我們昨天提到,Word2Vec在分析句子時忽視了詞彙的順序信息,這是因為它並未考慮到整體詞彙的訊息而僅集中於局部,並且我們在講解Seq2Seq+Attention的階段,也曾經提到這種問題。
你可能會問為什麼這些方式都沒有考慮這些問題呢?其實原因很簡單,通常只考慮局部解的方法就能創造出大多數的有效演算法,然而全域解的產生往往是在優化這些局部解的基礎上得出的,所以今天我將會介紹優化Word2Vec的預訓練模型GloVe。
Glove介紹與實踐共現矩陣(Co-occurrence Matrix)的建構Glove(Global Vectors for Word Representation)是由史丹佛大學的研究團隊開發的詞嵌入技術,它透過統計大規模文本語料庫中詞彙之間的共現關係來學習詞嵌入層的權重,它的建立思想源自源我們先前所提及的Word2Vec還有將文件詞項矩陣(Document-term matrix)的SVD分解法,透過將這兩種方式進行結合與改良,使其能提升捕獲語義關係的能力,Glove的主要工作階段可以分為兩部份:共現矩陣的建立以及最佳化目標,接下來我將為你詳細介紹這兩項工作階段的原理。
小提示:
文件詞項矩陣是一種根據詞彙的出現頻率與詞彙的逆向檔案頻率(TF-IDF)所產生的矩陣,該方法透過將詞彙與其逆向檔案頻率進行計算從而得出詞彙的加權指數,而對其進行SVD分解的主要目的是將文件詞項矩陣進行降維處理,已提取區該矩陣中的詞彙特徵,該方法也是一種全局特徵的矩陣分解方法
在我們昨天探討t(i)與t(j)兩個字之間的關係時,是通過統計兩者附近相關訊息的方式進行的,然而正如我們昨日所提,這種方法難以解決一字多義的問題。因此GloVe依此進行了一些改良,它將數據輸入的計算不再依賴於單個詞彙,而是依賴於t(i)與t(j)的共現矩陣,使其更有助於考慮全域特徵,因此在第一步我們需要進行將詞換轉換成共現矩陣的動作,其詳細方式如下方的程式碼所示:
import numpy as np
# 1. 建立詞彙表
corpus = ["I like to play soccer", "Soccer is a fun sport", "I enjoy playing soccer"]
words = ' '.join(corpus).split()
vocab = list(set(words))
# 2. 初始化共現矩陣
co_occurrence_matrix = np.zeros((len(vocab), len(vocab)))
# 3. 定義前後窗口
window_size = 2
# 4. 計算數值並更新共現矩陣
for sentence in corpus:
tokens = sentence.split()
for i in range(len(tokens)):
for j in range(max(0, i - window_size), min(len(tokens), i + window_size + 1)):
if i != j:
word_i, word_j = tokens[i], tokens[j]
if word_i in vocab and word_j in vocab:
index_i, index_j = vocab.index(word_i), vocab.index(word_j)
co_occurrence_matrix[index_i][index_j] += 1
print(co_occurrence_matrix)
在上述程式碼中我們首先遍覽所有詞彙,並設定一個window_size用於記錄該詞彙前後文的出現次數,接下來透過這種方式統計不斷的加總結果並紀錄到共現矩陣中,當我們完成共現矩陣的建立時,就能夠找到第i個詞彙與第j個詞彙的共現次數。
在優化目標的過程中,該模型採用了一種全新的損失函數,具體操作方法是隨機抽取一個詞彙樣本k,並計算它和目標詞彙t(i)以及t(j)的關聯。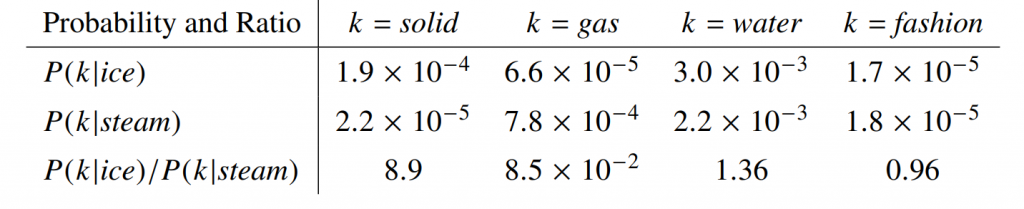
出自於:GloVe論文
我們以圖片中的solid(堅硬的)、gas(氣體)、water(水)及fashion(時尚)為例,分析它們與ice(冰)、steam(蒸氣)的詞頻關係,而我們能發現若詞彙k的關聯性數值與目標詞彙t(i)和t(j)數值較高,那麼該詞的則能作為第三方指標進行評估。
基於這原因我們可以計算P(k|t(i))與P(k|t(j))的比值,如果這比值接近於1,則代表詞彙k與t(i)和t(j)有正關聯或沒有關聯;反之如果比值遠超過1,則k可能與其中一個目標詞彙有較強的相關性,因此在進行模型訓練時,我們可以使用以下公式來表示這些文字的權重。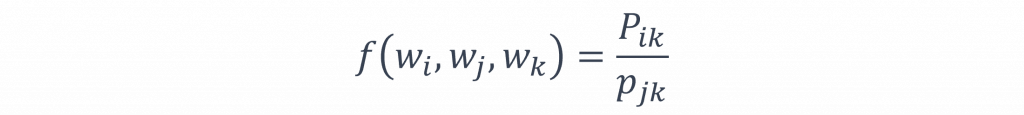
