就是皮爾森相關係數
這個係數是什麼呢? 大概上網查一下就有
那什麼公式的我就不貼了
重點是皮爾森相關係釋的範圍在-1~1 之間
是計算兩個變數的線性相關程度,
越接近1 表示線性正相關越強
越接近-1 表示線性負相關越強
所以在0 附近的就表示不線性相關
那這個題目要我們用皮爾森相關係數來把這2個片語的相關性映射到5 個分類
分別是0,0.25,0.5,0.75,1

我們可以觀察一下這五類特別代表什麼意思
然後再來看一下我們的input ,到底給我們什麼資料來做訓練呢?
Columns
id - a unique identifier for a pair of phrases
anchor - the first phrase
target - the second phrase
context - the CPC classification (version 2021.05), which indicates the subject within which the similarity is to be scored
score - the similarity. This is sourced from a combination of one or more manual expert ratings.
其中anchor 就是第一個片語,target 就是第二個片語,context 就是專利文章的「分類編號」
我想就有點類似我們在圖書館要找書,會找到一個分類編號,圖書館會把相近的書放在一起,所以這個也可以當成我們的一個特徵
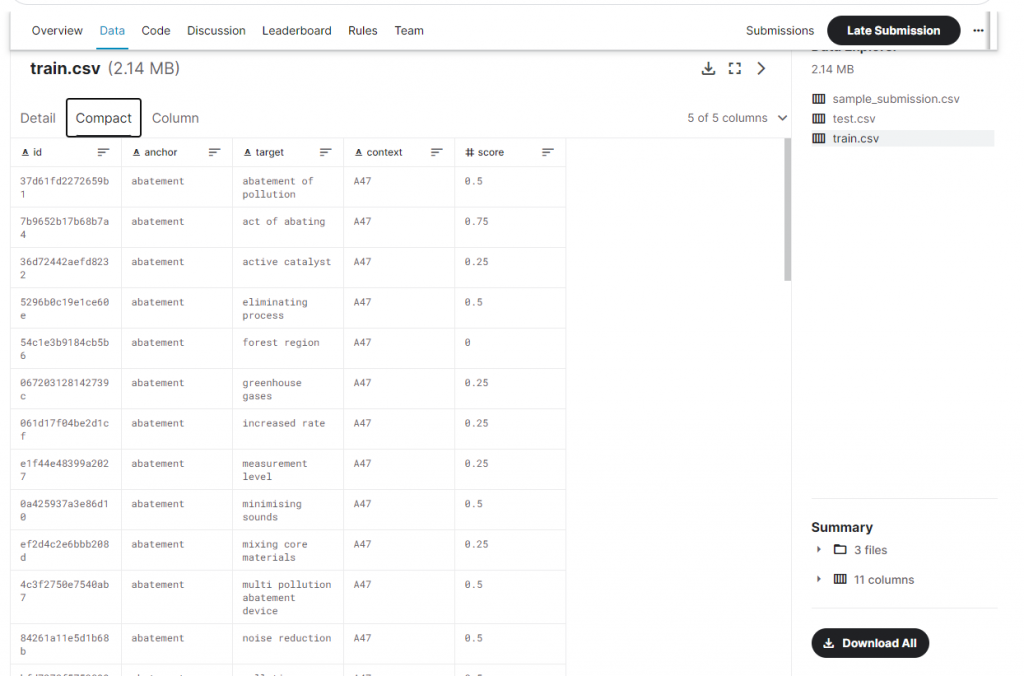
score 就是他們做的相關系數評分,由圖中可以看到已經映射到這五類
那知道題意了之後,就看看老師怎麼帶我們走完這一套流程吧!
要跑老師的notebook 要記得把運行環境改成GPU ,要不然會出錯!
一開始提到了探索性分析
也就是資料中有什麼特性呢?我們不能只看幾個sample就覺得整份資料就是這樣了,
我們要對資料做一些分析,知道我們的資料大概有哪一些特性,這樣我們在做訓練的過程中,才能對資料做合適的處理。
以下就來看看我們能做哪些事,讓我們更好的了解DATA !
