
在實際應用中,很少有人從頭開始訓練一個完整的卷積神經網絡(使用隨機初始化),因為擁有足夠大的數據集相對較罕見。相反,通常會在非常大的數據集上(例如ImageNet,其中包含1.2百萬張圖片,涵蓋1000個類別)對卷積神經網絡進行預訓練,然後將這個卷積神經網絡用作感興趣任務的初始化模型或固定的特徵提取器。
對ConvNet進行微調(Finetuning):與隨機初始化不同,我們使用預訓練的網絡來初始化網絡,例如那些在Imagenet 數據集上訓練過的網絡。其餘的訓練過程與平常步驟一樣。
ConvNet作為固定特徵提取器:在這裡,我們會凍結網絡的所有權重,除了最後的全連接層之外。這個最後的全連接層會被一個新的、帶有隨機權重的層所取代,並且只訓練這一層。
首先我們先完成 DataLoader 訓練和測試的流程(程式碼與之前的相同):
import torch
from torch import nn
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import torch.nn.functional as F
import os
train_path = './cat-vs-rabbit/train-cat-rabbit'
test_path = './cat-vs-rabbit/test-images'
val_path = './cat-vs-rabbit/val-cat-rabbit'
# 正規化是機器學習常用的資料前處理,將資料範圍變成[0,1]之間
normalize=transforms.Normalize(mean=[.5,.5,.5],std=[.5,.5,.5])
transform=transforms.Compose([
transforms.RandomCrop(224), # 隨機裁減
transforms.RandomHorizontalFlip(), # 圖像水平翻轉
transforms.ToTensor(), # 轉成 tensor 格式
normalize
])
# 建立資料集
train_dataset = datasets.ImageFolder(train_path, transform = transform)
val_dataset = datasets.ImageFolder(val_path, transform = transform)
test_dataset = datasets.ImageFolder(test_path, transform = transform)
train_dataloader = DataLoader(train_dataset, batch_size=64, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=64, shuffle=True)
device = (
"cuda"
if torch.cuda.is_available()
else "mps"
if torch.backends.mps.is_available()
else "cpu"
)
print(f"Using {device} device")
def train_loop(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
model.train()
for batch, (X, y) in enumerate(dataloader):
# 將資料讀取到GPU中
X, y = X.to(device), y.to(device)
# 運算出結果並計算loss
pred = model(X)
loss = loss_fn(pred, y)
# 反向傳播
loss.backward()
optimizer.step()
optimizer.zero_grad()
if batch % 100 == 0:
loss, current = loss.item(), (batch + 1) * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
def test_loop(dataloader, model, loss_fn):
model.eval()
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, correct = 0, 0
# 驗證或測試時記得加入 torch.no_grad() 讓神經網路不要更新
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
torchvision.models提供了很多模型的架構和預訓練的權重,我選擇了一個網路架構較淺,但速度較快的模型 (雖然說小,但其實比我們之前創的深很多):
import torchvision.models as models
import torchvision
mobilenet_v3_model = models.mobilenet_v3_small(pretrained=True)
print(mobilenet_v3_model)
learning_rate = 1e-2
batch_size = 64
epochs = 10
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(mobilenet_v3_model.parameters(), lr=learning_rate)
因為使用 ImageNet 預訓練,所以要改輸出的類別數量,我們只預測貓咪和兔子,因此要改成預測兩個類別,將mobilenet_v3_model.classifier 的輸出改成 2:
num_classes = 2
mobilenet_v3_model.classifier = nn.Sequential(
nn.Linear(576, 1024),
nn.ReLU(),
nn.Linear(1024, num_classes)
)
mobilenet_v3_model.to(device)
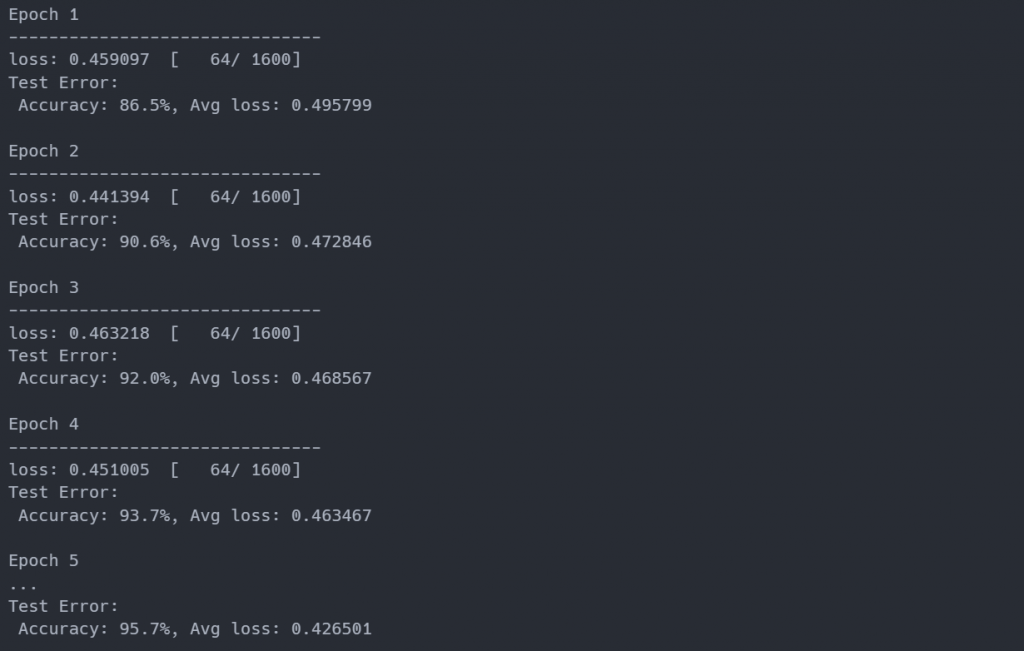
這個流程與之前相同,訓練 10 個 Epochs 看看結果如何:
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train_loop(train_dataloader, mobilenet_v3_model, loss_fn, optimizer)
test_loop(val_dataloader, mobilenet_v3_model, loss_fn)
print("Done!")
看起來表現很好,結果有 95.7% 的準確率:
通常我們不會從頭開始訓練一個模型,使用預訓練模型有下列好處:
節省時間和資源:預訓練模型已經在大規模數據上訓練過,因此省去了從頭訓練模型所需的龐大計算和時間成本。
更好的初始性能:由於預訓練模型已經學到了許多通用特徵和知識,因此它們通常在初始性能方面優於從零開始的模型。
泛化能力:預訓練模型已經學到了從源數據集中提取特徵的能力,這使它們能夠在不同但相關的任務上表現出色。


 iThome鐵人賽
iThome鐵人賽