mentor:
查詢一下 partition table 的資訊,
這個架構在查詢上面要注意的事情有哪些,主要是會影響查詢效能。
我自己對於資料庫的使用,在之前也有使用過MySQL自己建構一個完整系統的資料架構,
並串接工廠端的Oracle連線撈資料去處理,但還沒有使用遇過partition table。
因為這邊的資料量非常大,都是幾億筆,因此有要來認識一下這個架構。
分區表(Partition Table)允許你將一個大表分成多個更小的子表,每個子表都被稱為分區。
這種方法可以改善性能、簡化數據管理,以及提高查詢效率,特別是對於包含大量數據的表格來說。
性能提升: 分區表降低大表查詢負擔,提高性能,特定子表查詢更快速。
簡化管理: 自動數據分區,簡化數據加載、清理,減少手動處理。
優化查詢: 分區表優化查詢計劃,提高效率,特別適用於大數據。
容易擴展: 添加新分區輕鬆,無需修改表結構,減少停機時間。
維護效能: 減少索引和統計維護開銷,只需處理特定分區。
節省空間: 某些策略可壓縮舊分區,更有效地利用存儲。
因為認識一個架構最快的方式我覺得是自己實做一次,
這邊先做一個簡單的partition table。
那這邊我使用的資料庫管理系統是DBeaver。
步驟1:創建主表
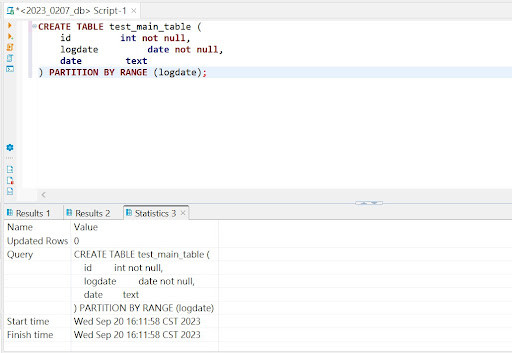
1.使用SQL語法建立partition table (添加 PARTITION BY RANGE (date) 設定 partition key)
-- 定義主表為分區表
CREATE TABLE test_main_table (
id serial PRIMARY KEY,
date date,
data text
) PARTITION BY RANGE (date);
2.確認建立後得資料表分區部分有打勾,並有表格分區依據鍵 RANGE (logdate)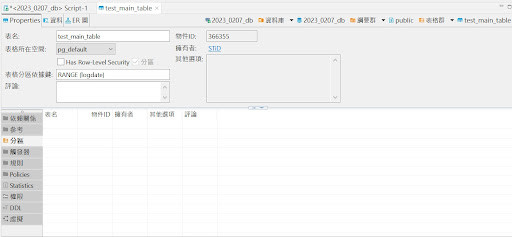
步驟2:創建分區表
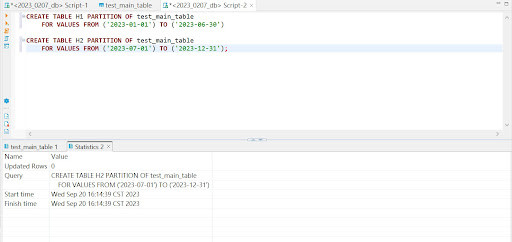
1.創建分區表,並指定用於分區的條件
-- 創建子分區表
CREATE TABLE H1 PARTITION OF test_main_table
FOR VALUES FROM ('2023-01-01') TO ('2023-06-30');
CREATE TABLE H2 PARTITION OF test_main_table
FOR VALUES FROM ('2023-07-01') TO ('2023-12-31');
2.分區表的名稱按需求命名,並且每個分區表都應該包含一個條件,以確定哪些數據應該存儲在特定的分區表中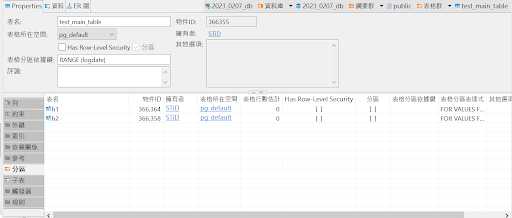
步驟3:插入數據
1.將數據插入主表,PostgreSQL 將自動根據分區條件將數據路由到正確的分區表中。
INSERT INTO test_main_table (id, logdate, date) VALUES ('1','2023-02-15','20230215');
INSERT INTO test_main_table (id, logdate, date) VALUES ('1','2023-08-20','20230820');
INSERT INTO test_main_table (id, logdate, date) VALUES ('1','2023-01-15','20230115');
INSERT INTO test_main_table (id, logdate, date) VALUES ('1','2023-09-20','20230920');
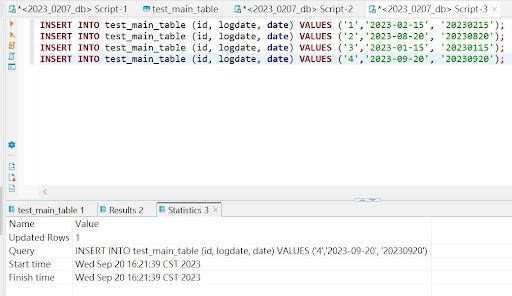
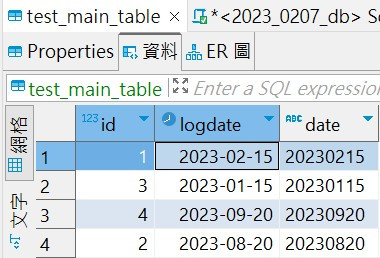
2.之後在select條件加上partition key的條件後,會直接找該分區的資料,提升效率。
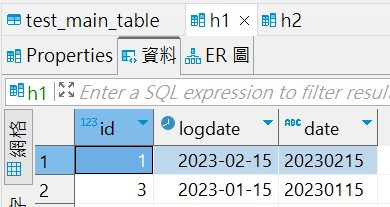
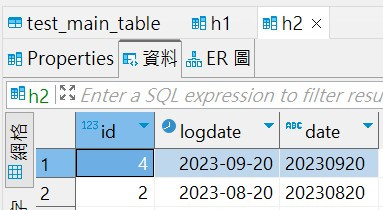
以上完成~
分區表是一個強大的資料庫架構,
可以改善性能、簡化數據管理,並提高查詢效率,特別適用於處理大數據。
通過上述步驟,我們成功地建立了一個分區表並進行了數據操作。
希望這份教學能幫助你更好地理解和應用分區表,以應對大規模數據的挑戰

