昨天我們使用了image search跟gif search這兩個plugin來搜尋圖片跟GIF,但是搜尋結果有時候差強人意,這個時候就來試試自己做圖片吧!今天要使用Michelangelo和其他插件來帶大家認識OpenAI的另一個強項:Dall-E模型。
DALL-E和DALL-E 2是由OpenAI使用深度學習方法開發的文本到圖像模型。這些模型能夠根據prompts生成數字圖像。DALL-E最初於2021年1月公開,並使用了一個修改過的GPT-3版本來生成圖像。2022年4月,OpenAI宣布了DALL-E 2並於2022年7月20日進入了beta階段。此外DALL-E 2也作為API發布,允許開發者將模型集成到他們自己的應用程序中。(API部分將會在最後五天解說)

Edit、Variations、Share和Save,後面兩個選項應該不用多說,就稍微解釋前面兩個好了。

Generate,消耗一點credits它又會給你四張圖片(包括原圖共五張)
與Edit不同的是,Variations會直接以這張圖片的風格元素重新再給你四張(同樣包括原圖共五張)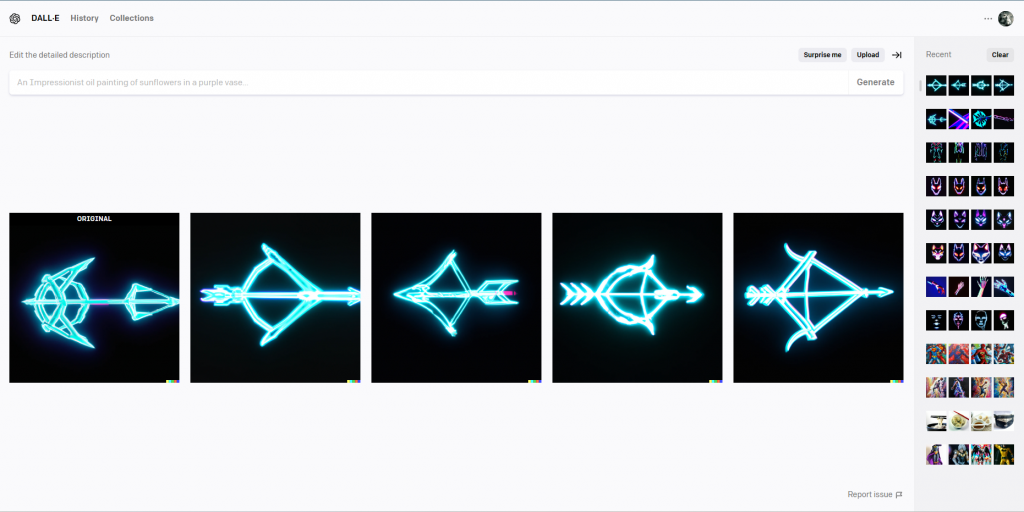
旁邊的歷史紀錄可以看到我其實試了很多不同主題,對於他的生成圖片能力我只能說時好時壞,可能是因為我不會下文生圖的prompts或是官網的可調選項比較有限制,所以我是不推薦花這15美,或是可以使用接下來要介紹的插件玩玩看再決定。
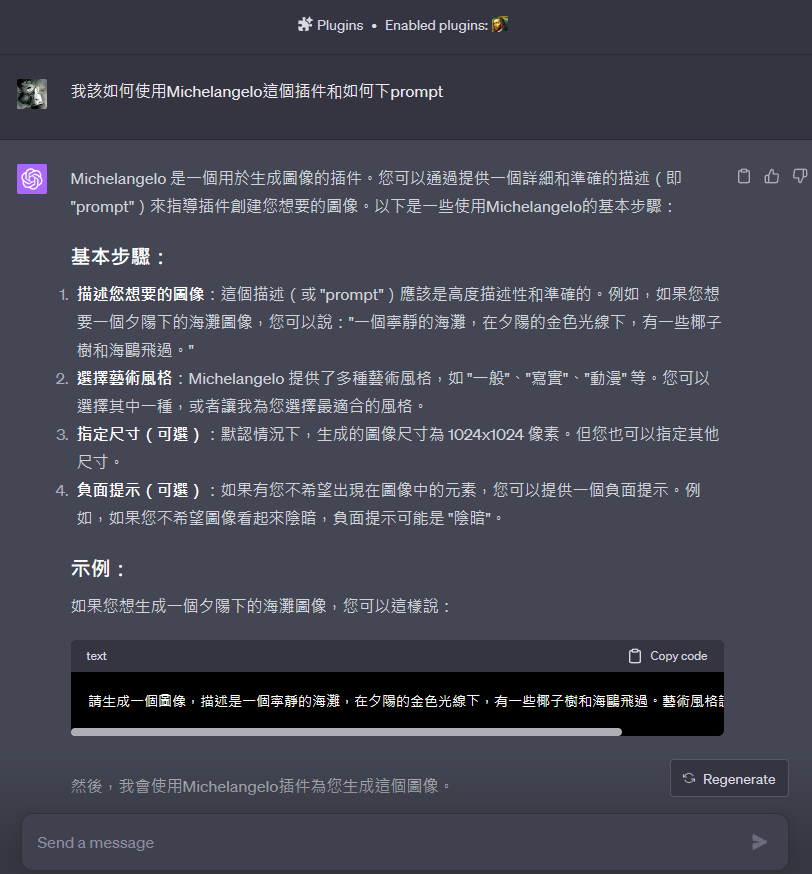


