在講同源政策 same-origin policy 時,我有提到瀏覽器基本上會阻止一個網站讀取另一個不同來源的網站的資料,可是在開發的時候,前端跟後端可能不是在同一個 origin,或許一個在 huli.tw,另一個在 api.huli.tw,那這樣前端該怎麼讀到後端的資料呢?
這就是 CORS 出場的時候了,全名為 Cross-Origin Resource Sharing,是一種可以跨來源交換網站資料的機制。這個機制在開發中很常用到,而對駭客而言,如果機制設定錯誤的話,就變成了一個資安漏洞。
要理解為什麼會有 CORS,就要從為什麼瀏覽器要阻擋跨來源呼叫 API 開始。
話說這個定義有點不清楚,更精確一點的說法是:「為什麼不能用 XMLHttpRequest 或是 fetch(或也可以簡單稱作 AJAX)獲取跨來源的資源?」
會特別講這個更精確的定義,是因為去拿一個「跨來源的資源」其實很常見,例如說 <img src="https://another-domain.com/bg.png" />,這其實就是跨來源去抓取資源,只是這邊我們抓取的目標是圖片而已。
或者是:<script src="https://another-domain.com/script.js" />,這也是跨來源請求,去抓一個 JavaScript 檔案回來並且執行。
但以上兩種狀況你有碰到過問題嗎?基本上應該都沒有,而且已經用得很習慣了,完全沒有想到可能會出問題。
那為什麼變成 AJAX,變成用 XMLHttpRequest 或是 fetch 的時候就不同了?為什麼這時候跨來源的請求就會被擋住?(這邊的說法其實不太精確,之後會詳細解釋)
要理解這個問題,其實要反過來想。因為已經知道「結果」就是會被擋住,既然結果是這樣,那一定有它的原因,可是原因是什麼呢?這有點像是反證法一樣,想要證明一個東西 A,就先假設 A 是錯的,然後找出反例發現矛盾,就能證明 A 是對的。
要思考這種技術相關問題時也可以採取類似的策略,先假設「擋住跨來源請求」是錯的,是沒有意義的,再來如果發現矛盾,發現其實是必要的,就知道為什麼要擋住跨來源請求了。
因此,可以思考底下這個問題:
如果跨來源請求不會被擋住,會發生什麼事?
那我就可以自由自在串 API,不用在那邊 google 找 CORS 的解法了!聽起來好像沒什麼問題,憑什麼 <img> 跟 <script> 標籤都可以,但 AJAX 卻不行呢?
如果跨來源的 AJAX 不會被擋的話,那我就可以在我的網域的網頁(假設是 https://huli.tw/index.html),用 AJAX 去拿 https://google.com的資料對吧?
看起來好像沒什麼問題,只是拿 Google 首頁的 HTML 而已,沒什麼大不了。
但如果今天我恰好知道你們公司有一個「內部」的公開網站,網址叫做 http://internal.good-company.com,這是外部連不進去的,只有公司員工的電腦可以連的到,然後我在我的網頁寫一段 AJAX 去拿它的資料,是不是就可以拿得到網站內容?那我拿到以後是不是就可以傳回我的 server?
