我們之前有學過要訓練一個優質的自然語言處理模型,必須打造出一個良好的詞嵌入向量,因此在今天的文章裡,我將為你介紹Word2Vec預訓練模型的訓練原理以及其模型架構在Pytorch中的實現方法,當然我們不是直接呼叫的函式庫而是手動的將模型給建構出來這樣子就能夠加深你對這模型的理解度我們今天的學習重點如下:
Word2Vec的基礎理論Skip-gram與CBOW
Word2Vec所產生的問題Word2Vec是一種將單個詞彙轉換為連續向量的詞嵌入技術,其目的是更有效地捕捉詞彙之間的語義相似度。這種技術與我們先前使用的時間序列模型有所不同。在我們過去的方法中,我們嘗試透過某一方向的文字推斷下一個的文字,而Word2Vec則採用了Skip-gram或CBOW兩種方法,這些方法都能使詞嵌入層能夠學習到從詞彙中心擴散出的文字機率,從而產生出一個更完整的詞嵌入,接下來我們將詳細探討這兩種方法的實現方式。
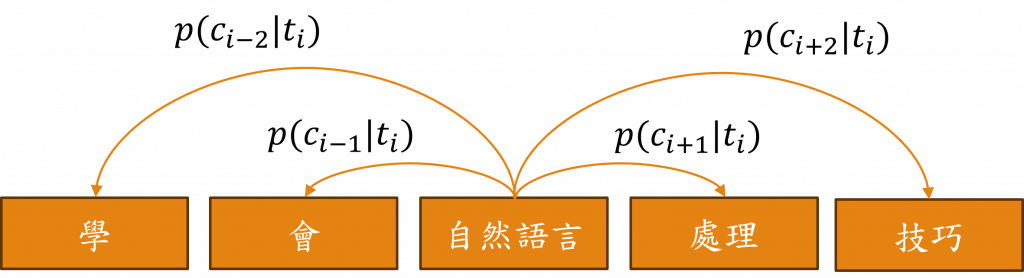
Skip-gram的目標是根據特定詞彙來預測上下文詞彙機率,該模型的運作方式是先輸入一個目標詞彙t(i),然後輸出與該詞彙上下文c(i±j)相關的詞彙機率,並且學習到最大化上下文的機率,這可以用以下的公式來表示:
整體的模型架構與我們先前的相比,實際上非常簡單,我們只需建立兩個詞嵌入層,來轉換目標詞彙與其詞彙上下文,第一個詞嵌入層負責將t(i)轉換為t'(i),而第二個則負責將c(i±j)轉換為c(i±j),此時我們只需計算這兩個詞嵌入層之間的機率即可。
score()的計算方式與注意力機制相同有非常多種算法,這些算法的只要能結合兩者之間的訊息並計算出機率,都可以被適用作為score()的算法,在這裡我將列舉三種常見的方法: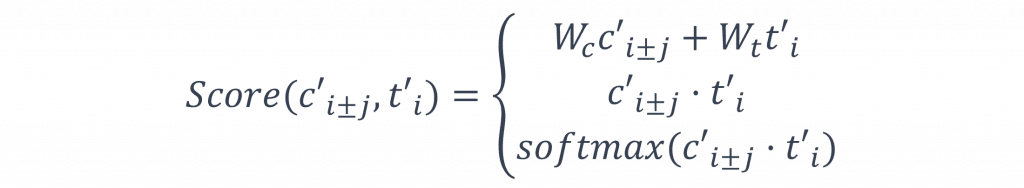
我相信你學習了關於注意力機制的算法後,應能理解上述這三個公式在Pytorch中的實現方式,然而為了讓你有更深入的理解,我將通過以下程式碼詳細介紹如何構建這些公式,程式碼中的return對應的是整個詞彙表中的機率,而標籤為1代表該詞彙存在於上下文中反之則為0,例如當標籤是[0, 1, 1],輸出可能為[0, 0.8, 0.4],如此一來就可以透過損失函數計算損失了。
(1) 加總方式
class SkipGram(nn.Module):
def __init__(self, vocab_size, embed_size):
super().__init__()
self.emb_in = nn.Embedding(vocab_size, embed_size)
self.emb_out = nn.Embedding(vocab_size, embed_size)
self.in = nn.Linear(embed_size, output)
self.out = nn.Linear(embed_size, output)
def forward(self, target, context)
in_embeds = self.in_embedding(target)
out_embeds = self.out_embedding(context)
return self.in(in_embeds) + self.out(out_embeds)
(2) 相乘方式
class SkipGram(nn.Module):
def __init__(self, vocab_size, embed_size):
super().__init__()
self.emb_in = nn.Embedding(vocab_size, embed_size)
self.emb_out = nn.Embedding(vocab_size, embed_size)
def forward(self, target, context)
in_embeds = self.in_embedding(target)
out_embeds = self.out_embedding(context)
return torch.matmul(in_embeds, out_embeds.t())
(3) 機率計算方式
class SkipGram(nn.Module):
def __init__(self, vocab_size, embed_size):
super().__init__()
self.emb_in = nn.Embedding(vocab_size, embed_size)
self.emb_out = nn.Embedding(vocab_size, embed_size)
def forward(self, target, context)
in_embeds = self.in_embedding(target)
out_embeds = self.out_embedding(context)
matmul_emb = torch.matmul(in_embeds, out_embeds.t())
return F.softmax(matmul_emb, dim = 1)
透過上述的方法,我們就能讓這些文字學習到目標文字周遭的關聯性。
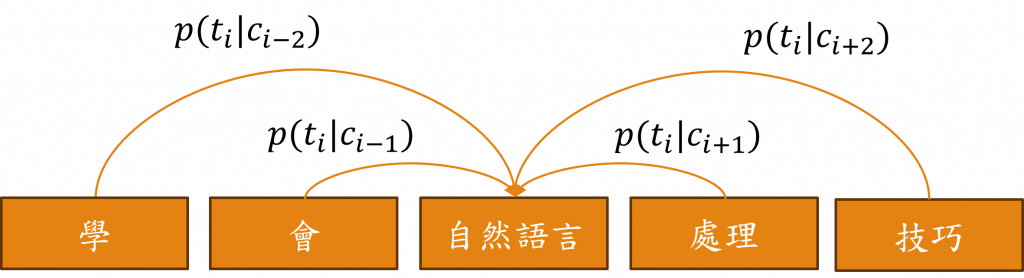
