requests 函式庫 ( 模組 ) 是相當流行的 Python 外部函式庫,具備了 GET、POST...等各種 request 用法,透過 requests 能夠輕鬆抓取網頁的資料,這篇教學會介紹 requests 函式庫的基本用法。
原文參考:Requests 函式庫
本篇使用的 Python 版本為 3.7.12,所有範例可使用 Google Colab 實作,不用安裝任何軟體 ( 參考:使用 Google Colab )
如果是使用 Colab 或 Anaconda,預設已經安裝了 requests 函式庫,不用額外安裝,如果是本機環境,輸入下列指令,就能安裝 requests 函式庫 ( 依據每個人的作業環境不同,可使用 pip 或 pip3 或 pipenv )。
pip install requests
要使用 requests 必須先 import requests 模組,或使用 from 的方式,單獨 import 特定的類型。
import requests
from requests import get
requests 可以使用下列 HTTP 六個方法,使用後會傳回一個 Response 物件,六個方法裡,GET 和 POST 是最常用的兩個方法,兩個的差別在於 GET 提交的參數會放在標頭中傳送 ( 公開 ),而 POST 則是放在內容中傳送 ( 隱密 )。
| HTTP 方法 | requests 方法 | 說明 |
|---|---|---|
| GET | requests.get(url) | 向指定資源提交請求,可額外設定 params 參數字典。 |
| POST | requests.post(url) | 向指定資源提交請求,可額外設定 data 參數字典。 |
| PUT | requests.put(url) | 向指定資源提供最新內容,可額外設定 data 參數字典。 |
| DELETE | requests.delete(url) | 請求刪除指定的資源。 |
| HEAD | requests.head(url) | 請求提供資源的回應標頭 ( 不含內容 )。 |
| OPTIONS | requests.options(url) | 請求伺服器提供資源可用的功能選項。 |
當伺服器收到 requests HTTP 方法所發出的請求後,會傳回一個 Response 物件,物件裡包含伺服器回應的訊息資訊,可以透過下列的屬性與方法,查詢相關內容 ( bytes 表示資料以 bytes 表示,str 以字串表示,dict 以字典表示 )。
| Response 物件 | 說明 |
|---|---|
| url | 資源的 URL 位址。 |
| content | 回應訊息的內容 ( bytes )。 |
| text | 回應訊息的內容字串 ( str )。 |
| raw | 原始回應訊息串流 ( bytes )。 |
| status_code | 回應的狀態 ( int )。 |
| encoding | 回應訊息的編碼。 |
| headers | 回應訊息的標頭 ( dict )。 |
| cookies | 回應訊息的 cookies ( dict )。 |
| history | 請求歷史 ( list )。 |
| json() | 將回應訊息進行 JSON 解碼後回傳 ( dict )。 |
| rasise_for_status() | 檢查是否有例外發生,如果有就拋出例外。 |
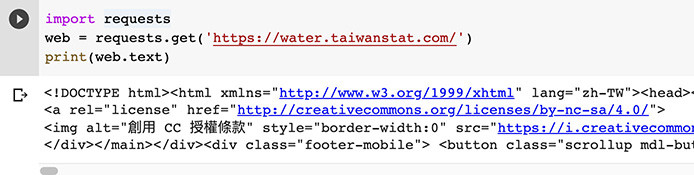
知道 requests 的使用方法後,就可以開始爬取第一個網頁內容,範例使用的網站為「台灣水庫即時水情」的網站,使用 requests.get 取得回應的物件後,就可以印出 text 的內容 ( 其他文章會介紹如何爬取更多不同的網站 )。
台灣水庫即時水情:https://water.taiwanstat.com/
import requests
web = requests.get('https://water.taiwanstat.com/') # 使用 get 方法
print(web.text) # 讀取並印出 text 屬性
如果發現爬取的內容是亂碼,往往是網頁與系統的編碼設定不同導致,只要在爬取到內容後設定 encoding 為 utf-8 通常就能順利解決。
import requests
web = requests.get('https://water.taiwanstat.com/') # 使用 get 方法
