筆者今天不用補課很快樂,但生理時鐘還是讓我在九點多就醒了,可惡我以為今天會睡爽爽地說,但早上不用通勤很快樂,總之讓我們開始今天的筆記吧!
今天說一些機器學習的概念和技術
對於建立好的模型和提高性能來說很重要
交叉驗證有助於評估模型在新資料上的性能,會將數據集分成多個子集,多次訓練和驗證模型,確保模型對不同資料子集的性能保持一致
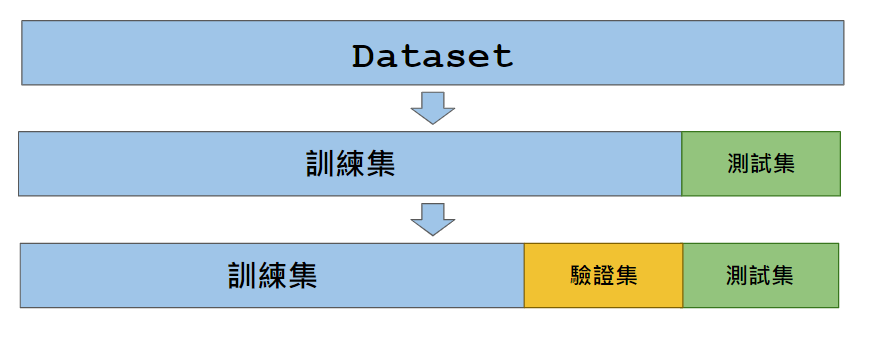
先將資料一分為二,得到訓練集和測試集,在訓練時,模型只會對訓練集進行擬合,而測試集的資料用來評估模型的性能,確保模型能夠泛化到新資料
同時也希望找到一組最好的超參數,讓模型損失盡量變低,因此會將資料進一步切為驗證集,來評估不同超參數組合的效果
為了防止模型對驗證集 Overfitting ,我們可以用交叉驗證的方法來更好地評估模型性能
總之,交叉驗證就是將訓練資料分成多個子集,一部分訓練模型,另一部分驗證模型
資料集被分成訓練集和測試集兩部分
模型在訓練集上訓練,然後在測試集上評估性能
優點:
缺點:
資料集會被分成 K 個相等的子集
每次訓練模型時,其中一個子集當作驗證集,剩下 K - 1 個子集當作訓練集
重複K次,每次不同的子集當驗證集
指標的平均值用於評估模型
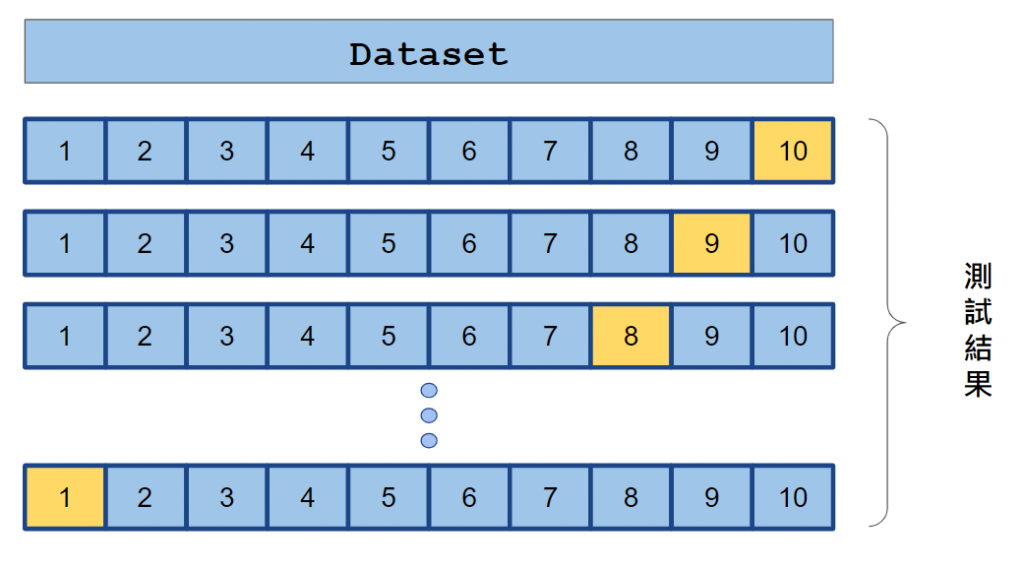
資料集被分成 10 個相等的子集
黃色是驗證集
其餘為訓練集
優點:
缺點:
每次訓練模型時,只有一個樣本被保留作為驗證集,其餘的樣本用於訓練
這個過程重複N次,其中N是資料集的樣本數