這樣就有了安全性的問題,因為攻擊者可以拿到一些機密資料。
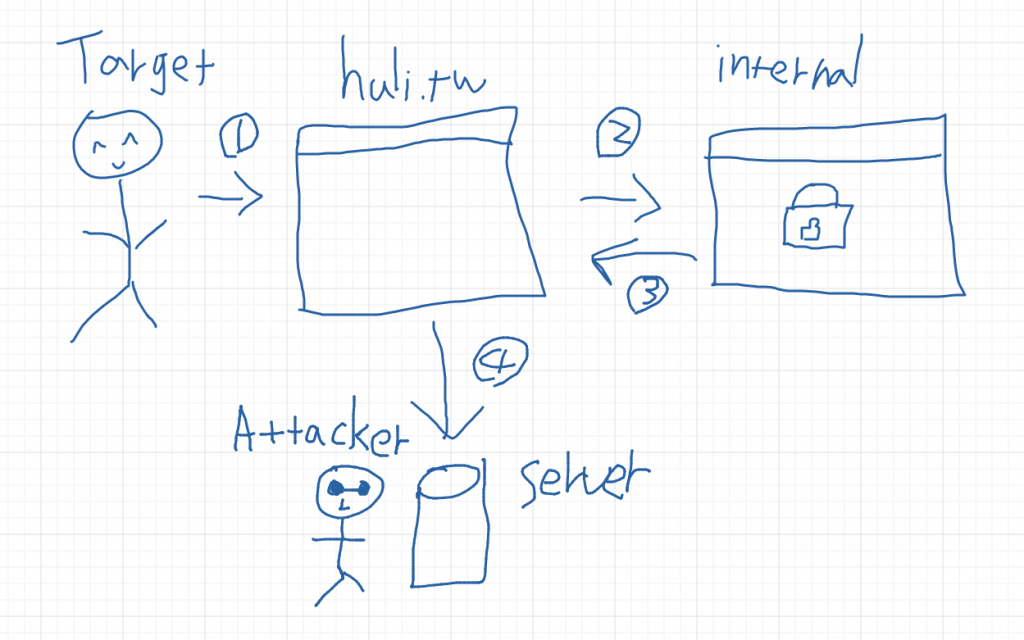
你可能會問說:「可是要用這招,攻擊者也要知道你內部網站的網址是什麼,太難了吧!」
如果你覺得這樣太難,那我換個例子。
許多人平常在開發的時候,都會在自己電腦開一個 server,網址有可能是 http://localhost:3000 或是 http://localhost:5566 之類的。以現代前端開發來說,這再常見不過了。
如果瀏覽器沒有擋跨來源的 API,那我就可以寫一段這樣的程式碼:
// 發出 request 得到資料
function sendRequest(url, callback) {
const request = new XMLHttpRequest();
request.open('GET', url, true);
request.onload = function() {
callback(this.response);
}
request.send();
}
// 嘗試針對每一個 port 拿資料,拿到就送回去我的 server
for (let port = 80; port < 10000; port++) {
sendRequest('http://localhost:' + port, data => {
// 把資料送回我的 server
})
}
如此一來,只要你有跑在 localhost 的 server,我就可以拿到內容,進而得知你在開發的東西。在工作上,這有可能就是公司機密了,或是攻擊者可以藉由分析這些網站找出漏洞,然後用類似的方法打進來。
再者,如果你覺得以上兩招都不可行,在這邊我們再多一個假設。除了假設跨來源請求不會被擋以外,也假設「跨來源請求會自動附上 cookie」。
所以如果我發一個 request 到 https://www.facebook.com/messages/t,就可以看到你的聊天訊息,發 request 到 https://mail.google.com/mail/u/0/,就可以看到你的私人信件。
講到這邊,應該可以理解為什麼要擋住跨來源的 AJAX 了,說穿了就是三個字:「安全性」。
在瀏覽器上,如果想拿到一個網站的完整內容(可以完整讀取),基本上就只能透過 XMLHttpRequest 或是 fetch。若是這些跨來源的 AJAX 沒有限制的話,就可以透過使用者的瀏覽器,拿到「任意網站」的內容,包含了各種可能有敏感資訊的網站。
因此瀏覽器會擋跨來源的 AJAX 是十分合理的一件事,就是為了安全性。
這時候有些人可能會有個疑問:「那為什麼圖片、CSS 或是 script 不擋?」
因為這些比較像是「網頁資源的一部分」,例如說我想要用別人的圖片,我就用 <img> 來引入,想要用 CSS 就用 <link href="...">,這些標籤可以拿到的資源是有限制的。再者,這些取得回來的資源,我沒辦法用程式去讀取它,這很重要。
我載入圖片之後它就真的只是張圖片,只有瀏覽器知道圖片的內容,我不會知道,我也沒有辦法用程式去讀取它。既然沒辦法用程式去讀取它,那也沒辦法把拿到的結果傳到其他地方,就比較不會有資料外洩的問題。
想要正確認識跨來源請求,第一步就是認識「為什麼瀏覽器要把這些擋住」,而第二步,就是對於「怎麼個擋法」有正確的認知。底下我準備了小測驗,大家可以試著回答看看。
小明正在做的專案需要串接 API,而公司內部有一個 API 是拿來刪除文章的,只要把文章 id 用 POST 以 application/x-www-form-urlencoded 的 content type 帶過去即可刪除。
舉例來說:POST https://lidemy.com/deletePost 並帶上 id=13,就會刪除 id 是 13 的文章(後端沒有做任何權限檢查)。
公司前後端的網域是不同的,而且後端並沒有加上 CORS 的 header,因此小明認為前端用 AJAX 會受到同源政策的限制,request 根本發不出去。
而實際上呼叫以後,果然 console 也出現:「request has been blocked by CORS policy: No 'Access-Control-Allow-Origin' header is present on the requested resource」 的錯誤。
所以小明認為前端沒辦法利用 AJAX 呼叫這個 API 刪除文章,文章是刪不掉的。
請問小明的說法是正確的嗎?如果錯誤,請指出錯誤的地方。
這題在考的觀念是:
跨來源請求被瀏覽器擋住,實際上到底是什麼意思?是怎麼被擋掉的?
