過度配適(Overfitting)是指機器學習模型在訓練過程中過度擬合訓練數據,例如:練誤差很低,但測試誤差很高、損失值(Loss)不減反增。這些情況會導致機器學習模型在新的、未見過的數據上表現不佳。
下面畫出來的直線與資料的擬合度很低,無法解釋大部分的資料點的分佈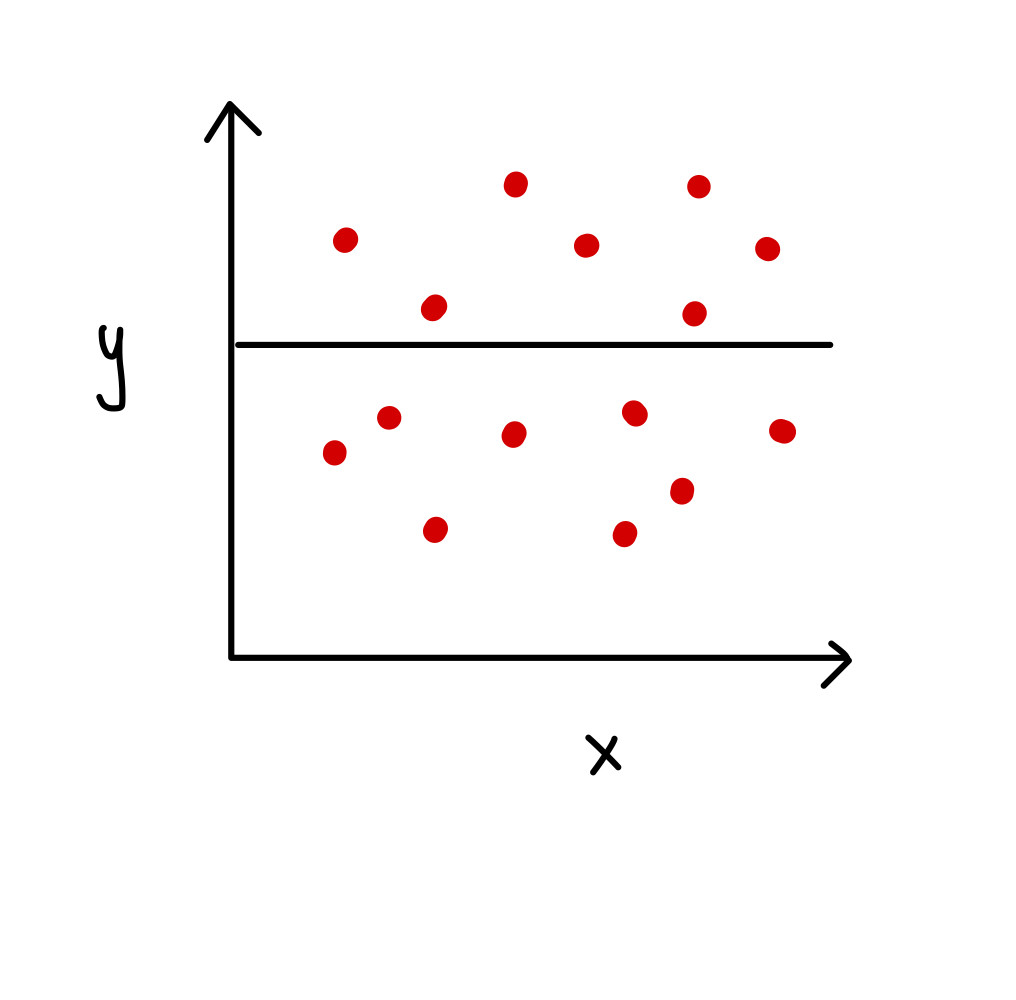
如果我們將模型改得稍微複雜一點,讓其學習力增加(改畫拋物線),可以發現能解釋的點比上一張圖還多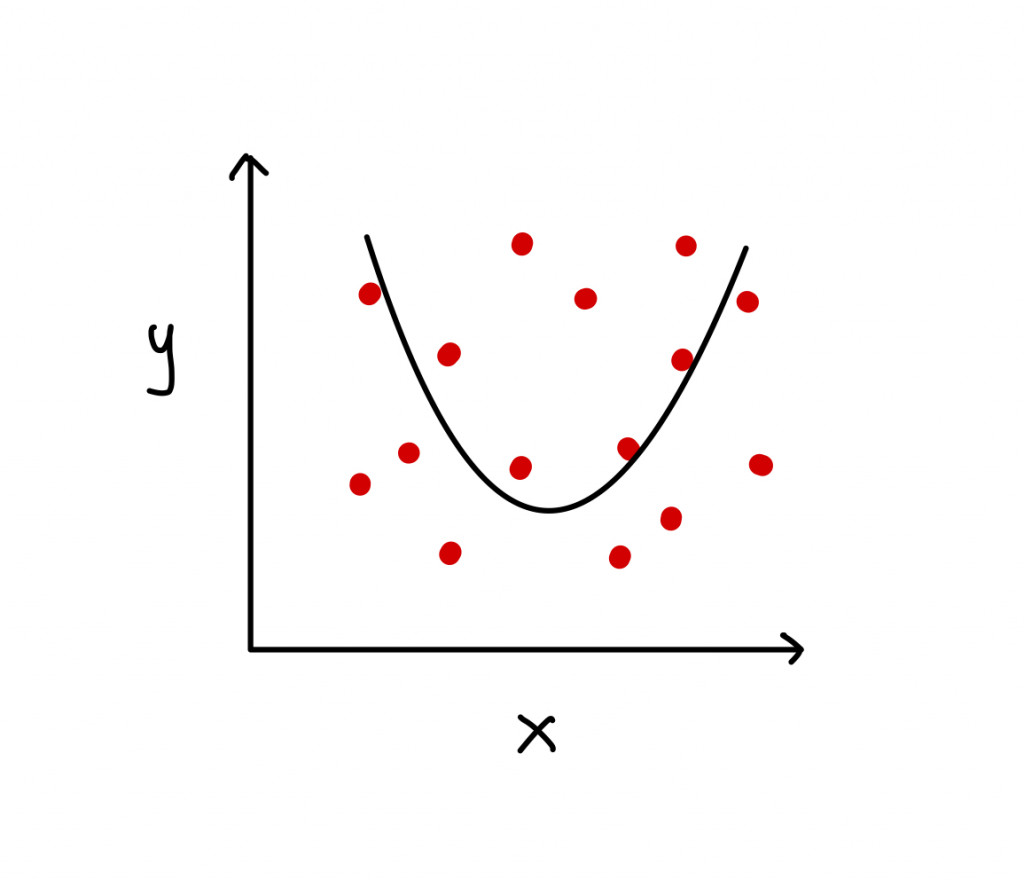
