前面提到的模型都是屬於監督式學習,除了有變數(X)還會有label(Y),在訓練的時候先告訴模型在這些X中,分別對應到哪一種Y。另一種模型為非監督式學習,這種模型只有變數(X),沒有label(Y),最常見的為K-means,也是今天要介紹的模型。K-means分群,把相似的資料分成K個群體,我們使用R語言內建的資料iris以及kmeans()函數做舉例,其中centers這個參數是決定要把這組資料分成幾群。
分群的目的在於:讓每群群內變異越小,群跟群之間的變異越大。分群後我們可藉由每群的中心來將各群命名,或是查看群內的變異來看是否要增加群數。
data("iris")
cluster = kmeans(iris[, c(1:4)], centers=3)
# 查看每群中心
cluster$centers
# 查看群內變異
cluster$withinss
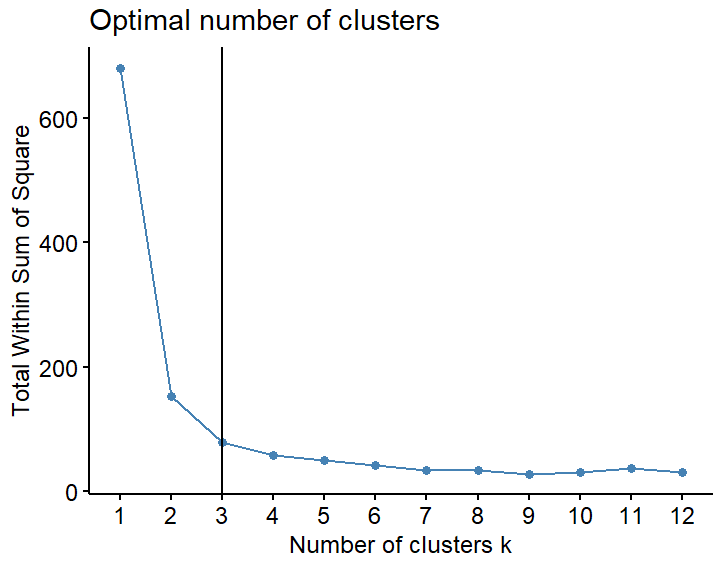
我們可以使用elbow method來決定要分幾群,通常我們會把分群的切點切在從斜率很大轉變成斜率很小的地方,可以使用以下套件
# 載入套件
library(factoextra)
fviz_nbclust(iris[, c(1:4)],
FUNcluster = kmeans, # 使用哪一種分群模型
method = "wss", # 估計最佳群數的方法
k.max = 12 # 最多計算到多少群
) + geom_vline(xintercept = 3)
由下圖我們會把分群切點切在k=3 (斜率開始趨緩前)