昨天很快樂的開始說監督式學習,突然發現有東西沒說到,所以補到今天,這就是當天想當天主題的可悲,總之今天來寫寫模型得一些東東。
不知道為甚麼一職寫關於介紹的東西
但其實我個人是蠻需要這些介紹的
很多時候關於用詞的不了解讓我在聊天時聽不懂
其實蠻難過的
而且要是不懂裝懂又會說錯話而尷尬
所以這邊來認識一下這些名詞吧!
用於評估分類模型性能的重要工具,對比模型在不同類別上的預測結果與實際情況,通常用於二元分類問題:正類別( Positive )和負類別( Negative )。
True Positives( TP ):模型預測正類別正確
True Negatives( TN ):模型預測負類別正確
False Positives( FP ):模型誤分實際負類別
False Negatives( FN ):模型誤分實際正類別
| 預測正類別 | 預測負類別 | |
|---|---|---|
| 實際正類別 | TP | FN |
| 實際負類別 | FP | TN |
正確預測的樣本比例,在不平衡的類別分佈下可能會不適用
公式如下:
Accuracy = ( TP + TN )/( TP + FP + FN + TN )
正確預測為正類別的樣本比例,用於評估正確性
公式如下:
Precision = TP /( TP + FP )
真正類別的樣本被成功預測的比例,用於評估完整性
公式如下:
TP /( TP + FN )
多數情況下,不會偏 precision 或 recall ,而是希望精確率和召回率的調和平均值,用於綜合評估模型的性能
公式如下:
F1 score = 2 * Precision * Recall / ( Precision + Recall )
ROC 曲線是將二元分類器在不同閾值設置下的性能以圖形方式展現
在不同閾值下的 True Positive Rate (簡稱 TPR )和 False Positive Rate (簡稱 FPR )為坐標,繪製出曲線
TPR Sensitivity = Recall
公式如下
TPR = TP /( TP + FN )
TPR越高,越能判斷出正樣本,表現越好
FPR
公式如下
FPR = FP / ( TN + FP )
FPR越低,越能正確判斷負樣本,表現越好
from wikipedia
AUC 代表了二元分類器的整體性能
取值 ROC 曲線下的面積落在 0 到 1 之間
AUC越大正確率越高
0.5 < AUC < 1:模型比隨機預測好,有預測能力
AUC = 0.5:模型比隨機預測好,有預測能力
AUC < 0.5:模型比隨機猜測還差,使用反預測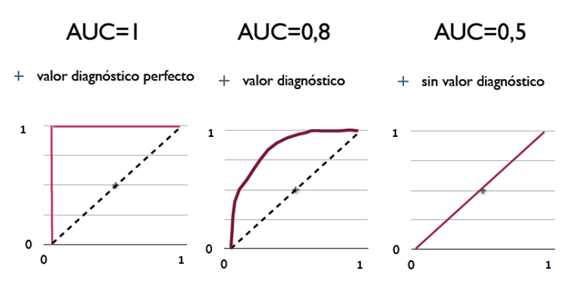
from wikipedia
結果今天只打了一半
明天還有一半
掰掰
https://chih-sheng-huang821.medium.com/%E6%A9%9F%E5%99%A8%E5%AD%B8%E7%BF%92-%E7%B5%B1%E8%A8%88%E6%96%B9%E6%B3%95-%E6%A8%A1%E5%9E%8B%E8%A9%95%E4%BC%B0-%E9%A9%97%E8%AD%89%E6%8C%87%E6%A8%99-b03825ff0814
https://medium.com/@imirene/python%E6%A9%9F%E5%99%A8%E5%AD%B8%E7%BF%92-%E5%88%86%E9%A1%9E%E6%A8%A1%E5%9E%8B%E7%9A%845%E5%80%8B%E8%A9%95%E4%BC%B0%E6%8C%87%E6%A8%99-3260f116ce47
https://dysonma.github.io/2020/12/05/%E6%A9%9F%E5%99%A8%E5%AD%B8%E7%BF%92-%E5%B8%B8%E8%A6%8B%E7%9A%84%E8%A9%95%E4%BC%B0%E6%8C%87%E6%A8%99/
https://zh.wikipedia.org/zh-tw/ROC%E6%9B%B2%E7%BA%BF

