前言:
今天要跟大家介紹權重初始化(Weight Initialization),並且嘗試用不同權重初始化方式來大帶大家認識。
權重初始化通常會是解決神經元飽和的方法之一。當神經元使用某些激活函數(如Sigmoid或Tanh)時,它們在輸入值較高或較低(極端值)的情況下容易飽和(這部分我們在第十天Sigmoid 函數有稍微提到,忘記的話可以再回去複習),這可能導致梯度消失問題(梯度消失的問題我們也會在之後跟大家說明如何解決),使得神經網路難以訓練。
值得注意的地方是,選擇權重初始化方法應該根據模型結構和所使用的激活函數來考慮。當使用Sigmoid或Tanh激活函數時,不建議將權重初始化設置得很大,因為這樣做可能會在初始階段使神經元的輸出超出激活函數的飽和區域,進而導致梯度爆炸問題(梯度變得非常大,導致權重更新極端,訓練變得不穩定)。
這邊會帶大家用兩種分布去設定權重初始值,一種是標準常態分佈,另一種是Glorot分佈(明天會跟大家介紹),話不多說直接看程式碼!
有寫註解的地方為有新增程式碼的地方,記得補上喔!
from tensorflow.keras.datasets import mnist
from tensorflow.keras.layers import Dense,Activation #Activation(激活函數層)
from tensorflow.keras.models import Sequential
from tensorflow.keras import optimizers
from tensorflow.keras.utils import plot_model
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.initializers import Zeros,RandomNormal #用於初始化神經網絡層權重的初始化器
import numpy as np
import matplotlib.pyplot as plt
這邊開始設定我們的權重
b_init=Zeros() #我們將密集層的偏值(bias)設為0,Zeros()初始化器將偏差初始化為0。
w_init=RandomNormal(stddev=1.0) #設標準差為1,用標準常態分佈來初始化權重
#建立輸入資料跟密集層的神經元
n_dense=256
n_input=784
建構神經網路
model=Sequential()
model.add(Dense(n_dense,
input_shape=(784,),
#這邊也可以寫input_dim=n_input,它們的作用是相同的,用於指定輸入層的特徵數量
kernel_initializer=w_init
#kernel_initializer : 指定權重參數 w 初始值,前面我們設定為標準常態分佈
bias_initializer=b_init))
#bias_initializer : 指定偏值參數 b 初始值,前面我們設定為0
model.add(Activation('sigmoid'))
補充說明:model.add(Dense(10, activation='sigmoid')) 和 model.add(Activation('sigmoid'))
model.add(Dense(10, activation='sigmoid')):
activation='sigmoid' 參數指定了該層使用Sigmoid激活函數。該層的神經元將使用Sigmoid函數來計算其輸出。model.add(Activation('sigmoid')):
Activation('sigmoid') 指定了該激活層使用Sigmoid激活函數,但它不包含神經元。它只是將前一層的輸出通過Sigmoid函數進行轉換。第一行我們把隨機產生的浮點數當作輸入資料,第二行為資料傳入密集層
x=np.random.random((1,n_input)) #n_input=784,生成784個隨機數,每個數字都是在0到1之間的隨機浮點數
a=model.predict(x) #執行神經網絡模型的預測操作,模型對 x 的預測結果存在變數a
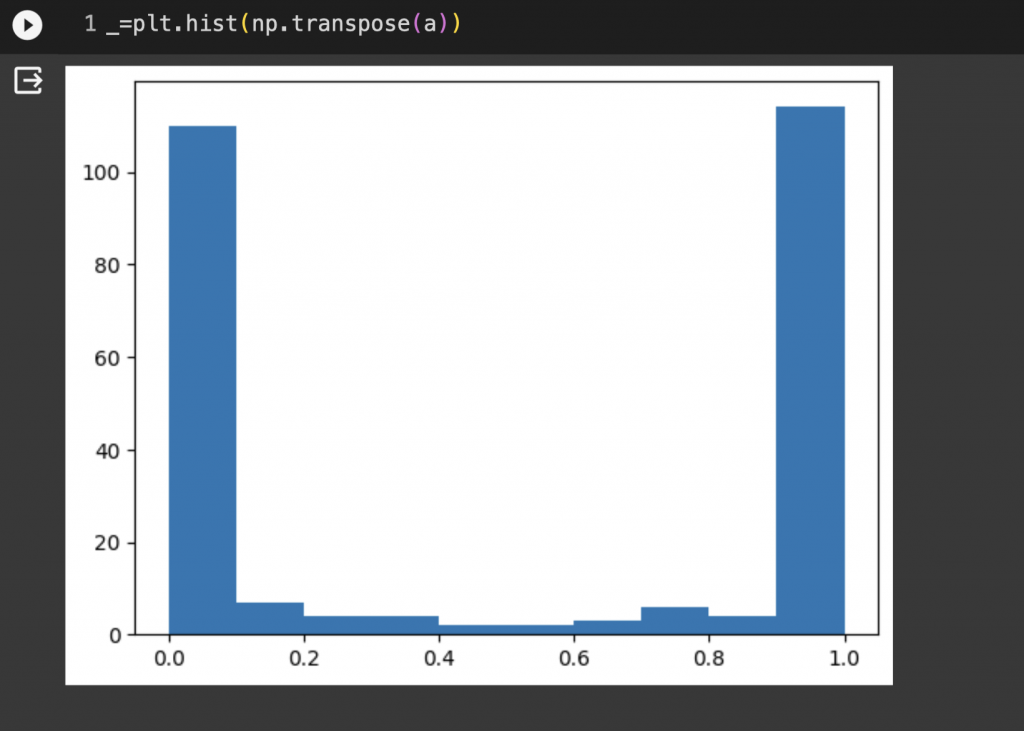
可以從圖片看出來大部分的數值都會0跟1兩端靠攏,說明神經層中大部分的神經元都已經飽和,言外之意這會使得我們訓練變得困難,明天就來帶大家看不同權重初始化的結果。
_=plt.hist(np.transpose(a)) #直方圖呈現,統計數值分佈
最後我們來看用這個權重初始化跑MNIST手寫資料集的結果,這次設定訓練20次,跑出來成效蠻差的正確率只有42%
#匯入套件
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
from tensorflow.keras import optimizers
from tensorflow.keras.utils import plot_model
from tensorflow.keras.utils import to_categorical
import matplotlib.pyplot as plt
import numpy as np
from tensorflow.keras.initializers import Zeros, RandomNormal
#下載mnist資料集
(X_train, y_train), (X_test, y_test)=mnist.load_data()
#資料預處理
X_train=X_train.reshape(60000, 784).astype('float32')
X_test=X_test.reshape(10000, 784).astype('float32')
X_train /= 255
X_test /= 255
y_train=to_categorical(y_train, 10)
y_test=to_categorical(y_test, 10)
#建構神經網路
b_init=Zeros()
w_init=RandomNormal()
model=Sequential()
model.add(Dense(64,input_dim=784,kernel_initializer=w_init,bias_initializer=b_init))
model.add(Activation('sigmoid'))
model.add(Dense(10, activation='softmax'))
#編譯模型
model.compile(loss='mean_squared_error',
optimizer=optimizers.SGD(learning_rate=0.01),
metrics='accuracy')
#訓練模型
model.fit(X_train, y_train, batch_size=128, epochs=20, verbose=1,validation_data=(X_test, y_test))