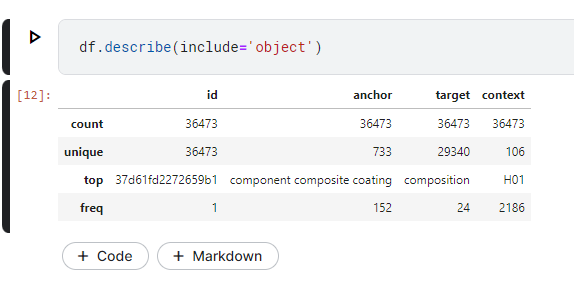
透過describe函數我們可以觀察資料筆數一共有36473 筆
anchor(片語1) 有733 種,意味著重複性資料很多,出現最多次的是component composite coating 有次數有152次
target(片語2) 有29340種,相較於片語1,大多都是相異的片語,出現最多次一樣的是composition ,次數有24次
context(分類代碼)有106種,也就是106類,其中出現最多次的類別是H01,有2186次
在這邊老師把這所有的資料都拿來訓練,也就是把片語1+片語2+分類代碼
我們可能會覺得很奇怪,分類代碼這個有什麼意義?
他們看起來是同一類,但是這個對「語境」有什麼幫助呢?
有了問題很好,後面再來解決,所以我想到的是應該要去查那個分類代碼所代表的文字
可能是那個代碼的說明,或是標題,至少有助於理解在哪個「語境」中,他們是相似的
否則直接標示H01 就要知道這2個片語是近似/ 非近似,感覺有點困難。
想法太多的話,可能會學不完哦!
所以先照老師的流程跑一遍
一開始需要切分詞,轉詞向量
即便是片語,也是至少2個詞,所以我們需要引用 AutoTokenizer
引用了一個model 叫做microsoft/deberta-v3-small 來幫我們做這件事
這邊可以看到,我們輸入的文字已經被轉成向量,也就是數字的格式,可以讓我們來做運算了!
如果有看講師的影片或是筆記的話
會發現他介紹了overfiting/underfiting
如何切訓練集/驗證集 ,以及做驗證要注意的細節
還有什麼是皮爾森係數
這些都是很常見的知識,可以google到
這邊先把流程跑完。
按照之前的案例,例如要判斷是狗還是貓
我們要定義loss function
所以在這邊就是做相關係數的運算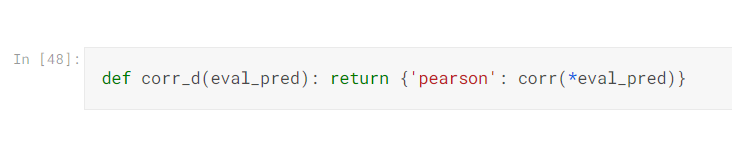
定好loss function 後,想到前面的步驟
就是選一個模型來跑跑看!