CBOW(Continuous Bag of Words)和Skip-gram是相反的方法,CBOW是基於上下文來預測目標詞彙,換句話說,Skip-gram是通過對每個上下文t(i)進行規划以導出c(i±j)的機率,而CBOW則是由c(i±j)反推出t(i)的機率,因此對於每個機率我們可以如此表示:
與Skip-gram不同的是因Skip-gram需要從t(i)中比對c(i±j)的機率,所以需要將兩者訊息拼接後計算出最後的機率,但CBOW的作法則相反因為我們只需要取得c(i±j)整體的語義資訊即可作為score()的計算公式,這邊我也簡單的舉出三種作法。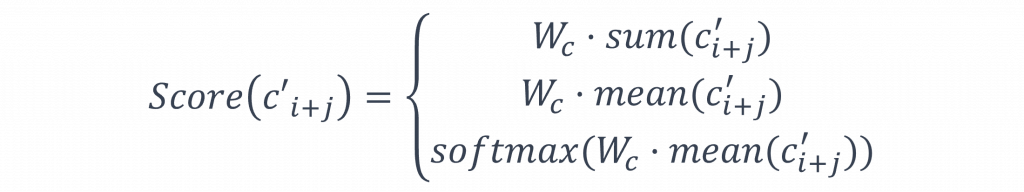
同樣的我們將以上的結果透過Pytorch將其實現出來,已加深你對該公式的印象。
(1) 加總方式
class CBOWModel(nn.Module):
def __init__(self, vocab_size, embedding_dim):
super().__init__()
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
self.linear = nn.Linear(embedding_dim, vocab_size)
def forward(self, context):
embedded = self.embeddings(context)
summed = torch.sum(embedded, dim=1)
output = self.linear(summed)
return output
(2) 平均方式
class CBOWModel(nn.Module):
def __init__(self, vocab_size, embedding_dim):
super().__init__()
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
self.linear = nn.Linear(embedding_dim, vocab_size)
def forward(self, context):
embedded = self.embeddings(context)
embedded_avg = torch.mean(embedded, dim=1)
output = self.linear(embedded_avg)
return output
(3) 機率計算方式
class CBOWModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, context_size):
super().__init__()
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
self.linear = nn.Linear(embedding_dim, vocab_size)
self.context_size = context_size
def forward(self, context):
embedded = self.embeddings(context)
embedded_avg = embedded.mean(dim=1)
output = self.linear(embedded_avg)
return F.softmax(output, dim=1)
這兩種方法各有其優劣如word2vec的作者Mikolov所述,Skip-gram能有效處理較少數量的數據,並且能更好地表達罕見的詞語。然而CBOW的計算速度卻更迅速,並且對於頻繁出現的詞語具有更佳的表達能力。
小提示:
Skip-gram的方法由於是基於少數推理大部分的思考方式,因此輸入的特徵訊息相對較少,相反地CBOW則是從大量資訊推理細節,因此它需要的輸入訊息相對較多,這也使得CBOW可以更好地獲得並理解文字周遭的情境訊息
而模型相較於現今的預訓練模型相比擁有較為簡單的結構,這是因為該模型出自2013年,當時的電腦設備並不如現今強大,因此我們現在仍有訓練出Word2Vec的可能性,而使用這種類型的預訓練模型時,我們主要會將其詞嵌入向量,取代我們自身的詞嵌入層,並對模型進行微調訓練,已取得一個更好的結果。
不過Word2Vec在句子中忽視了詞彙的順序信息,僅依據詞彙在文本語料庫中的共現頻率來學習詞向量,這樣的方式使得所有詞彙被視為具有相同的語義,導致在處理多意詞的效果上相較於時間序列模型表現較差,因此這也使後續的人針對這些問題對Word2Vec模型進行改良。
今天我主要講解了Word2Vec這個詞嵌入預訓練模型,而在這次的主題中我將主要闡述三種不同的詞嵌入預訓練模型,並在最後的部分透過實際任務,比較這三種模型的效能。因此內容將會分為(上)、(中)、(下)、(末)四個環節,其中(末)的章節中將會是一系列的程式學習環節,明天我將會告訴你另一個詞嵌入預訓練模型GloVe的特性與原理。
那麼我們明天再見!
內容中的程式碼都能從我的GitHub上取得:
https://github.com/AUSTIN2526/iThome2023-learn-NLP-in-30-days


 iThome鐵人賽
iThome鐵人賽