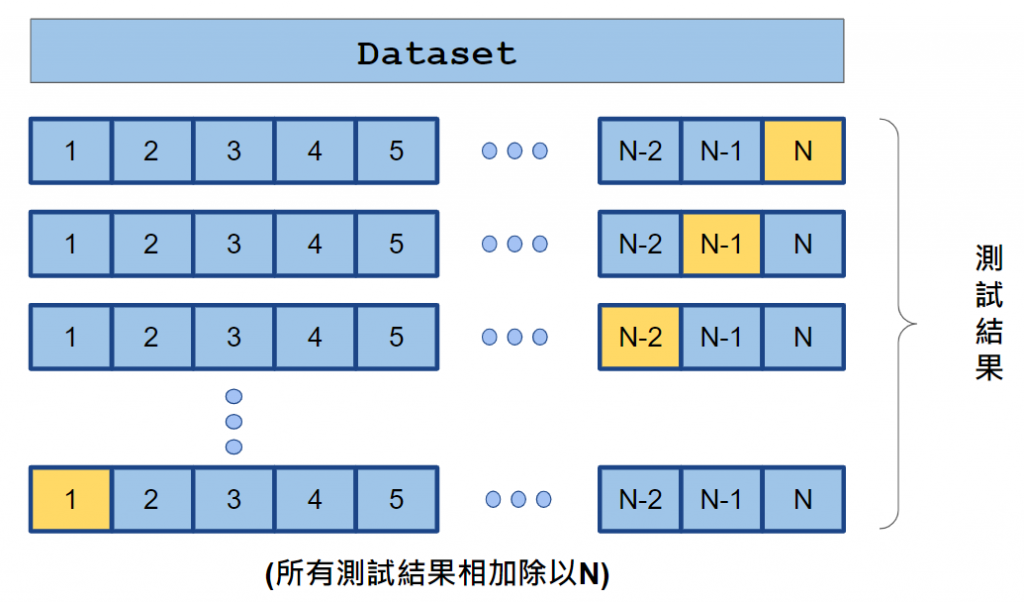
資料集總共 N 個樣本
黃色是驗證集
其餘為訓練集
優點:
缺點:
從原始資料中隨機抽樣,建立多個訓練集和驗證集的子集
有的資料可能被重複取樣,有的可能完全沒被抽樣
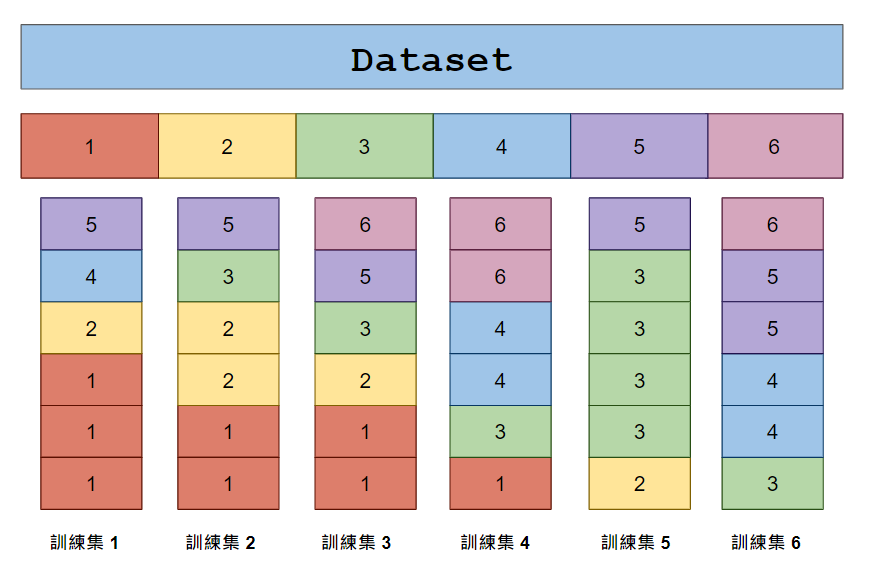
驗證集為沒有被選中的樣本
優點:
缺點:
Overfitting 就是模型在訓練資料上表現得很好,但在測試資料或新資料上表現不好
通常是因為過度學習訓練資料,而導致無法正確預測或分類未知資料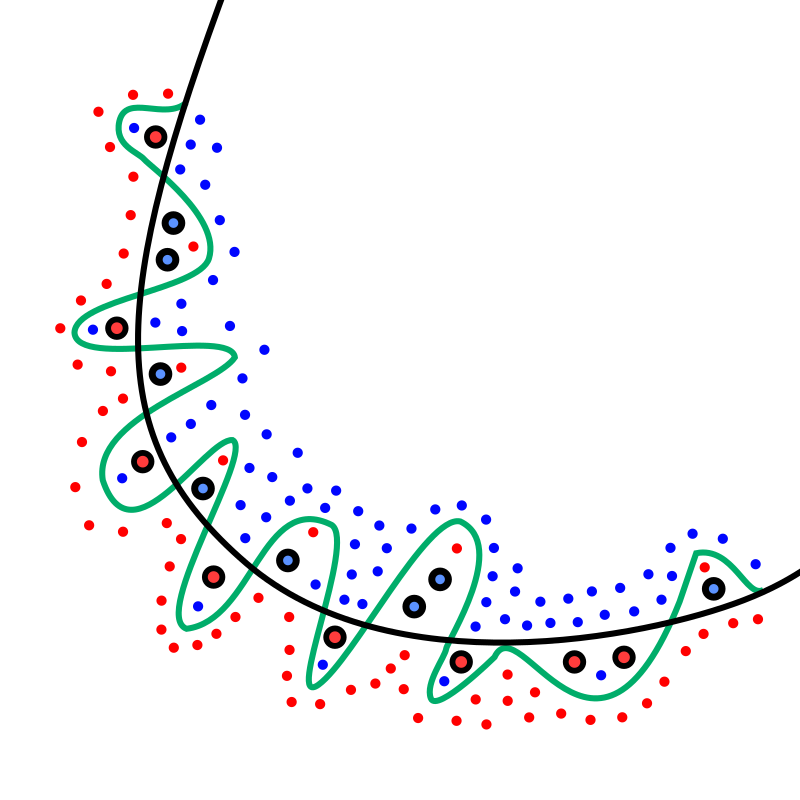
黑線代表正則化模型
綠線是 Overfitting
其中小點為訓練資料,大點為新資料
from wikipedia
Underfitting 就是模型在訓練和測試資料上都表現不好,是因為參數過少或者模型結構過於簡單,不能很好的捕捉資料中的複雜模式和關鍵特徵
參數是模型中的可學習參數,是模型在訓練過程中根據訓練資料的特徵和目標值進行調整,以使模型能夠更好地擬合資料
參數的數量通常與模型的複雜度相關,複雜的模型會有較多的參數
超參數不是模型通過訓練學習的,而是在模型訓練之前人為設定的
超參數控制了模型的行為,例如學習速率、樹的深度、正則化參數等
超參數的調整過程就是試錯的過程,嘗試不同的超參數組合,來找到最好的模型性能
超參數調校是用於優化機器學習模型的性能
嘗試不同的超參數組合,以找到在給定問題上性能最好的模型配置