會有這一題,是因為有很多人認為:「跨來源請求擋住的是 request」,因此在小明的例子中,request 被瀏覽器擋住,沒辦法抵達伺服器,所以資料刪不掉。
但這個說法其實想一下就知道有問題,看錯誤訊息就知道了:
request has been blocked by CORS policy: No 'Access-Control-Allow-Origin' header is present on the requested resource
瀏覽器說沒有那個 header 存在,就代表什麼?代表它已經幫你把 request 發出去,而且拿到 response 了,才會知道沒有 Access-Control-Allow-Origin 的 header 存在。
所以瀏覽器擋住的不是 request,而是 response,這一點超級重要。
你的 request 已經抵達伺服器,伺服器也回傳 response 了,只是瀏覽器不把結果給你而已。
所以這題的答案是,儘管小明看到這個 CORS 的錯誤,但因為 request 其實已經發到 server 去了,所以文章有被刪掉,只是小明拿不到 response 而已。對,相信我,文章被刪掉了,真的。
這點是完全符合規格的,不過許多人搞不清楚,甚至也有人以為這是安全性問題去 Chromium 回報:
但結果都是一樣的,被標記為「不會修」,因為是符合規範的實作。
最後再補充一個滿多人搞不清楚的觀念。
前面有講說擋 CORS 是為了安全性,如果沒有擋的話,那攻擊者可以利用 AJAX 去拿內網的非公開資料,公司機密就外洩了。而這邊我又說「脫離瀏覽器就沒有 CORS 問題」,那不就代表就算有 CORS 擋住,我還是可以自己發 request 去同一個網站拿資料嗎?難道這樣就沒有安全性問題嗎?
舉例來說,我自己用 curl 或是 Postman 或任何工具,應該就能不被 CORS 限制住了不是嗎?
