為什麼2022年的fast.ai 還在強調這個?
(僅有的9堂課就花了2-3 堂講傳統的機器學習,佔用這麼多時間,應該是蠻強調的)
所以這個問題是我主要想知道的。也許細節不用懂太多,但是「精神」要了解。
而一天也不可能就把一個主題學完,所以還是來看一下什麼是我們必需要了解的吧!
隨機森林的核心思想
在深入了解隨機森林之前,讓我們首先明確核心思想:我們希望建立一種模型,能夠做出精確的預測。單個決策樹的容量有限,當樹變得太大時,容易過擬合(overfitting),導致預測不准確。
所以如果我們可以通過組合多個決策樹的預測來提高整體性能,是否可行呢?這種組合預測的方式稱為"bagging",它是隨機森林的一個重要概念。
Bagging的核心思想
我們可以創建多個較大的決策樹,然後將它們的預測值取平均。這種方式被稱為"bagging"(Bootstrap Aggregating)。它的關鍵優勢在於它可以降低預測的方差,從而提高模型的準確性。
Bagging的實現方式
要實現"bagging",我們需要確保每個模型的預測彼此之間不相關,這樣取平均時才能達到最佳效果。實現這一目標的一種方法是對數據的不同子集訓練每個模型。下面我們展如何在不同的隨機數據子集上訓練樹模型:
# 創建多個決策樹
trees = [get_tree() for t in range(100)]
創建了一個包含 100 個決策樹的集合 trees。每個決策樹都是在不同的數據子集上進行訓練的,以確保它們的預測結果是相互獨立的,這就是 "bagging" 的實現方式之一。
# 計算平均絕對誤差
mean_absolute_error(val_y, avg_probs)
我們建立了100顆決策樹,如果直接拿他們來預測,並計算平均呢?
這樣的結果如何?
all_probs = [t.predict(val_xs) for t in trees]
avg_probs = np.stack(all_probs).mean(0)
結果顯示 mae=0.2272645739910314
好像不怎麼樣
如果直接平均不好,那有什麼改進方法呢?
先來看看隨機森林的效果,我們再來了解他是怎麼做的
# 使用隨機森林分類器
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(100, min_samples_leaf=5)
rf.fit(trn_xs, trn_y);
mean_absolute_error(val_y, rf.predict(val_xs))
這堂課好像沒有再叫我們手寫隨機森林,直接呼叫sklearn 裡面寫好的RandomForestClasifier
然後我們可以用mae來看看效果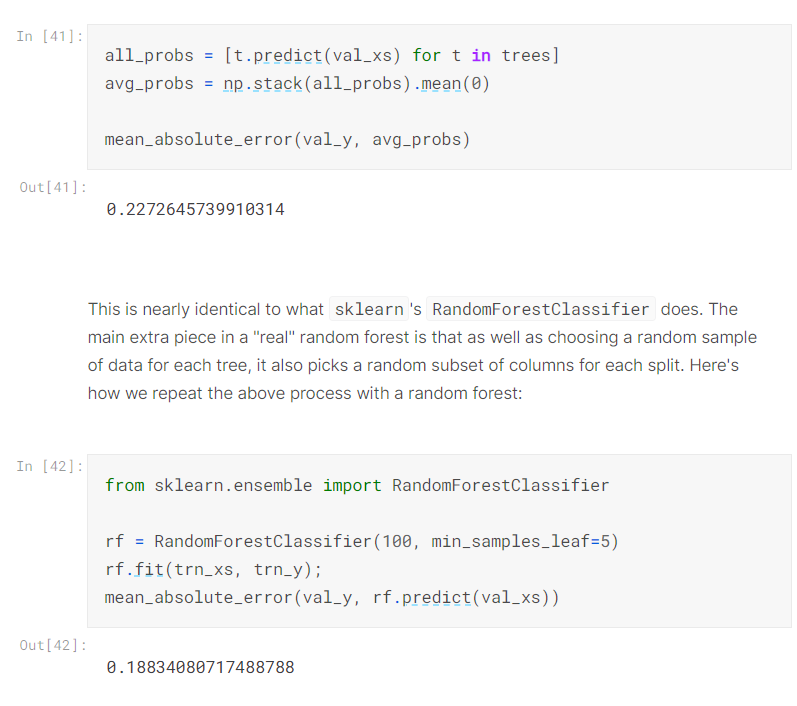
竟然降到0.18!
這隨機森林到底怎麼辦到的,講師並沒有說明。
上網查了一下,隨機是隨機在哪呢?主要是在隨機抽樣以及隨機特徵選擇
隨機抽樣,讓子集有隨機性確保了每棵樹都在不同的訓練數據上進行訓練,可以增加了模型的多樣性,這種多樣性可以減少overfitting提高模型的robustness預測準確性和魯棒性(robustrobustness)。魯棒性就是說這個模型,你如果輸入的數據有一點異常值的話,也能減少這些異常值的影響。
最後,講師為了我們展示了隨機森林的一個特點,就是可以幫我們找出哪些特徵比較重要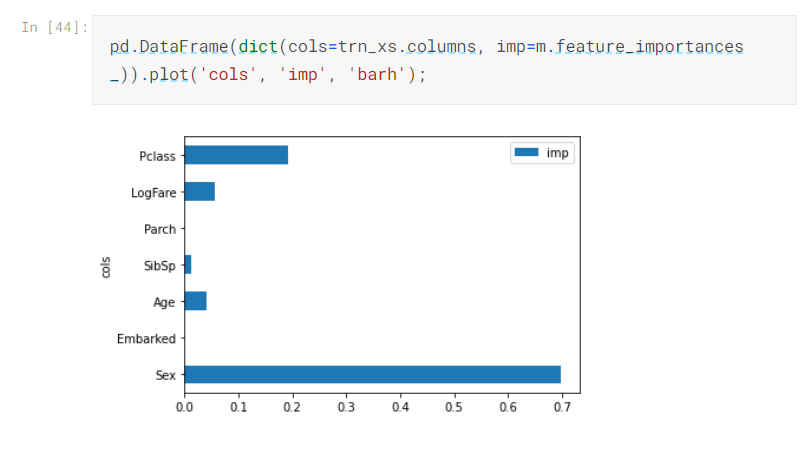
可以看到性別最重要…
所以男的最好別搭郵輪XDD
好了,學到這邊,講師終於給了他要講這麼多傳統機器學習的理由
也就是說,我們不該總是使用高大上的模型,也可以試試用簡單的模型跑跑看,或許就可以有不同的發現。

