在雲原生架構中,找出效能問題和不良的 CPU 使用率成了一個困難且極具挑戰性的過程。
隨著雲端環境越來越多元,使用者需要一種有效觀測手段,通常我們透過可觀測性三本柱:日誌(Loggs)、 指標(Metrics)、軌跡(Traces),來加強應用服務和基礎設施的穩定性及效率,雖然這三本柱能提供大量有用的資訊,但他們仍無法呈現出系統的全貌。
接下來我們將探討為何持續剖析(Continuous Profiling)成為了這兩三年間,開始在可觀測性領域被人關注的焦點。
可觀測性不僅用於監測,而是讓我們能夠深入了解整個應用系統,幫助開發者及維護者探索已知和未知的「為什麼」問題,通常他們需要對於系統有深度的理解以及一定的廣度知識,尤其是在未知領域的部分,這正是剖析(Profiles)的價值所在。雖然日誌、指標、軌跡都提供有價值的洞察,但剖析(Profiles)能看到更深的層面,如資料結構和代碼的能見度。如果今天視察看一個應用服務的當前狀態,他可以是 Running 或者是 Waiting 之一,此信息可能在其他可觀測性訊號中,無法看到性能瓶頸和資源使用模式,而剖析(Profiles)可以在這裡可以被視為單一主件內的 X光,負責便是那些發生在非常底層的問題,例如一個函數或程式碼路徑,甚至可以檢查和棄用未使用的代碼。
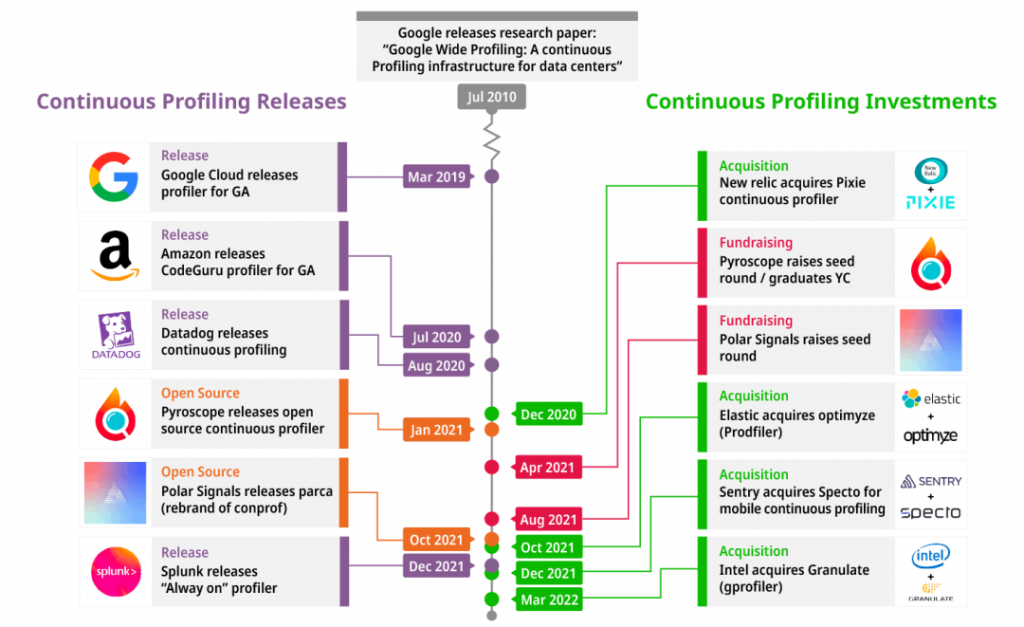
2010 年,Google 發表了一篇名為“Google-Wide Profiling的研究論文:
Google-Wide Profiling (GWP), a continuous profiling infrastructure for data centers, provides performance insights for cloud applications. With negligible overhead, GWP provides stable, accurate profiles and a datacenter-scale tool for traditional performance analyses.