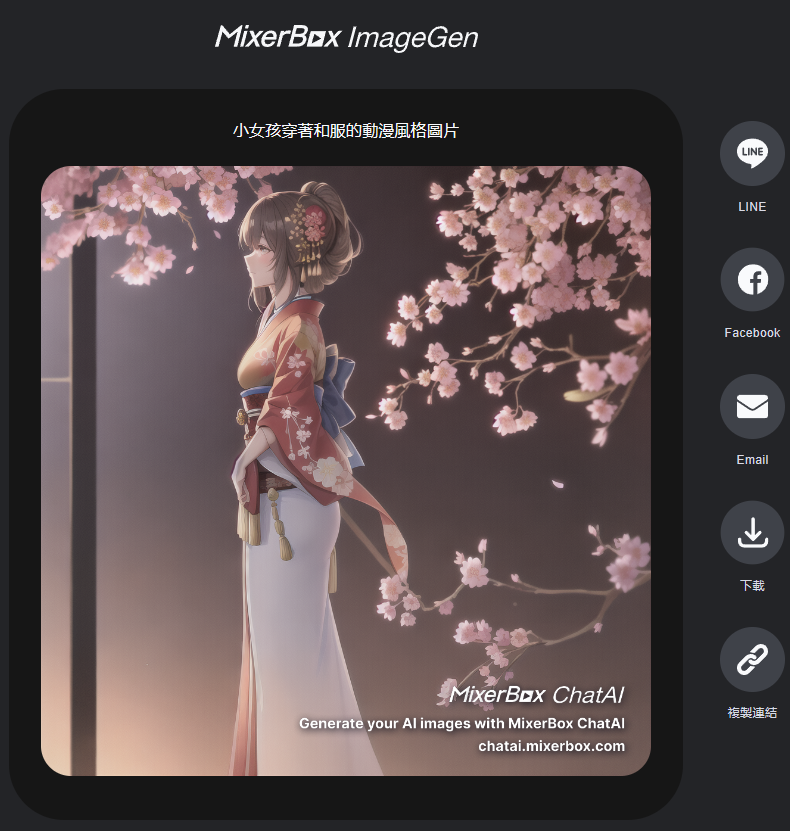
今天除了介紹OpenAI自家的DALL-E以外還玩了兩個插件Michelangelo和MixerBox ImageGen,效果其實都不錯,但就是讓我感覺到文生圖的prompts精準度必須比平常使用ChatGPT高,否則就會生出一堆四不像的怪物。以後有機會再來介紹我曾經玩過的Midjourny和Stable Diffusion,有興趣當然也歡迎大家自行研究,然後跟我們分享哦~

