重大事件,包括潛在的風險以及系統當前狀況..等,這通常代表著:
像是當硬碟空間使用率已到達 90% 肯定是每個系統管理者腎上腺素激增的事件,但除了清除舊資料或加大空間的緊急應變之外,我們更多的是需要關於這些激增的資料量是來自哪一個應用服務,且是否為正常使用。
日誌是紀錄系統環境中發生的事件、警告、錯誤的文件,大多數的日誌都包含上下文訊息,例如事件發生的時間以及與之關聯的用戶或端點,他們很容易生成,並為我們提供有關我們關心的事件的詳細訊息,包括:
就讓我們觀察在一個實際情況下,用戶與系統交互溝通的行為:
有家咖啡店有個由各種組件組成的系統,其中一個就是收銀機,這時我們可以讓收銀機在每次進行金融交易時產生日誌。對於這些每筆交易的日誌,我們可以捕獲:
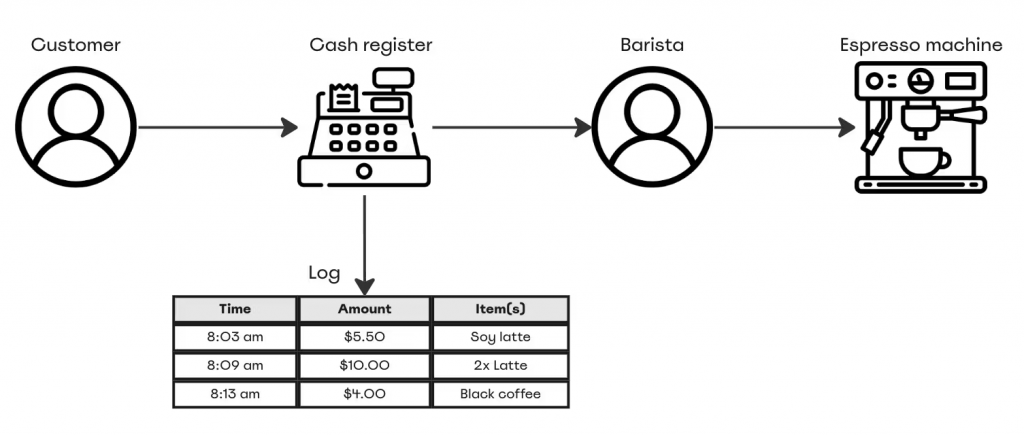
在這裡的收銀機就像是系統中的一個服務,運作的同時也產生出交易日誌,以便記錄紀錄已發生事件的詳細訊息,以便之後排查問題時參考。
指標是很具有實際量化意義的數值,可表示系統某一方面的健康狀況。在許多場景中,指標很直觀地收集 CPU、Memory 和硬碟使用率指標,都是直接與系統運行狀況相關的明顯自然指標。面對系統中成千上萬的指標事件,我們需要非常謹慎小心的去分析他們,這是一個專業領域,通常我們會使用許多工具來輔助我們判斷並且期望他適當發出告警,替我們爭取處理時間。
再回到咖啡店的比喻,假設每當成交時系統也同時發送了記錄著消費金額的指標,那現在我們想要計算我們在過去十分鐘內賺進的總金額。我們可以藉由此指標達成此操作。
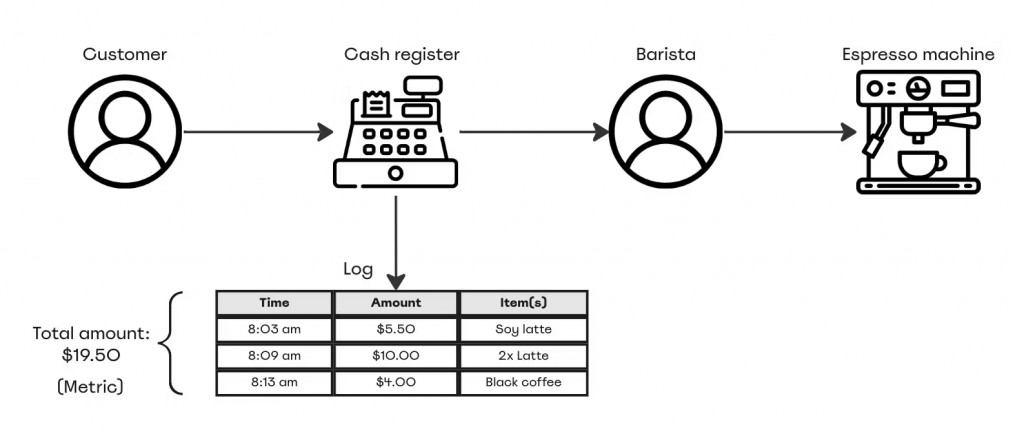
指標不只是能簡單的幫我們相加數值,還可以從多種維度讓我們了解系統在一個時間內的趨勢,像是每小時的客戶數量或者是每筆訂單所需要的平均時間。