可以看到自 2010年 Google 發表了論文後,直到了近幾年持續剖析領域才開始有了蓬勃生氣,多半是拜容器化、雲原生生態、Kubernetes 所賜,許多持續剖析服務也隨著其他技術領域的突破,逐漸完整了它的全貌。其中除了 Opentelemetry 這個統一遙測領域的公認標準之外,還有一項名為 eBPF 的 Linux 內核技術出現,使得它們成為了目前的熱門話題,eBPF 則是提供了一種非侵入式的方式,收集系統級別的資訊。
OpenTelemetry 社群在經過 KubeCon Europe 2022 的討論後,於2022 年 6 月成立了專門針對 Profiling 的 OpenTelemetry Profiling 工作團隊,而 Grafana 也在 2023 年三月收購了知名開源持續分析項目背後的公司 Pyrscope,並且和其去年推出的 Grafana Phlare 項目合併,並命名為 Grafana Pyrscope ,以展現 Grafana 想要將持續分析作為可觀測性的第四支柱的野心。
持續剖析(Continuous Profiling)可以拆成兩個部分來解讀:
持續剖析期望幫助開發者全面掌握與回朔生產環境中的執行細節,增強可觀測性。
持續剖析為我們的可觀測性加入了解資源使用情況直至定位代碼位置的能力,並且增強現已成熟的可觀測性遙測類型,讓我們看看接下來的幾個例子。
假如你的公司運營一個熱門購物商城,在某天你發現一個應用服務開始出現大量的錯誤日誌並且效能大幅降低,這時你將可以從日誌看出,問題出在哪個服務的哪個函式以及具體時間戳,但僅管我們知道錯誤發生在某個函式,卻不能知道影響效能的根本因素。
如果這時搭配了持續剖析,它能做到的是告訴你在該時間點上,哪個函式或線程佔據了資料庫的大量資源,導致查詢時間變長,解決方案可能是優化該資料庫查詢,或者是調整功能邏輯減少對資料庫的壓力。
當我們透過 Prometheus 監控資料庫性能並偵測到延遲的突增,我們可以使用與 Prometheus 相同的標籤系統取得特定時間範圍的 CPU 剖析資料。
此舉能幫我們直觀地看到應用中的 CPU 使用情況,並且精確到每行代碼。
為了使軌跡更為精準,每次調用函式時,都附上該函數的元數據。因此,當你在檢查請求軌跡時,看到某個執行時間過長的 Span,就可以透過剖析來深入探查該函式的具體行為。
更進一步,你也可以在整個環境中,跨多個集群(例如所有 API 伺服器)來觀察這個函數的表現,因為我們不只在特定的節點或機器上收集分析資料,而是持續地在整體環境中收集。
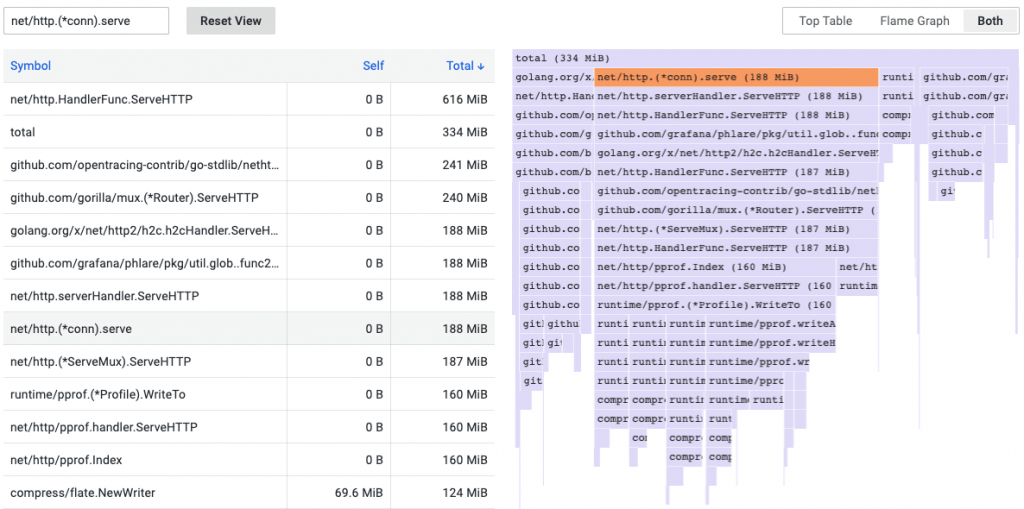
性能剖析的可視化形式通常是以 Flame Graph 火焰圖來表達,通過火焰圖,我們可以知道哪些函式消耗系統中最多的資源。可以看到調用堆棧的層次結構,然後可以使用它來深入了解執行時間最長的系統區域。
我們都已經習慣了日誌、指標和軌跡作為可觀測性三本柱,他們都是非常重要的遙測訊號,但他們就足以代表可觀測性的全部嗎?一點也不,雖然這三個支柱仍然至關重要,但重要的是不要受到三大支柱制式的限制,我們必須根據自己的需求選擇正確的遙測數據。以我自己的話來說:真正的可觀測性就是超越原本的可觀測性。
相關程式碼同步收錄在:
https://github.com/MikeHsu0618/grafana-stack-in-kubernetes/tree/main/day5
References
Continuous profiling now in public preview in Grafana Cloud | Grafana Labs
Observability 3 本柱+Profile 打造完整可觀測性解決方案 - 歐立威科技
The Three Pillars of Observability: Metrics, Logs and Traces
Metrics vs. Logs vs. Traces (vs. Profiles) - SquaredUp
Observability 3 本柱+Profile 打造完整可觀測性解決方案 - 歐立威科技
eBPF Profiling | Open Source Continuous Profiling Platform


 iThome鐵人賽
iThome鐵人賽