會這樣想的人忽略了一個特點,這兩種有一個根本性的差異。
假設今天我們的目標是某個公司的內網,網址是:http://internal.good-company.com
如果我直接從我電腦上透過 curl 發 request,我只會看到錯誤畫面,因為一來我不是在那間公司的內網所以沒有權限,二來我甚至連這個 domain 都有可能連不到,因為只有內網可以解析。
而 CORS 是:「我寫了一個網站,讓內網使用者去開這個網站,並且發送 request 去拿資料」。這兩者最大的區別是「是從誰的電腦造訪網站」,前者是我自己,後者則是透過其他人(而且是可以連到內網的人)。
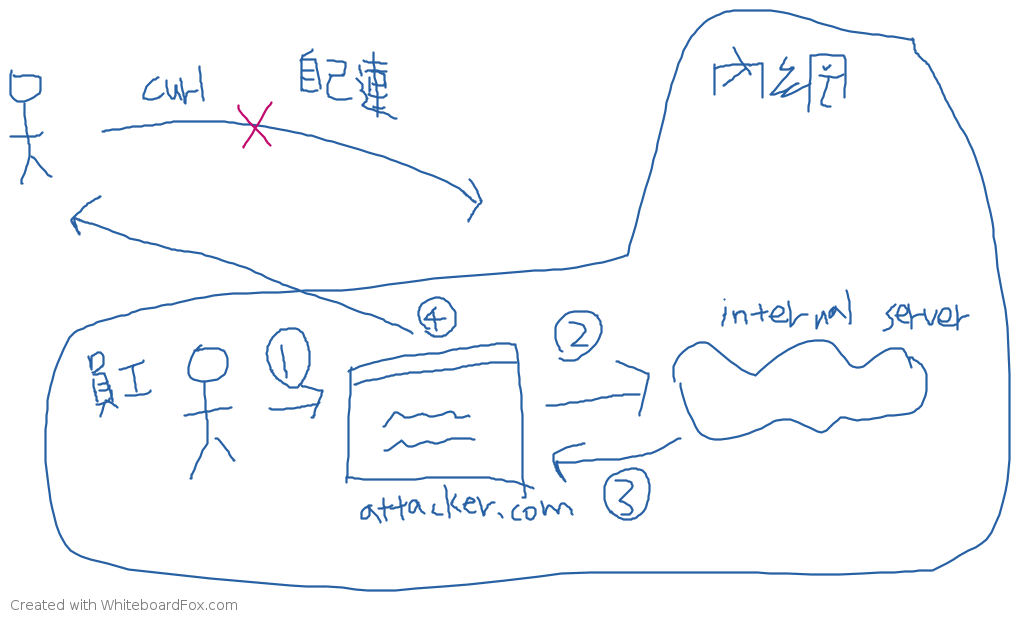
如圖所示,上半部是攻擊者自己去連那個網址,會連不進去,因為攻擊目標在內網裡。所以儘管沒有 same-origin policy,攻擊者依然拿不到想要的東西。
而下半部則是攻擊者寫了一個惡意網站,並且想辦法讓使用者去造訪那個網站,像是標 1 的那邊,當使用者造訪網站之後,就是 2 的流程,會用 AJAX 發 request 到攻擊目標(internal server),3 拿完資料以後,就是步驟 4 回傳到攻擊者這邊。
有了 same-origin policy 的保護,步驟 4 就不會成立,因為 JavaScript 拿不到 fetch 的結果,所以不會知道 response 是什麼。
講完了原理,知道為什麼瀏覽器要阻止跨來源請求以後,就可以來談談該如何設置 CORS 了。設置的方式很簡單,既然瀏覽器是為了資安的目的在做保護,只要跟瀏覽器說:「我允許 xxx 存取這個請求的 response」就行了,內容如下:
Access-Control-Allow-Origin: *
這個 response header 代表「允許任何 origin 讀取這個 response」,如果想要限制單一來源的話,就是這樣寫:
Access-Control-Allow-Origin: https://blog.huli.tw
那如果想要多個怎麼辦?以目前來說做不到,這個的值並不支援多個 origin,只能在伺服器做處理,根據 request 的不同動態輸出不同的 header。
另外,跨來源請求還分成兩種「簡單請求」跟「非簡單請求」,無論是哪一種,後端都需要給 Access-Control-Allow-Origin 這個 header。而最大的差別在於非簡單請求在發送正式的 request 之前,會先發送一個 preflight request,如果 preflight 沒有通過,是不會發出正式的 request 的。
針對 preflight request,我們也必須給 Access-Control-Allow-Origin 這個 header 才能通過。
除此之外,有些產品可能會想要送一些自訂的 header,例如說X-App-Version 好了,帶上目前網站的版本,這樣後端可以做個紀錄:
fetch('http://localhost:3000/form', {
method: 'POST',
headers: {
'X-App-Version': "v0.1",
'Content-Type': 'application/json'
},
body: JSON.stringify(data)
}).then(res => res.json())
.then(res => console.log(res))
當你這樣做以後,後端也必須新增 Access-Control-Allow-Headers,才能通過 preflight:
app.options('/form', (req, res) => {
res.header('Access-Control-Allow-Origin', '*')
res.header('Access-Control-Allow-Headers', 'X-App-Version, content-type')
res.end()
})
簡單來說,preflight 就是一個驗證機制,確保後端知道前端要送出的 request 是預期的,瀏覽器才會放行。我之前所說的「跨來源請求擋的是 response 而不是 request」,只適用於簡單請求。對於有 preflight 的非簡單請求來說,你真正想送出的 request 確實會被擋下來。