如果我的曲線可以完美穿過每一個資料點,也就是訓練出來的模型可以完全解釋每一個數據,這是一個好現象嗎?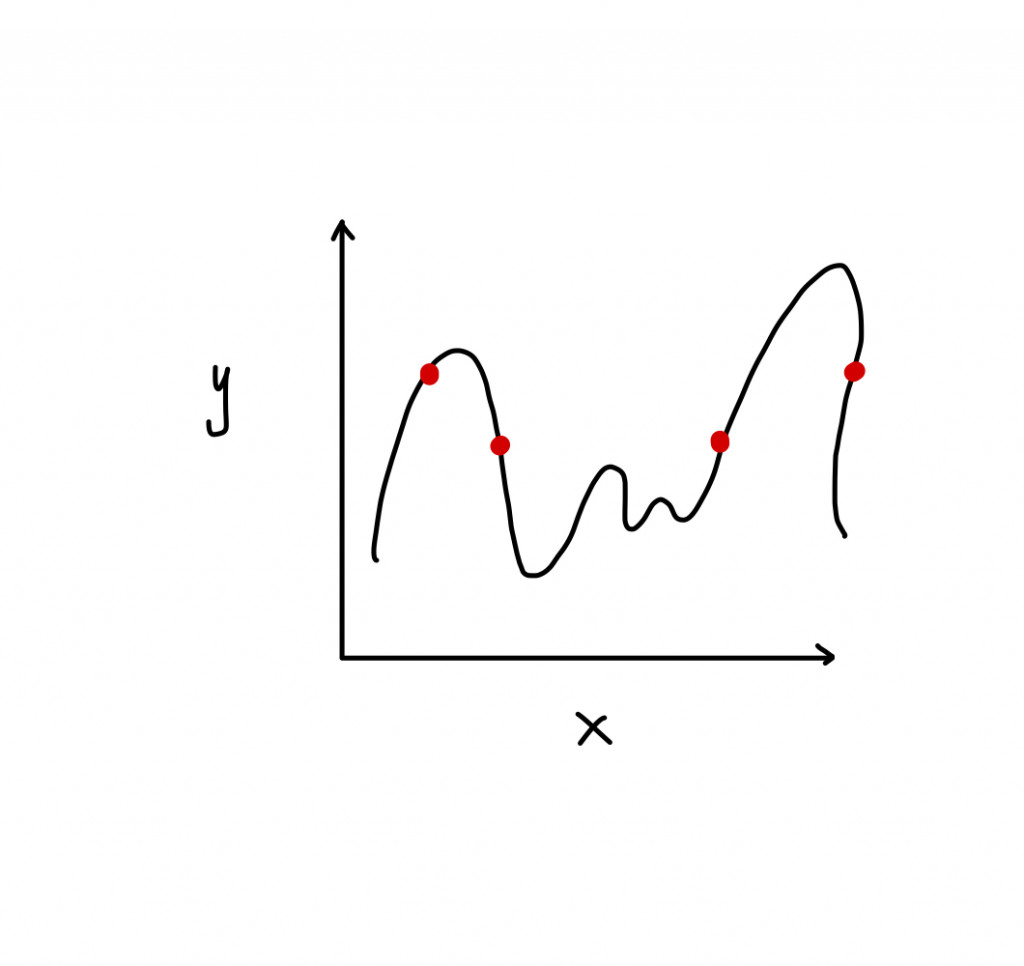
如果我又再多餵一些新資料進去給模型,觀察一下我的資料也會在線附近嗎?可以發現模型對新資料的擬和度很差,這就會是一個過度配適(Overfitting)現象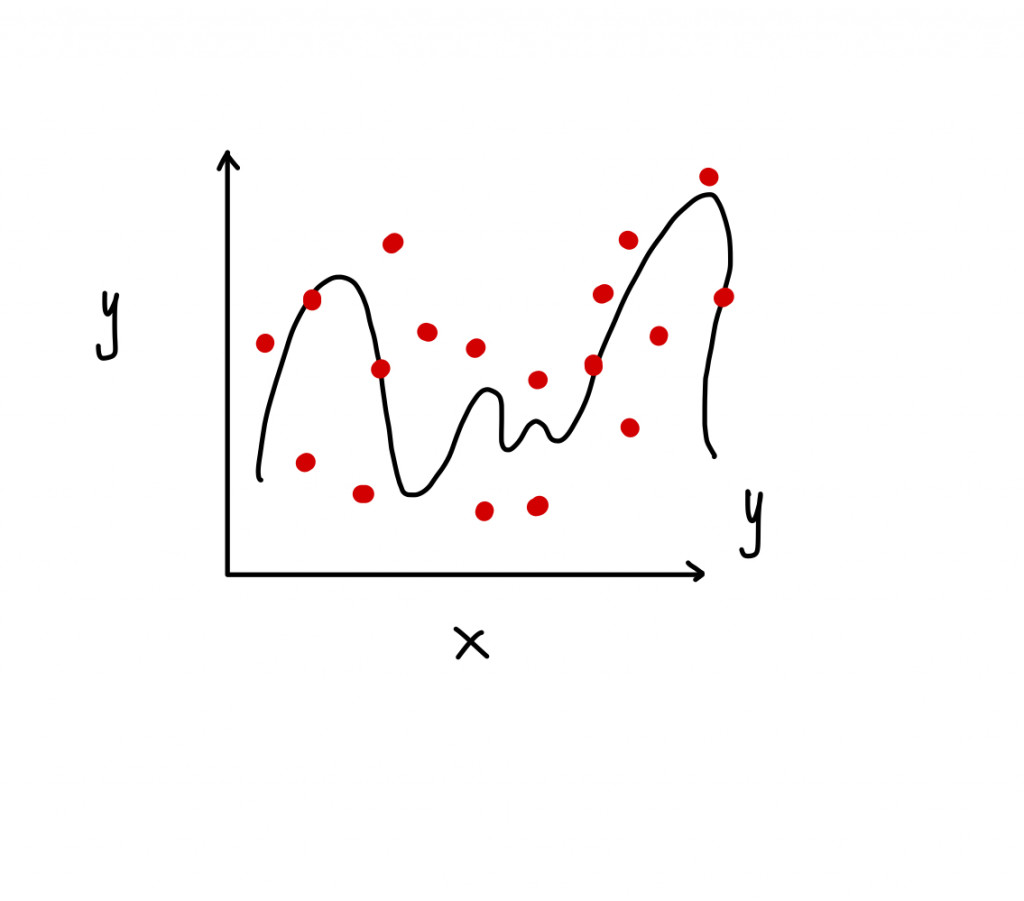
由上面的例子可以得到如果樣本數少,且模型設計過於複雜(參數太多),就可能會導致過度過度配適
