2023 iThome 鐵人賽
分享至
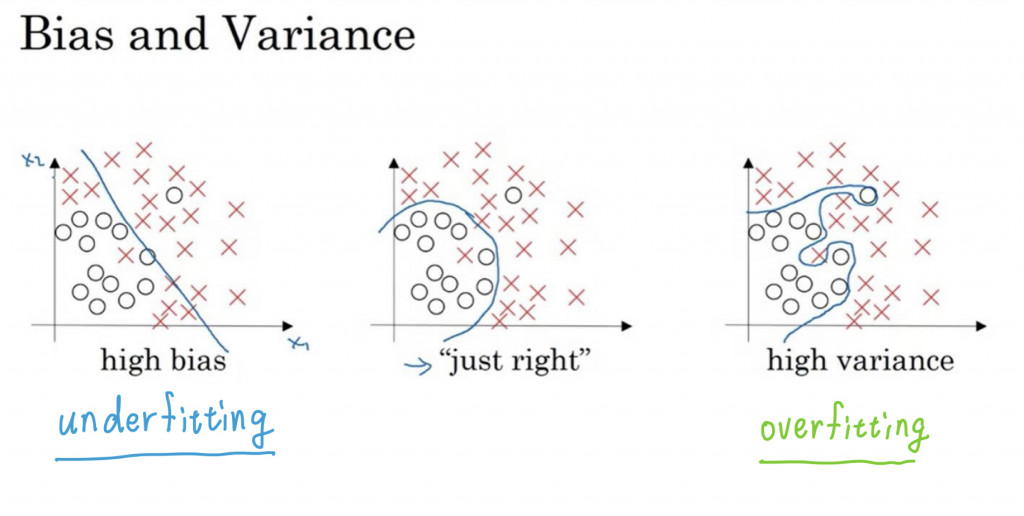
Bias(偏差值) 和 Variance(方差值) 這兩個數值是來評估你模型的分類狀況
想當然耳,我們會想要者兩個值越低越好用一張圖來看看
這邊稍稍解釋一下這兩個東西
所以說,單看其中一個值你沒辦法準確地辨別模型的優劣,而在評估如何取捨這兩個值的過程即是 Bias-Variance Tradeoff通常大家會放那張 x-y 圖,有三條線的,但我比較想提的是這張:左上角的方格開始
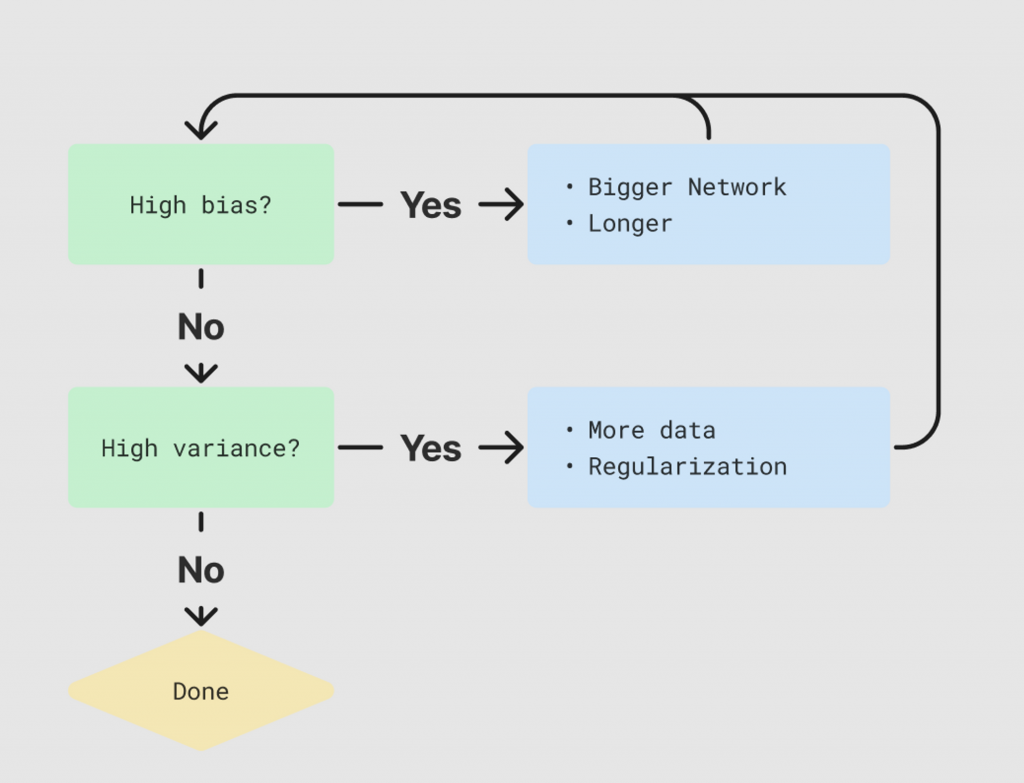
以上是簡易的判斷流程,Regularization 將在下一篇講解
這個講得很好!
IT邦幫忙


 iThome鐵人賽
iThome鐵人賽