這邊用了很有名的Transformer
其中bs 就是batch size 也就是一次要處理的量,要切batch size 是因為gpu 的ram有限
所以一次先跑一點點資料拿來訓練調參數
epoch 就是跑幾輪(全部資料跑過一次叫一輪)
lr = learning rate , 前面有說過就是學習率
這邊講師特別廣告他的fastai 有自動調整學習率的工具
不過也是一樣細節太多,就先不用
我們先把結果跑一次再說
下面就是Transformer 全部的參數設定
如果看不懂的請餵chatgpt, 但現在不用懂,因為了解Transformer不是我們現階段要做的事。
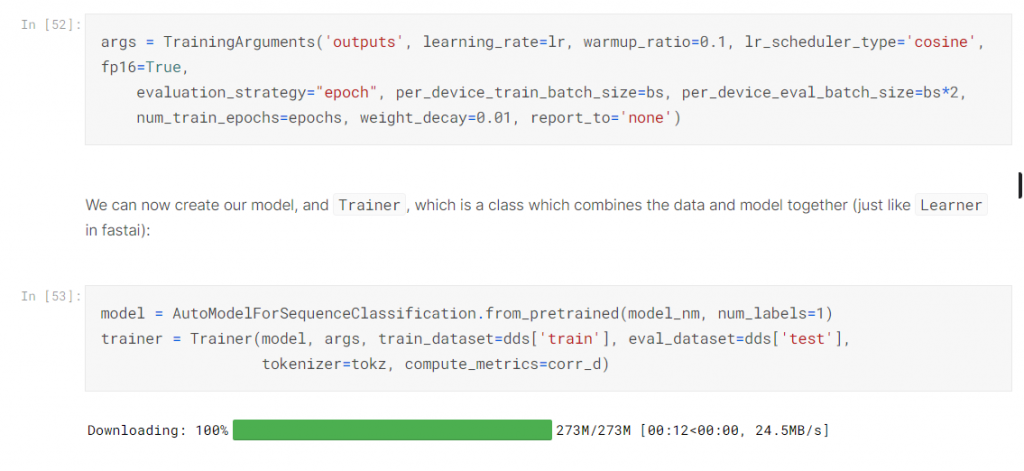
好了設定好之後就開始Train了,可以看看結果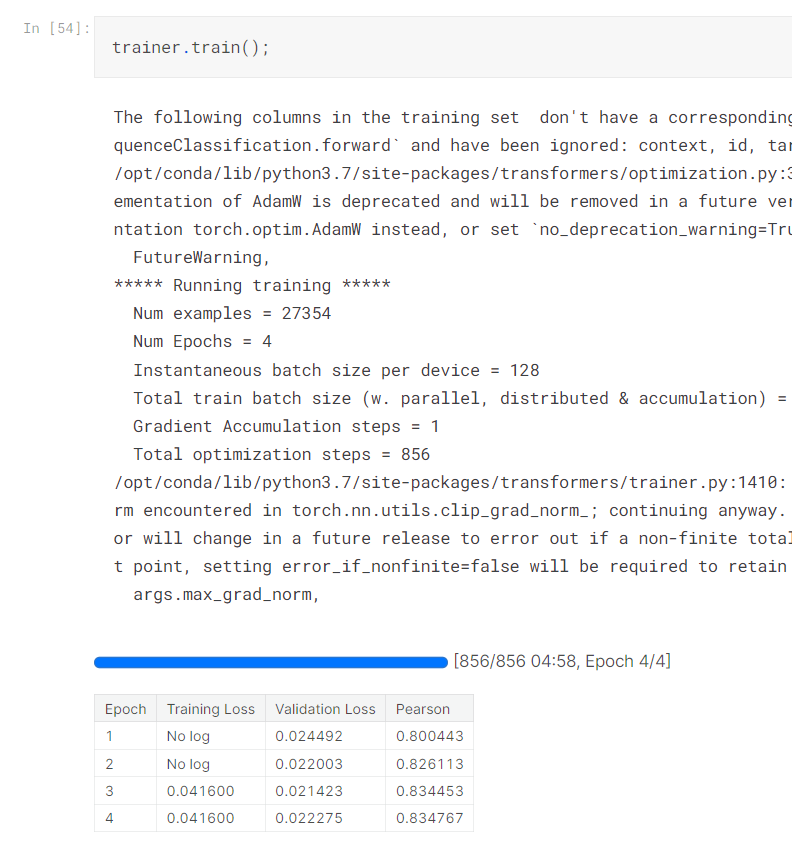
哇賽什麼事都沒做也沒微調就這樣亂做,結果似乎很不錯!?
最後把predict 的結果弄成上傳的格式,我們可以上傳看看😊,就這樣完成了一個比賽,是否很有成就感,還是很「空虛」?
我想重點不是比賽成績,而是在這個過程中
我們似乎發現了很多地方可以「優化調整」的地方。
相信還有很多疑惑,我們慢慢往下學,應該可以再優化我們這些流程,這樣我們再回頭來做這個比賽
看看是否能更高分!