那為什麼會需要 preflight request 呢?這邊可以從兩個角度去思考:
針對第一點,你可能有發現如果一個請求是非簡單請求,那你絕對不可能用 HTML 的 form 元素做出一樣的 request,反之亦然。舉例來說,<form> 的 enctype 不支援 application/json,所以這個 content type 是非簡單請求;enctype 支援 multipart/form,所以這個 content type 屬於簡單請求。
對於那些古老的網站,甚至於是在 XMLHttpRequest 出現之前就存在的網站,他們的後端沒有預期到瀏覽器能夠發出 method 是 DELETE 或是 PATCH 的 request,也沒有預期到瀏覽器會發出 content-type 是 application/json 的 request,因為在那個時代 <form> 跟 <img> 等等的元素是唯一能發出 request 的方法。
那時候根本沒有 fetch,甚至連 XMLHttpRequest 都沒有。所以為了不讓這些後端接收到預期外的 request,就先發一個 preflight request 出去,古老的後端沒有針對這個 preflight 做處理,因此就不會通過,瀏覽器就不會把真正的 request 給送出去。
這就是我所說的相容性,通過預檢請求,讓早期的網站不受到傷害,不接收到預期外的 request。
而第二點安全性的話,舉個例子好了,刪除的 API 一般來說會用 DELETE 這個 HTTP 方法,如果沒有 preflight request 先擋住的話,瀏覽器就會真的直接送這個 request 出去,就有可能對後端造成未預期的行為(沒有想到瀏覽器會送這個出來)。
所以才需要 preflight request,確保後端知道待會要送的這個 request 是合法的,才把真正的 request 送出去。
最後要提一下 cookie,跨來源的請求預設是不會帶上 cookie 的,如果需要帶上 cookie,那必須滿足三個條件:
Access-Control-Allow-Credentials: true
Access-Control-Allow-Origin 不能是 *,要明確指定credentials: 'include'
對於「簡單請求」來說,只需要符合第三個,而對於「非簡單請求」來說,三個條件都要滿足。
在這篇裡面我們學習到了 CORS 的基本原理以及「為什麼瀏覽器要阻擋跨來源請求」,說到底其實都是為了安全性,才有了這個限制。除此之外,也學習到了該如何設置 CORS header,其中有一個段落講的是 Access-Control-Allow-Origin 不支援多個值,所以如果許多來源都需要這個 header,必須動態設置,那如果沒設置好呢?那就是資安漏洞啦,這個我們下一篇再來講。
本文改寫自:CORS 完全手冊(一):為什麼會發生 CORS 錯誤?以及 CORS 完全手冊(三):CORS 詳解
舉例來說,
<form>的 enctype 不支援 application/json,所以這個 content type 是非簡單請求;enctype 支援 multipart/form,所以這個 content type 屬於簡單請求
請問為何不支援 application/json,就代表這個 content type 是非簡單請求?
簡單請求跟非簡單請求的差別在於 preflight,而這個段落後面有提 preflight 的理由:
對於那些古老的網站,甚至於是在 XMLHttpRequest 出現之前就存在的網站來說,他們的後端沒有預期瀏覽器能夠發出 method 是 DELETE 或是 PATCH 的 request,也沒有預期到瀏覽器會發出 content-type 是 application/json 的 request,因為在那個時代 跟 等等的元素是唯一能發出 request 的方法。
那時候根本沒有 fetch,甚至連 XMLHttpRequest 都沒有。所以為了不讓這些後端接收到預期外的 request,就先發一個 preflight request 出去,古老的後端沒有針對這個 preflight 做處理,因此就不會通過,瀏覽器就不會把真正的 request 給送出去。
因此就可以知道如果是 form 沒辦法傳出的請求,基本上就是非簡單請求
謝謝回覆!

