技術文章
技術問答
iT 徵才
聊天室
2026 鐵人賽
登入/註冊
文章
問答
Tag
邦友
鐵人賽
搜尋
2023 iThome 鐵人賽
DAY
24
0
AI & Data
嘗試在AI世界闖蕩
系列 第
24
篇
Day 24 AI核心應用:自然語言處理(語言模型、BERT)
15th鐵人賽
tiffanyxxx32
團隊
臣無禮
2023-10-09 10:11:21
765 瀏覽
分享至
語言模型Language Model
一個模型透過對人類文字使用大量的學習後,一個能合理預測下一個詞句、能架構出順暢文句。
傳統主要的模型:N-gram、TF-IDF、Word2 Vector
大型語料庫訓練模型:ELMO、ULMfIT、GPT-2、XLM、BERT、GPT-3
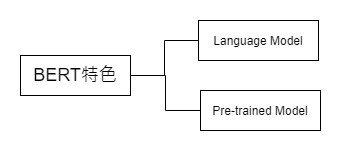
BERT(Bidirectional Encoder Representations from Transformers)
Transformer的雙向編碼器。
一個基於微調Fine Tune、雙向Bidrection、多層Multi-Layer Transformer的Encoder。
利用無監督式學習的一個大型通用預訓練語言模式Pre-trained Language Model。
Google在2018年9月推出,為目前最有力的預訓練語言模式。
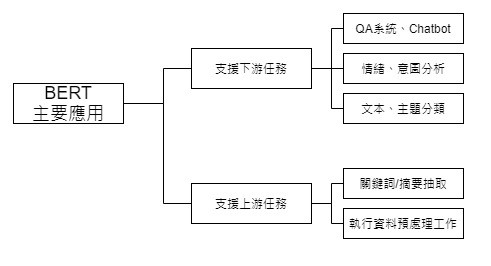
可以當成許多下游任務的基礎工程(利用BERT所學習到的高品質的詞向量來支援後面的下游任務)。
目前所有相關NLP任務的最有效率做法。
主要架構:利用Transformer的Encoder模組可分為:①BERT(Base):有12層,每層有12個Attention Head共有1.1一個參數。 ②BERT(Large):有24層,詞向量1024維度,每層有16個Attention Head,共有3.4一個參數。
訓練資料:包括Wikipedia+Bookcorpus(11038本)加上FB(Meta)共33億個字。
訓練方式:
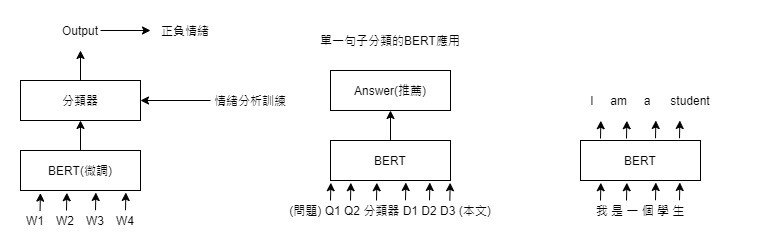
➊詞層次Word Level的克漏字填空Masked Language Model(MLM):再輸入的文本中隨機掩蓋Mask每個句子中15%的詞,訓練由左右兩邊的詞句來預測中間被掩蓋的詞,如此訓練就可得到中間詞前後左右雙向的依賴關係Bidirection Relationship,並解決同詞異義的問題。
➋句子層次的下一句預測,即NSP(Next Sentence Prediction):許多任務,像是:問答系統、聊天機器人、詩詞創造,都需要語言模式具備此功能。在input的句子後下一個句子視為正確的正樣本Positive Sample,然後NSP再隨機由文本抽取一個其他句子視為錯誤的負樣本Negative Sample。
優勢:
①Transformer優勢:利用平行、聚焦、直接對應速度快的Transformer Model及其所具備的自我注意力機制優點。
②詞層次深入的理解詞意:利用MLM以及自我注意力SATT兩個重要機制。
③句子層次的深入了解句子與句子之間的關係:利用NSP Model。
④非監督式學習:採用成本低、獲取容易、可大量蒐集、不用標註、不用做預處理的一般通用語料。
主要貢獻、應用:
①取代傳統複雜的NLP預處理工作
②取代部份的下游任務的工作
特色:
🔼BERT以預訓練模式的方式支援各種不同的任務
參考來源:人工智慧:概念應用與管理 林東清
留言
追蹤
檢舉
上一篇
Day 23 AI核心應用:自然語言處理(AM、Transformer)
下一篇
Day 25 AI核心應用:自然語言處理(GPT-3、LM未來)
系列文
嘗試在AI世界闖蕩
共
31
篇
目錄
RSS系列文
訂閱系列文
6
人訂閱
27
Day 27 AI的核心應用:電腦的聽覺與視覺(TTS、、Real Time Voice Cloning、CV)
28
Day 28 AI的核心應用:電腦的聽覺與視覺(圖像分析/分類/分割/定位、物件偵測)
29
Day 29 AI的核心應用:電腦的聽覺與視覺(R-CNN、YOLO)
30
Day 30 AI的核心應用:電腦的聽覺與視覺(視頻分析、行動辨識)
31
技術篇 Day 1-Iris_classification
完整目錄
熱門推薦
{{ item.subject }}
{{ item.channelVendor }}
|
{{ item.webinarstarted }}
|
{{ formatDate(item.duration) }}
直播中
立即報名
尚未有邦友留言
立即登入留言
iThome鐵人賽
參賽組數
902
組
團體組數
37
組
累計文章數
19838
篇
完賽人數
528
人
看影片追技術
看更多
{{ item.subject }}
{{ item.channelVendor }}
|
{{ formatDate(item.duration) }}
直播中
熱門tag
15th鐵人賽
16th鐵人賽
13th鐵人賽
14th鐵人賽
17th鐵人賽
12th鐵人賽
11th鐵人賽
鐵人賽
2019鐵人賽
javascript
2018鐵人賽
python
2017鐵人賽
windows
php
c#
linux
windows server
css
react
熱門問題
趣味SQL,給了一組編號後,用SQL產生亂數編碼的結果(更新Copilot及Google AI見解,SQL只能貼圖)
關於ASUS RS100-E11-PI2的磁碟陣列
已解決已解決
AI會議轉錄如何盡可能縮小明文攻擊面?
熱門回答
關於ASUS RS100-E11-PI2的磁碟陣列
趣味SQL,給了一組編號後,用SQL產生亂數編碼的結果(更新Copilot及Google AI見解,SQL只能貼圖)
熱門文章
AI 推論正在吞噬雲端
用 AI 寫 MCP server 很快就會跑,但「會跑」不等於「安全」——多租戶隔離的五條 best practice
Memory 系統 — 讓 Claude 不只記得「專案」,還記得「你」
[Tedium Is Stability-01] 結構性的不安:AI 幫你把功能寫完了,你為什麼還是不放心?
Agent 寫的 code 要怎麼 review?先看它到底改了什麼
IT邦幫忙
×
標記使用者
輸入對方的帳號或暱稱
Loading
找不到結果。
標記
{{ result.label }}
{{ result.account }}


 iThome鐵人賽
iThome鐵人賽