在前幾天的內容當中,我們陸續介紹了 Data pipeline、Data pipeline 的種類、資料處理,資料品質等主題,相信大家對於 Data pipeline 以及資料的處理都有基本的認知了吧!非常好,那我們接下來就可以在這基礎之上來進一步探討如何來去設計實作 Data pipeline。
在建立 Data pipeline 時,首先要清楚這一條 Data pipeline 的用途及目的,以確保我們設計的 Data pipeline 最能達成這目的。其中有幾個部分需要事先了解:
瞭解了這些重要的問題之後,接下來我們可以進入流程設計的步驟。
了解了需求之後,我們可以首先透過一些常見流程思考看看,自己的面臨的需求是哪一種情景,是否有適合使用的Data pipeline 架構,什麼?忘記有哪些架構了嗎?可以再回去翻一翻本系列第七天的『Data pipeline的種類』。如果 Data pipeline 是需要即時的資料顯示,甚至是狀態廣播,像是物聯網系統的狀態警示功能,就不太適合使用 Batch 屬性的 Data pipeline,需要使用 Streaming Data pipeline 的架構進行設計。如果是像是檔案類型的定期資料更新,則可以用 Batch 類型的 Data pipeline 架構進行設計。
如同我們在之前所提到的,現代的資料工程師,和以前的資料工程師任務上有不同之處,其中之一在於,現在不太需要從底層打造很大架構的大數據系統,更多會碰到的情景是如何選用正確的工具。在我們設計規劃好基本流程之後,我們針對情景選用相對應的工具,提供一些大方向的選型供大家思考:
開源或是公司私有的服務各有其優缺點。開源的軟體基本上不需負擔過多的費用,但是需要花費工程師的時間和精力進行部署和修改。而私有的服務,通常支付費用後會有相關人員進行輔助。可以根據團隊的人力,金費,時間進行選用的評估。
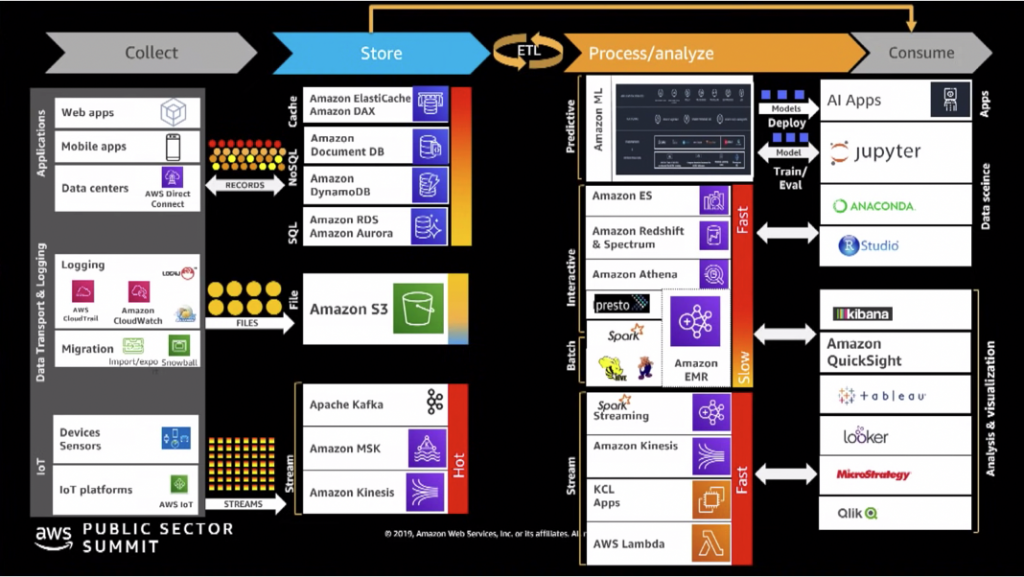
如同Data pipeline的種類的內容所提到的,Batch 以及 Streaming 所使用的情景不盡相同,使用工具時會對應相對情形選用適合的服務。常見的 Batch 工具包含 Apache Airflow, AWS StepFunction等等。而常用於 Streaming 的相關工具為 Apache Kafka, Amazon Kinesis 等等工具。
AIMultiple 也對於相關領域的工具做了基本的分類: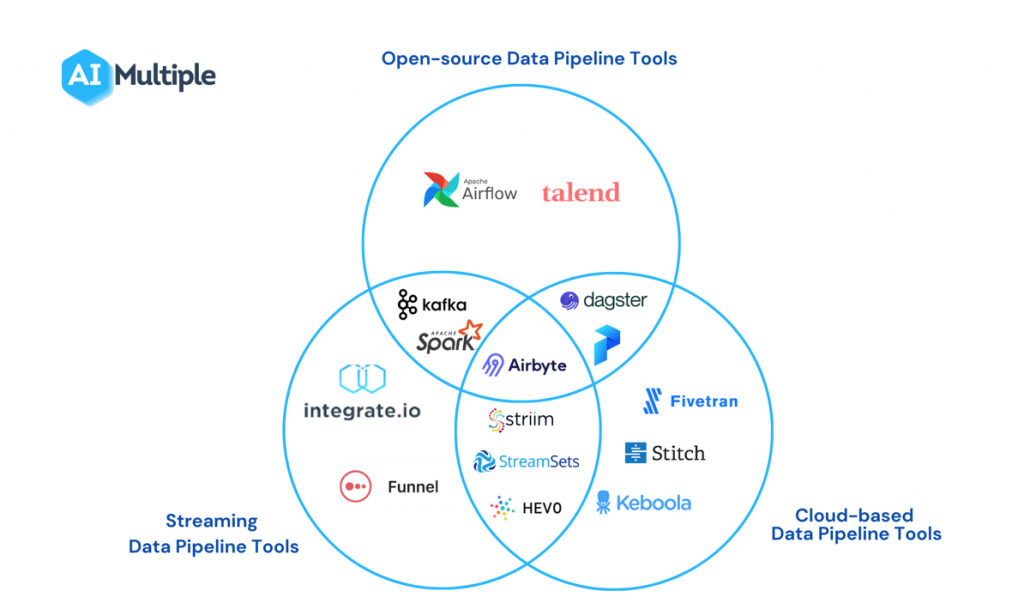
圖片來源:https://research.aimultiple.com/data-pipeline-tools/
了解了各種工具的屬性之後,最重要的是我們如何整合這些工具建立最適用的Data pipeline。
有了基本的設計規劃和選定相關工具,預備好一個開放的內心之後,馬上就可以開始時做我們的 Data pipeline 了!本系列到目前為止,對於資料相關生態知識以及Data pipeline做了基本的介紹。由於資料的生態系實在是過於龐大,無法在有限的篇幅當中一一的介紹,因此我們會選定 Apache Airflow 作為開發工具。透過了解這個工具的設計以及開發流程,讓我們對於Data pipeline相關的開發概念能夠有基本的認知,如此就算未來使用不同的工具,但能把所學習的過程轉化成智慧經驗持續使用。