超參數調校通常使用交叉驗證來評估不同超參數組合的性能,以避免 Overfitting
今天沒有什麼廢話
每天打廢話其實意外的難
https://zh.wikipedia.org/zh-tw/%E4%BA%A4%E5%8F%89%E9%A9%97%E8%AD%89
https://tomohiroliu22.medium.com/%E6%A9%9F%E5%99%A8%E5%AD%B8%E7%BF%92-%E5%AD%B8%E7%BF%92%E7%AD%86%E8%A8%98%E7%B3%BB%E5%88%97-13-%E4%BA%A4%E5%8F%89%E9%A9%97%E8%AD%89-cross-validation-%E5%92%8Cmse-mae-r2-bc8fef393f7c
https://chwang12341.medium.com/machine-learning-%E4%BA%A4%E5%8F%89%E9%A9%97%E8%AD%89-cross-validation-%E6%89%BE%E5%88%B0knn%E4%B8%AD%E9%81%A9%E5%90%88%E7%9A%84k%E5%80%BC-scikit-learn%E4%B8%80%E6%AD%A5%E4%B8%80%E6%AD%A5%E5%AF%A6%E4%BD%9C%E6%95%99%E5%AD%B8-4109bf470340
https://zh.wikipedia.org/zh-tw/%E9%81%8E%E9%81%A9