不過在上述的步驟中這些權重都是由k決定的,並且該方式無法在目標詞彙t(i)與t(j)之間形成明顯的線性關係,而一個有效的詞嵌入向量應當讓相似度越高的詞彙向量越接近,而相似度較低的則相對疏遠,但這種方法只考慮了與k的關係,卻忽視了t(i)和t(j)之間的線性關係,因此為了在這兩者間形成線性關係,論文中採用了以下的公式: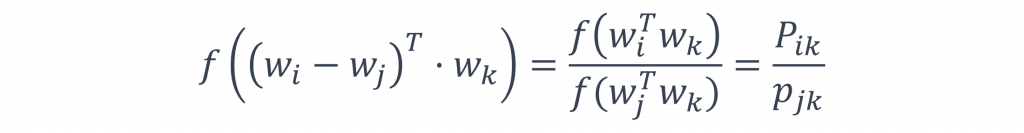
而在這公式中我們讓w(i)-w(j)使其能夠計算出兩者之間的距離,若w(i) > w(j)整體的向量空間會傾向於正軸移動,反之如果w(i) < w(j)則會向負軸移動,其中w(k)主要控制這兩種情況下目標詞彙間的移動距離,進而影響整體的向量空間
此外而在這個公式還有一個特別的地方就是它具有指數特性,因此基於這點我們可以如下表達該函數: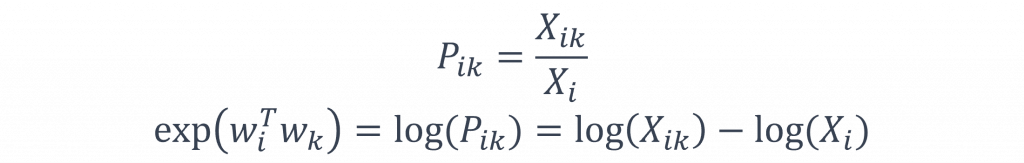
而在上述的公式中我們將會發現去掉log(X(i))後,該函式將會顯現出對稱性,其中log(X(i))因與k無關,因此我們可以將log(X(i))這一個定值轉換到w(i)的偏移量b(i)中,最後我們只需補上w(k)的對應偏移量b(k),便可以完成整個損失函數的設計。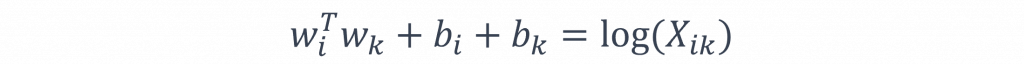
小提示:
log(X(i))能被轉入到偏移量b(i)中,這是由於X(i)和b(i)都是固定值。X(i)代表著我們的輸入,因此不會變動,其次b(i)是模型的偏移量,此值是模型的選擇條件,如同我們在經濟拮据的時候,我們會選擇較為價廉的餐廳,而b(i)就是模擬出這種拮据狀況的條件。
那麼在程式中該怎麼設計呢?在這邊我幫你把整個GloVe的模型用Pytorch重現出來了,我們可以看到以下的程式結果
class GloVe(nn.Module):
def __init__(self, vocab_size, embedding_dim):
super().__init__()
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
self.bias_target = nn.Embedding(vocab_size, 1)
self.bias_context = nn.Embedding(vocab_size, 1)
def forward(self, target, context):
embed_target = self.embeddings(target)
embed_context = self.embeddings(context)
bias_target = self.bias_target(target).squeeze()
bias_context = self.bias_context(context).squeeze()
dot_product = torch.sum(embed_target * embed_context, dim=1)
log_co_occurrences = torch.log(co_occurrence_matrix[target, context])
loss = torch.mean((dot_product + bias_target + bias_context - log_co_occurrences))
return loss
co_occurrence_matrix = torch.LongTensor([[0, 0, 1, 0, 1],
[0, 0, 0, 1, 0],
[1, 0, 0, 1, 1],
[0, 1, 1, 0, 0],
[1, 0, 1, 0, 0]])
vocab_size = co_occurrence_matrix.shape[0]
model = GloVe(vocab_size, embedding_dim)
target, context = np.where(co_occurrence_matrix > 0)
model(target, context)
在以上程式中,我們使用self.embeddings來表示w(i)和w(k),這樣做的原因是我們向模型提供的是一個共現矩陣,至於該模型的偏移量b(i)和b(k),我們分別使用了bias_target和bias_context來表示,最後我們透過sum()來將將i和k向量的信息重新整合,這時就能夠透過GloVe的損失函數進行計算,使其能夠達到最佳化目標值。
從程式設計的角度來看,GloVe所做的事情其實非常簡單,就是將輸入變成了共現矩陣,但也因為這樣我們必須考慮不同的損失函數計算方式,為此GloVe利用了第三個詞彙k來調整共現矩陣的資料分布,由此兩點疊加使能考慮到全面的訊息,不過這種方法有當然也有缺點,就是無法理解資料的詞性,所以我將在明天介紹另一種詞嵌入的預訓練模型,以理解文字中的詞性。
那麼我們明天再見!
內容中的程式碼都能從我的GitHub上取得:
https://github.com/AUSTIN2526/iThome2023-learn-NLP-in-30-days


 iThome鐵人賽
iThome鐵人賽