web.encoding='utf-8' # 因為該網頁編碼為 utf-8,加上 .encoding 避免亂碼
print(web.text)
除了可以爬取網頁資料,也可以透過 requests 透過 API,取得政府機關所提供的開放資料,範例使用的是「高雄輕軌月均運量統計」的 JSON 檔案,取得資料後,印出 json() 的內容 ( 注意,如果使用 json() 必須要確定回應的資料是 json 格式 )。
import requests
web = requests.get('https://data.kcg.gov.tw/dataset/6f29f6f4-2549-4473-aa90-bf60d10895dc/resource/30dfc2cf-17b5-4a40-8bb7-c511ea166bd3/download/lightrailtraffic.json')
print(web.json())

在爬取網頁時,和瀏覽網頁相同,有時會遇到網頁無法瀏覽的情況,這時可以使用「status_code」讀取網頁的回應狀態代碼,網頁有下列幾種常見的回應狀態代碼:
| 狀態代碼 | 說明 |
|---|---|
| 200 | 網頁正常。 |
| 301 | 網頁搬家,重新導向到新的網址。 |
| 400 | 錯誤的要求。 |
| 401 | 未授權,需要憑證。 |
| 403 | 沒有權限。 |
| 404 | 找不到網頁。 |
| 500 | 伺服器錯誤。 |
| 503 | 伺服器暫時無法處理請求 ( 附載過大 )。 |
| 504 | 伺服器沒有回應。 |
下方的例子會讀取一個不存在的網頁,接著判斷如果 status_code 為 404,印出「找不到網頁」的文字。
import requests
web = requests.get('https://data.kcg.gov.tw/12345')
if web.status_code == 404:
print('找不到網頁')
requests 在使用方法時,也可加入指定的參數,最常用的是 params ( GET 使用 )、data ( POST 使用 )、headers 和 cookies。
| 參數 | 說明 |
|---|---|
| params | GET 方法使用,傳遞網址參數 ( dict )。 |
| data | POST 方法使用,傳遞網址參數 ( dict )。 |
| headers | HTTP 的 headers 資訊 ( 可模擬不同的瀏覽器 )。 |
| cookies | 設定 Request 中的 cookie ( dict )。 |
| auth | 支持 HTTP 認證功能 ( tuple )。 |
| json | JSON 格式的數據,作為 Request 的內容。 |
| files | 傳輸文件 ( dict )。 |
| timeout | 設定超時時間,以「秒」為單位。 |
| proxies | 設定訪問代理伺服器,可以增加認證 ( dict )。 |
| allow_redirects | True/False,預設 True,重新定向。 |
| stream | True/False,預設 True,獲取內容立即下載。 |
| verify | True/False,預設 True,認證 SSL。 |
| cert | 本機 SSL 路徑。 |
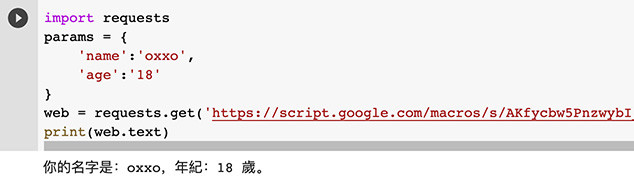
下方的例子會使用 get 的方式發送 request 給範例的網址,並會加入 params 參數,當網址收到資料後,就會回傳指定的文字。
get 範例網址:https://script.google.com/macros/s/AKfycbw5PnzwybI_VoZaHz65TpA5DYuLkxIF-HUGjJ6jRTOje0E6bVo/exec
import requests
# 設定參數
params = {
'name':'oxxo',
'age':'18'
}
# 加入參數
web = requests.get('https://script.google.com/macros/s/AKfycbw5PnzwybI_VoZaHz65TpA5DYuLkxIF-HUGjJ6jRTOje0E6bVo/exec', params=params)
print(web.text)
大家好,我是 OXXO,是個即將邁入中年的斜槓青年,我有個超過一千篇教學的 STEAM 教育學習網,有興趣可以參考下方連結呦~ ^_^


 iThome鐵人賽
iThome鐵人賽