可觀測性目的是希望能更了解你的系統,為了更了解系統運行中的狀態跟行為,會從不同的角度、不同的時間和管道蒐集不同的遙測(Telemetry)數據資料,透過這些資料類型我們可以推斷出系統的情況,將這些稱之為信號,在可觀測性中常見的三個信號包括 Metrics、Logging 與 Tracing。
在各大研討會與文章都可以看到上述為可觀測性三支柱 (尤其是工具商 XD),但如果要定義得更明確,實際執行上更為清楚個人應該是 Metrics、Structured Log 與 Distributed Tracing,以下針對三者做簡單說明
跟 Logging 有什麼分別 ?
日誌通常會包含有用的資訊,當程式出現異常時方便開發人員進行盤查查找問題,可能包含事件的描述,發生的時間,嚴重類型與其他像是用戶ID、IP 等各種訊息。
傳統的日製設計上是非結構化的,可能會是以行為單位為了方便人類閱讀,例如
2023-03-16T12:02:00 - info: Request 1234 started from user 5678. GET /my/endpoint
2023-03-16T12:02:00 - info: User 5678 authenticated - name foo
2023-03-16T12:02:01 - info: Processing request 1234
2023-03-16T12:02:02 - info: Request 1234 finished with status code 200. It took 2 seconds
結構化日誌是在原有的資訊中使用 key/value 加在其資訊中,方便機器進行解析的動作,將上面日誌換成結構化格式
timestamp=2023-03-16T12:02:00 level="info" message="Request started" requestId="1234" userId="5678" path="/my/endpoint" httpMethod="GET"
timestamp=2023-03-16T12:02:00 level="info" message="User authenticated" requestId="1234" userId="5678" userName="foo" userPlan="professional"
timestamp=2023-03-16T12:02:01 level="info" message="Processing request" requestId="1234" rateLimited="false"
timestamp=2023-03-16T12:02:02 level="info" message="Request finished" requestId="1234" durationMs="2000" statusCode="200"
結構化日誌是可觀測性除錯的基礎。這些日誌更容易被日誌系統取得,團隊也可以透過日誌系統任意的標準搜尋相關資訊。
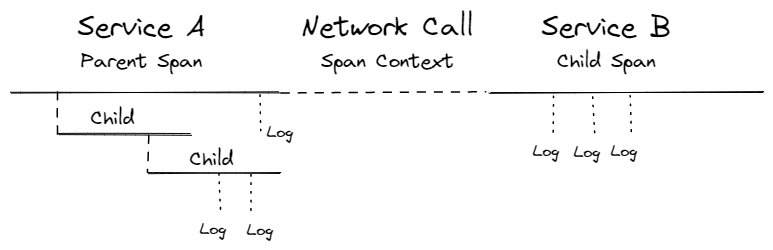
分散式追蹤的偵測有兩個主要目的:上下文傳播(context propagation)和跨度映射(span mapping)。上下文傳播是透過使用可與 HTTP 用戶端和伺服器整合的程式庫完成。在這一部分中,可以使用 OpenTelemetry API/SDK、OpenTracing 和 OpenCensus 等專案、工具和技術。
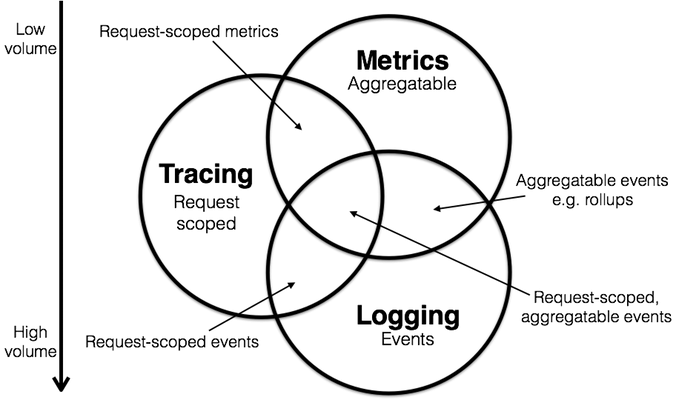
如果你是對可觀測性略有研究的朋友,相信一定看過上面這張圖, Peter Bourgon 在 2017 年參加完分散式追蹤研討會後所繪製的圖,說明 Metrics, tracing 及 logging 訊號彼此的關聯性與重要性。並在可觀測性中發揮不同且互補的作用。
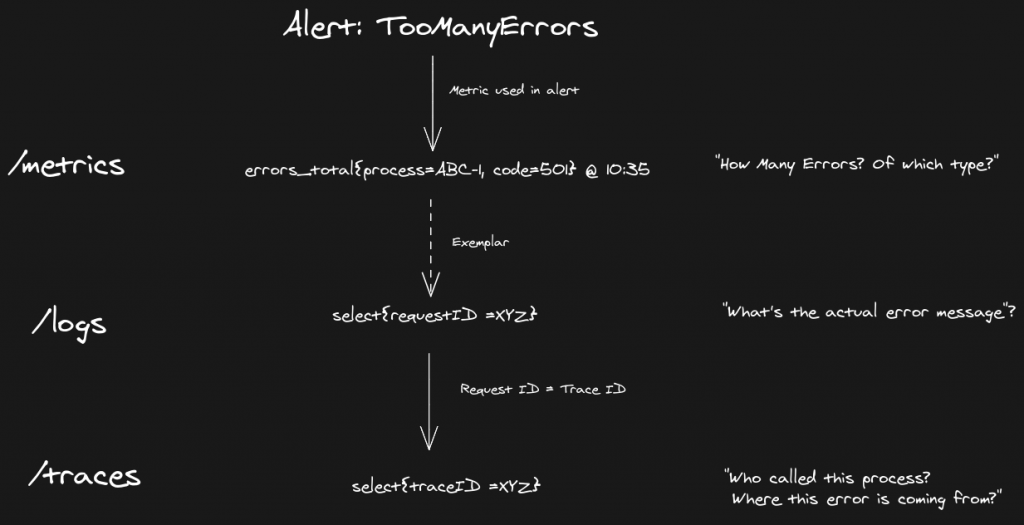
這句話聽起來好像有道理但又似乎有些模糊,這裡來舉個範例讓大家更容易理解,如上圖所示,
透過三個信號的結合,團隊才能清楚的確切地知道哪個服務或流程導致了問題,並進行了更多挖掘可能的問題動作。
These three pillars continue to be critically important. But it’s important not to be confined by the “three pillars” paradigm and to choose the right telemetry data for your needs.
from logz.io
OS : 只有賽亞人才能超越超級賽亞人 XDDD
關於可觀察性的討論通常會提到「可觀察性三大支柱」,這兩年開始越來越多人開始討論 連續性分析(Continuous Profiling) 作為一種新的可觀測性信號
關於更多的 Continuous Profiling 資訊,可以參考 OpenObservability Talks 的介紹
以上是今天的分享,如果有任何疑問或想法,歡迎留言提出討論 !
OS : 越來越長篇字數已爆,不知道有沒有休刊 OR 暫停連載的選項 XDDD
Correlating Signals Efficiently in Modern Observability
OpenTelemetry Roadmap and Latest Updates
5 Key Observability Trends for 2022
Continuous Profiling: A New Observability Signal


 iThome鐵人賽
iThome鐵人賽