抑制過度配適(over-fitting) 常使用下列方法 :
L1 常規化 (regularization) : 又稱 LASSO 迴歸
L2 常規化 (regularization) : 又稱 ridge 迴歸
L1 常規化跟L2 常規化這兩種方法都是在損失函數中添加懲罰項 (penalty term),在訓練神經網路時,如果神經層的參數值越大就給予越大的懲罰,這樣神經網路就會知道要往參數值較小的方向優化。L1 的損失懲罰項為權重取絕對值後之總和;而 L2 的損失懲罰項則為權重的平方和
丟棄法 (dropout):是業界人士最常用的方法之一,丟棄法的概念是在每一批次 (batch) 的訓練中,隨機地關閉一些神經元,也就是隨機將該層一定比例的神經元設為 0。
Q:丟棄法為什麼可以抑制過度配適(over-fitting)呢?
A:因為這會讓神經網路變成只依賴少數神經元在做計算,那些被關閉的神經元在正向傳播和反向傳播過程中就不會參與,這樣可以降低模型特定依賴某幾種特徵。
訓練回合一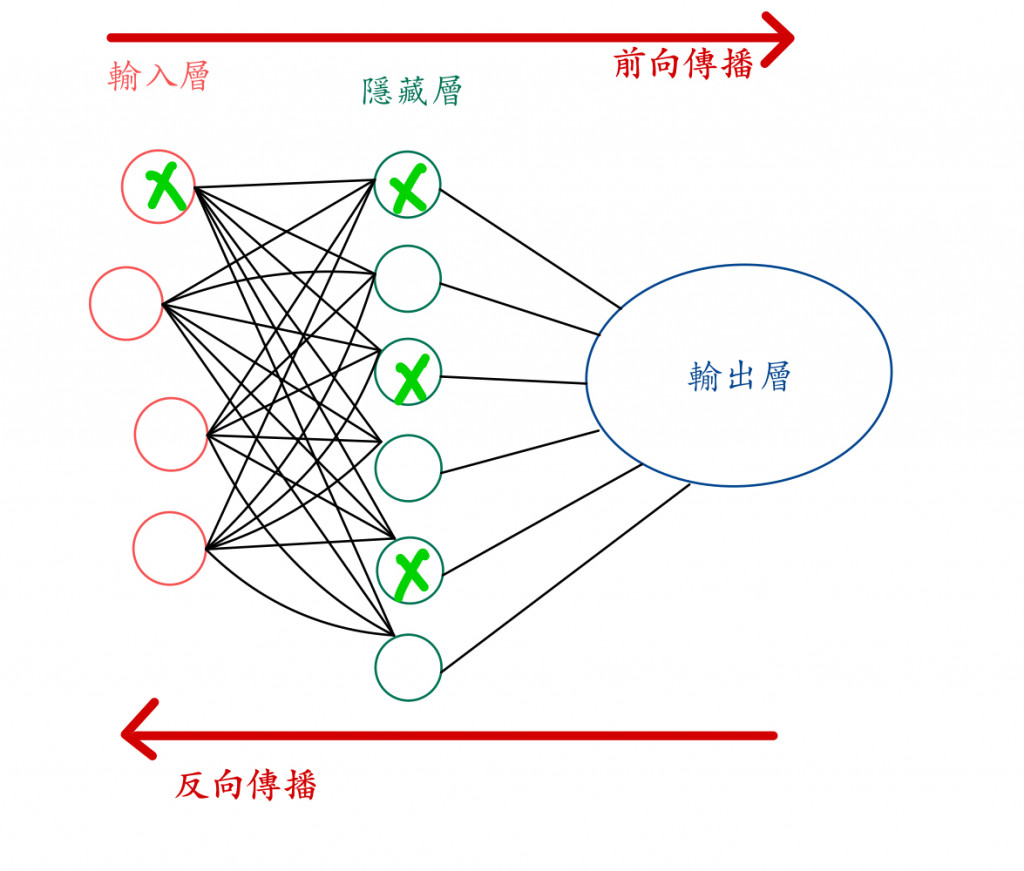
