前面的部分與之前的程式碼相同,解析 csv 的資訊:
import pandas as pd
import numpy as np
import os
from PIL import Image
# 匯入的時候出錯,pandas.parser.CParserError: Error tokenizing data. C error
fasion_df = pd.read_csv("./fashion_product_images_small/myntradataset/styles.csv", on_bad_lines='skip')
# 輸出頭尾資料
fasion_df['image'] = fasion_df.apply(lambda row: str(row['id']) + ".jpg", axis=1)
fasion_df = fasion_df.reset_index(drop=True)
此處我們將無法讀取到的圖片和不是3維的圖片移除:
image_name = fasion_df['image'].to_numpy()
image_path = [os.path.join("./fashion_product_images_small/myntradataset/images",i) for i in image_name ]
img_pil = Image.open(image_path[0])
# 用來存有問題的圖片
fail_img_list = []
for i in range(len(image_path)):
if os.path.isfile(image_path[i]):
img_pil = Image.open(image_path[i])
if len(img_pil.getbands()) != 3:
# print("image channels not RGB: ", image_path[i])
print(os.path.basename(image_path[i]))
fail_img_list.append(os.path.basename(image_path[i]))
else:
print("image path not exist: ", image_path[i])
fail_img_list.append(os.path.basename(image_path[i]))
# 將例外的圖片去除
for fail_img_name in fail_img_list:
fasion_df = fasion_df.drop(fasion_df[fasion_df["image"]==fail_img_name].index)
master_category = fasion_df["masterCategory"]
master_category_np = master_category.to_numpy()
print(len(master_category_np))
master_category_set = set(master_category_np)
master_category_list = list(master_category_set)
dic = {}
# 建立字典將每個類別對應到一個數值
for i in range(len(master_category_set)):
dic[master_category_list[i]] = i
image_name = fasion_df['image'].to_numpy()
image_name = fasion_df['image'].to_numpy()
print("圖片總數: ", len(image_name))
image_path = [os.path.join("./fashion_product_images_small/myntradataset/images",i) for i in image_name ]
# 切割成訓練和測試集
image_path_train = image_path[:35000]
image_path_test = image_path[35000:]
master_category = fasion_df["masterCategory"].to_numpy()
category_label = []
# 將 label 文字轉為數字
for i in range(len(master_category)):
category_label.append(dic[master_category[i]])
category_label = np.array(category_label)
category_label_train = category_label[:35000]
category_label_test = category_label[35000:]
因為使用 mobileNet,我們先中央裁減接著將圖片 resize 到 224*224:
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
from matplotlib import pyplot as plt
normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
transform = transforms.Compose([
transforms.CenterCrop(60),
transforms.Resize(224),
transforms.RandomHorizontalFlip(), # 圖像水平翻轉
transforms.ToTensor(),
normalize
])
def default_loader(path):
img_pil = Image.open(path)
img_tensor = transform(img_pil)
return img_tensor
class trainset(Dataset):
def __init__(self, image_path, label, loader=default_loader):
# 定義好 image 的路徑
self.images = image_path
self.label = label
self.loader = loader
def __getitem__(self, index):
fn = self.images[index]
img = self.loader(fn)
label = self.label[index]
return img, label
def __len__(self):
return len(self.images)
class testset(Dataset):
def __init__(self, image_path, label, loader=default_loader):
# 定義好 image 的路徑
self.images = image_path
self.label = label
self.loader = loader
def __getitem__(self, index):
fn = self.images[index]
img = self.loader(fn)
label = self.label[index]
return img, label
def __len__(self):
return len(self.images)
train_dataset = trainset(image_path=image_path_train, label=category_label_train)
train_dataloader = DataLoader(train_dataset, batch_size=64)
test_dataset = testset(image_path=image_path_test, label=category_label_train)
test_loader = DataLoader(test_dataset, batch_size=64)
抓到要使用的裝置:
from torch import nn
import torch
device = (
"cuda"
if torch.cuda.is_available()
else "mps"
if torch.backends.mps.is_available()
else "cpu"
)
載入 mobilenet_v3_model 架構和使用 pretrained 好的權重,把輸出層改成我們的類別數:
import torchvision.models as models
import torchvision
mobilenet_v3_model = models.mobilenet_v3_small(pretrained=True)
# print(mobilenet_v3_model)
num_classes = 7
mobilenet_v3_model.classifier = nn.Sequential(
nn.Linear(576, 1024),
nn.ReLU(),
nn.Linear(1024, num_classes)
)
mobilenet_v3_model.to(device)
learning_rate = 1e-2
batch_size = 64
epochs = 10
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(mobilenet_v3_model.parameters(), lr=learning_rate)
def train_loop(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
model.train()
for batch, (X, y) in enumerate(dataloader):
y = torch.tensor(y, dtype=torch.long)
# 將資料讀取到GPU中
X, y = X.to(device), y.to(device)
# 運算出結果並計算loss
pred = model(X)
loss = loss_fn(pred, y)
# 反向傳播
loss.backward()
optimizer.step()
optimizer.zero_grad()
if batch % 1000 == 0:
loss, current = loss.item(), (batch + 1) * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
def test_loop(dataloader, model, loss_fn):
model.eval()
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, correct = 0, 0
# 驗證或測試時記得加入 torch.no_grad() 讓神經網路不要更新
with torch.no_grad():
for X, y in dataloader:
y = torch.tensor(y, dtype=torch.long)
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train_loop(train_dataloader, mobilenet_v3_model, loss_fn, optimizer)
test_loop(test_loader, mobilenet_v3_model, loss_fn)
print("Done!")
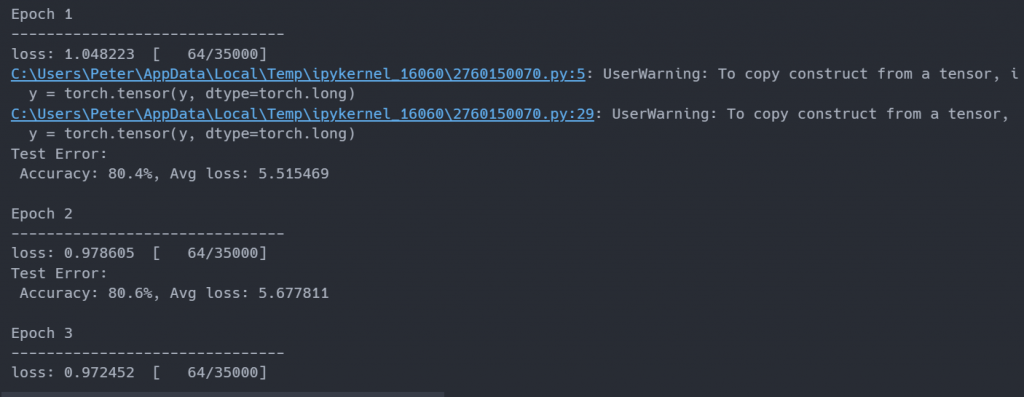
訓練完大概有80%的準確率:
今天大概把時尚資料集用到一個段落,明天會把我鐵人賽的系列文章整理成一個大綱,方便大家閱讀。