追蹤資料是一個相對較新的概念,有鑒於近年來微服務的興起,使人們不得不尋找可以串連分佈式系統互動的解決方案。它有助於我們追蹤流轉在不同服務元件中的相關訊息,並且統一拼湊出完整的整個事件的過程,從而找到瓶頸所在,雖然他可能沒辦法告訴你系統異常的原因,但它可以幫助你縮小無數中個組件的故障範圍。
對於追蹤,我們可以從製作咖啡的咖啡師以及使用咖啡機的角度捕捉資訊。
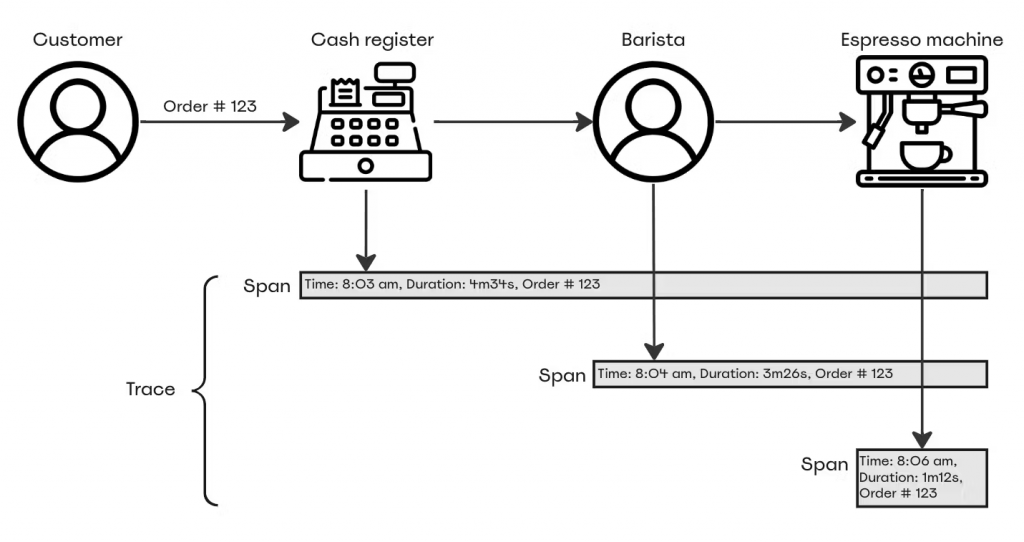
系統中的每個組件被捕捉的資訊稱為 Span(跨度),當我們組合出同一個追蹤的 Span 時,我們就得到了完整的分布式追蹤事件。其中有個串連起相關 Span 的關鍵辨識點,像是 trace id 或 parent id 等等。
在我們深入探討可觀測性的三本柱之後,我們可以清楚地看到它們各自的優缺點。每一柱都為我們提供了對系統運作的獨特視角,但也帶來了自己的挑戰。
這就是為什麼工具選擇如此關鍵。接下來要介紹的服務 Grafana 不僅僅是一個可視化工具,它也是一個綜合性的可觀測性平台。它的設計考慮到了這三本柱的獨特性質和挑戰,並嘗試通過一個統一的界面來解決它們。特別是,Grafana 在整合、分析和視覺呈現來自不同來源的數據時,從而幫助使用者輕鬆地跨越界限。
相關程式碼同步收錄在:
https://github.com/MikeHsu0618/grafana-stack-in-kubernetes/tree/main/day4
References
Metrics vs. Logs vs. Traces (vs. Profiles) - SquaredUp
The Three Pillars of Observability: Metrics, Logs and Traces
The 3 pillars of observability: Logs, metrics and traces | TechTarget


 iThome鐵人賽
iThome鐵人賽