訓練回合二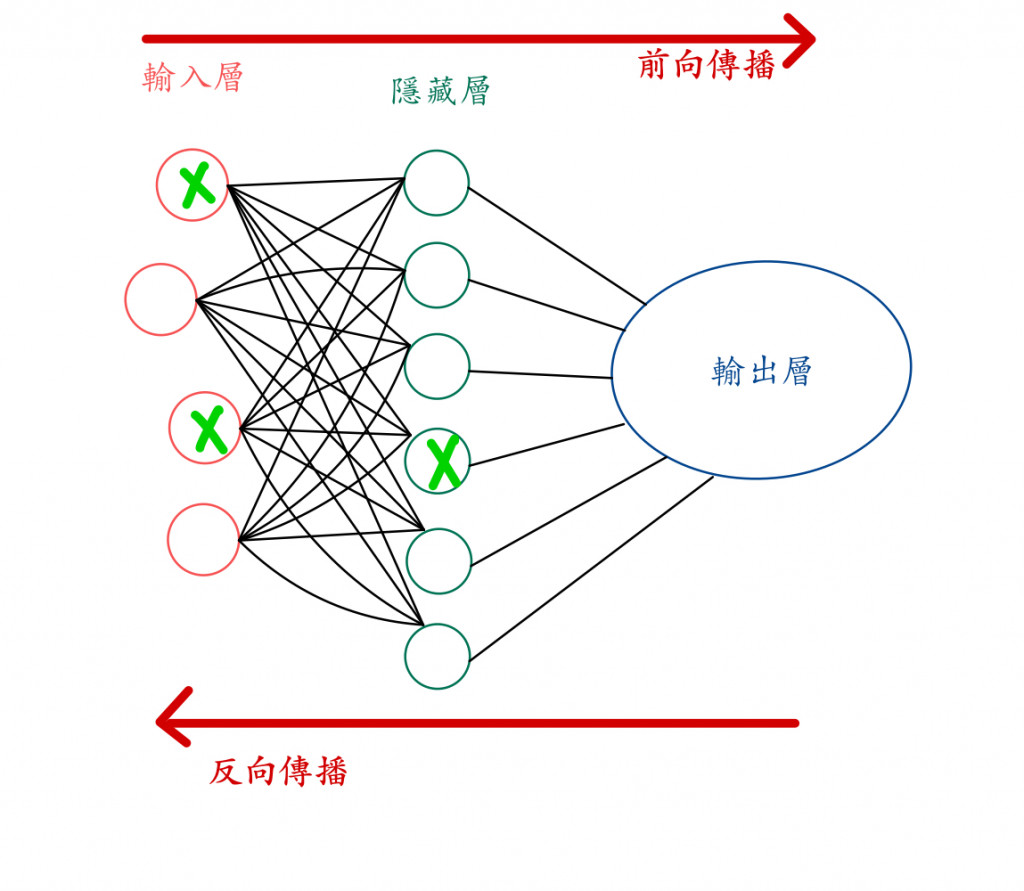
訓練回合三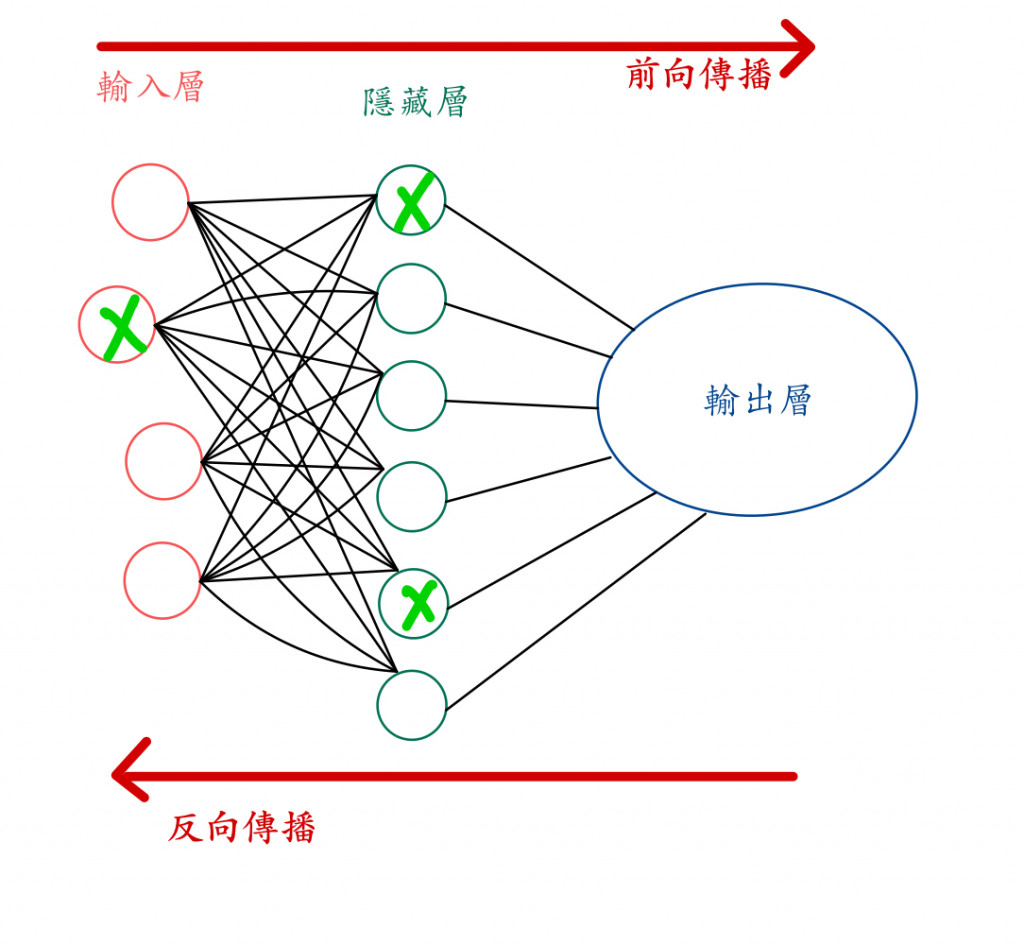
👆不同訓練回合忽視不同神經元
丟棄法要注意的地方:
丟棄率(Dropout Rate)的選擇:丟棄率是指在每一層中隨機關閉神經元的比例。一般來說,一開始我們會將丟棄率設在0.2到0.5之間。較小的丟棄率通常用在較小的神經網路,較大的丟棄率則用於更深或更大的網路。
不要強行使用:不用強行每一層都要加入丟棄法(Dropout)
考慮批次正規化(Batch Normalization):將我們昨天提到的批次正規化(Batch Normalization)與丟棄法一起使用時,可以進一步提高模型的性能和穩定性。
我們也可以增加訓練的資料,但有時候要我們突然收集到一大筆資料還是有些困難,所以我們會用生成的方式大量「人造」資料,藉以彌補因資料不足而造成之過度配適問題。以手寫數字為例子,我們可以通過一些方式創建人造資料:
變換筆跡風格
模擬角度和傾斜
合成數字
改變亮度、對比度、大小或色調

