今天從Exploring the text -> embedding pipeline 開始
這邊的主要目的是瞭解如何將文本轉換成一組嵌入向量,並進一步了解這些嵌入向量是如何生成的。這些嵌入向量作為條件,可以被輸入到擴散模型中對生成的圖像產生指導作用。
所以我們一樣先定義一個文本
prompt = 'A picture of a puppy'
然後依照慣例,我們需要轉換成模型可以理解的格式,也就是要做分詞及詞向量
text_input = tokenizer(prompt, padding="max_length", max_length=tokenizer.model_max_length, truncation=True, return_tensors="pt")
其實「令牌」很大陸用語,就是token ,不知道中文怎麼翻,因為令牌跟token 我無法做連結
我比較能接受像是代幣這種說法。所以以下如果有做tokenizer 我會說切token
切token: tokenizer 會將 prompt(在這裡是 "A picture of a puppy")分解成token
參數解釋:
padding="max_length": 這表示如果切token後的序列比模型期望的最大長度短,則會添加填充token以達到該長度。
max_length=tokenizer.model_max_length: 這確定了序列的最大長度。如果切token後的序列超過此長度,則會被截斷。
truncation=True: 確保我們的輸入序列不會超過我們為模型設定的最大長度。如果沒有設定這個參數,並且我們的輸入序列超過了模型的最大長度,則可能會拋出error。
return_tensors="pt": 這表示返回的結果應該是PyTorch張量。
那為什麼這樣設定參數呢?
因為大多數深度學習模型期望輸入序列具有相同的長度。所以,我們使用padding和truncation來確保我們的輸入序列符合模型的期望。
return_tensors="pt" 是因為我們接下來要使用 PyTorch 模型,所以需要PyTorch張量格式。
接下來我們來查看一下,切完的token長什麼樣
text_input['input_ids'][0] # View the tokens
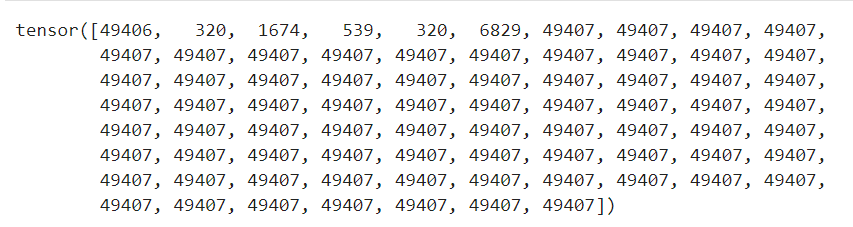
可以觀察到詞向量化的結果,每個單位都有一個對應的數字ID。這些ID是模型對詞彙的唯一標識。但,為什麼只有前面幾個不一樣,後面都是一模一樣的49407 呢?
之所以有許多重複的 49407,是因為我們前面設定使用了padding。這些 49407 是特定的填充標記(padding tokens)。
當我們對文本進行tokenizer,並希望將它們轉換成一個固定大小的序列時,如果該文本的長度小於這個固定大小,那麼我們就需要使用填充標記來補充這個序列,使其達到所需的長度。這通常在訓練深度學習模型時很常見,因為我們通常需要將不同長度的序列輸入到模型中,而模型期望所有輸入都有相同的大小。
在我們的設定中,padding="max_length" 指定了使用填充將序列的長度擴展到 max_length,即 tokenizer.model_max_length。由於原始句子(prompt)只有幾個詞,因此其餘的位置都被填充標記所填充。
for t in text_input['input_ids'][0][:8]:
print(t, tokenizer.decoder.get(int(t)))
將前8個令牌ID轉換回它們原始的文字形式,並打印它們。
觀察點:除了描述中的單詞外,還有一些特殊的token,例如 和 。這些特殊的token對於模型的輸入格式很重要,因為它們提供了有關文本開始和結束的信息。
對於這些規則,我們知道就好,因為我們暫時也不可能去改動他
老師說,我們直接跳到最後,我們需要將這些token ID再轉換為嵌入向量。為什麼?因為模型需要這種特殊的格式來捕捉和理解文本中的語義信息。
output_embeddings = text_encoder(text_input.input_ids.to(torch_device))[0]
print('Shape:', output_embeddings.shape)
我們可以再印出來看看他encoder的結果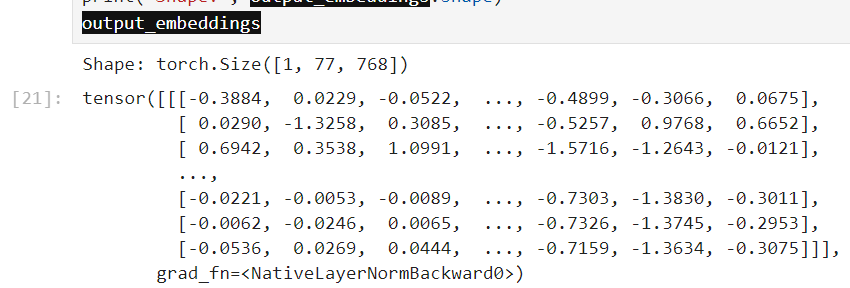
這一步將文本從一組令牌ID再轉換為一組嵌入向量,這些向量將被模型用作輸入,以幫助模型根據我們的描述生成圖片。簡單的說,就是為了符合模型的需要,需要再做一次轉換
另外,他的shape中
print('Shape:', output_embeddings.shape) 告訴我們嵌入的形狀。在這個案例中,它是一個三維張量:
第一個維度表示批次大小。這裡是1,因為我們只處理一個提示。
第二個維度是序列長度,即文本中的token數。
第三個維度是嵌入的大小,即每個token被轉換成的數字向量的大小。
text_encoder實際上是一個預先訓練的模型。它首先將每個token轉換為一個初級的嵌入,然後使用轉換器架構進行更多的處理以獲得最終的嵌入。這些嵌入向量捕捉了令牌與其上下文間的關係,這就是轉換器的功能。
那這個到底實際上是怎麼產生的?
下面講師就帶我們一步步來探討,首先印出embedding 的內容
text_encoder.text_model.embeddings
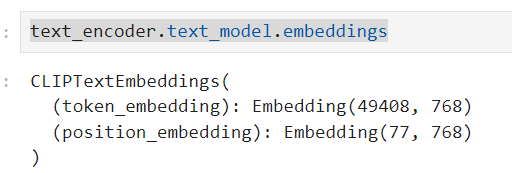
text_encoder.text_model.embeddings:
這是一個查看文本編碼器內部結構的方法。它允許我們深入瞭解文本嵌入的兩個主要部分:
token_embedding和position_embedding:
token_embedding:
這部分將每個唯一的token(例如單詞或標點符號)轉換成一個768維的向量。數字49408表
示詞彙表中的唯一token數量。
position_embedding:
這部分是用於捕捉序列中token的位置信息。每個token不僅由其內容(通
過token_embedding)定義,還由其在序列中的位置(通過position_embedding)定義
。例如,"cat" 這個詞在句子的開頭和結尾可能有不同的意義,位置嵌入會捕捉到這些細
微差別。77是模型可接受的最大序列長度。
下一篇再來好好研究Token embeddings

