下午好~
為了對語音訊號進行分析,我們需要建立對應的數學模型,其中一個簡單而被廣泛運用的模型是激勵-濾波(source-filter)線性模型,下圖為它的示意圖: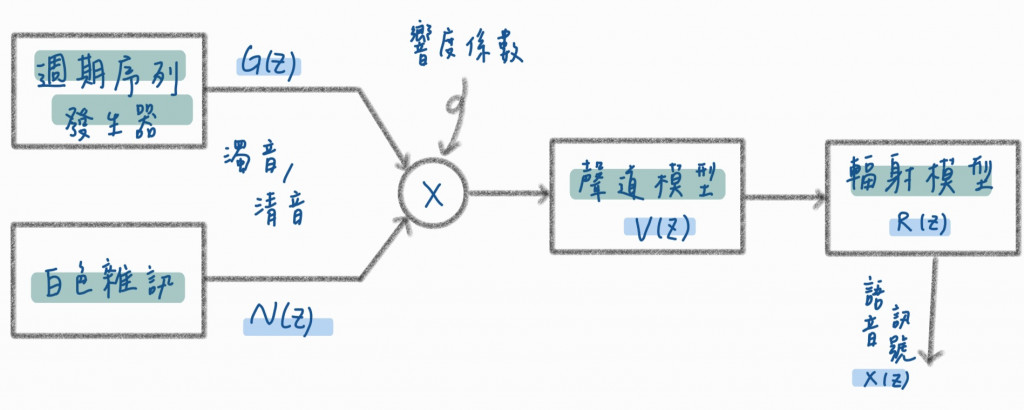
激勵濾波線性模型(Excitation-Filter Linear Model)是一種用於語音處理和語音合成的模型。它通常用於描述語音的生成過程,其中聲音信號(語音)被視為兩個主要部分的組合:激勵(Excitation)和濾波器(Filter)。
該模型首先透過週期定序器或白色雜訊分別模擬濁音和清音的訊號,其中週期定序器受到基音頻率控制,然後在激勵來源乘上響度係數,最後的訊號再經過輻射模型得到最後的語音訊號,公式如下:
對於聲道模型,有很多不同的近似方法,比如把聲道看成很多不同橫截面的圓管串聯,根據圓管長度及橫截面來建立數學模型,稱作聲管模型。另一種是將聲道看成諧振腔,其諧振頻率對應共振峰,此稱作共振峰模型。共振峰模型比較廣泛應用,因為其比較簡單,而它可以用全極點模型進行近似,一對極點對應一個共振峰,全極點模型的傳遞函數如下:
還有一種是輻射模型,其反應口唇的輻射效應及頭部的繞射效應,想精確的使用輻射模型建模比較複雜,通常使用簡單的一階高通濾波器來建模,公式如下:
總之,激勵-濾波線性模型是用於語音處理和語音合成的模型,描述了聲音的生成過程,包括激勵源和濾波器兩個部分的組合。它在語音合成和語音處理中具有廣泛的應用。
參考書籍:Hey Siri及Ok Google原理:AI語音辨識專案真應用開發
參考網站:今日無
學習對象:ChatGPT

