在龐大的分散式系統中,問題排除是一大挑戰。如果缺乏適當的工具,在龐雜的系統排除問題時效率會極度低落,例如我們只能使用 Log 來查找問題時,就要耗費大量時間去翻查數十甚至數百份不同服務的 Log。因此隨著分散式系統架構的蓬勃發展,Distributed Tracing(分散式追蹤)的重要性也逐漸被重視。
Distributed Tracing 的演變歷程
- Google Dapper:在 2010 年,Google 公開了他們在生產環境中使用的 Distributed Tracing 系統,名為 Dapper。這篇論文中的許多概念,如 Trace ID、Span、Sampling,都被後來的 Distributed Tracing System 廣泛採用,可以視為 Distributed Tracing 的開山鼻祖。
- Twitter Zipkin:到了 2012 年,Twitter 開源了他們的 Tracing System — Zipkin,這是第一個開源的 Tracing System,它提供了完整的 SDK、Trace 資訊收集、儲存、查詢等功能。
- Uber Jaeger:2015 年,Uber 也跟進開源了他們的 Tracing System Jaeger,一樣提供了完整的 SDK、Trace 資訊收集、儲存、查詢等功能。
通用 Tracing API 的發展
為了讓 Tracing 能夠更加易用和通用,於是出現了一系列跟 API 和 SDK 相關的專案:
-
OpenTracing:2015 年,由 Lightstep 的創辦人 Ben Sigelman 和 Jaeger 的作者 Yuri Shkuro 等人共同發起 OpenTracing,旨在建立一個通用的 Tracing API。2016 年 10 月,OpenTracing 加入了 CNCF 成為其第三個專案
-
OpenCensus:2017 年,Google 提出了 OpenCensus,目標與 OpenTracing 類似。
-
OpenTelemetry:2019 年,OpenCensus 和 OpenTracing 合併成為 OpenTelemetry,並成為 CNCF 的專案。作為兩者的結合它一樣訂定統一的 API 與提供各種語言的 SDK,並且將收集的資料從 Trace 擴大到了 Metrics 與 Log,並將三者統稱為 Telemetry Data。

Trace 資訊的處理流程
經過多年的發展與整併 OpenTelemetry 已成為 Tracing 的業界標準,它主要包含以下元件:
- OpenTelemetry 所有元件的規格
- Telemetry Data 的格式與其傳輸方式的通訊協定 OpenTelemetry Protocol
- Telemetry Data 中各種資訊的命名規則 Semantic Conventions
- 針對不同語言的 SDK,實作 OpenTelemetry 的規格、API 與資料傳輸等功能
- 完整的套件生態系,可以快速的將 OpenTelemetry 整合到現有的套件與框架中
- 能夠轉發與處理 Telemetry Data 的 OpenTelemetry Collector
透過 OpenTelemetry 提供的內容,開發者可以快速的將 Tracing 整合到現有的系統中,並且將資料傳送至各種不同的 Tracing System 作為儲存 Trace 資訊的 Tracing Backend。
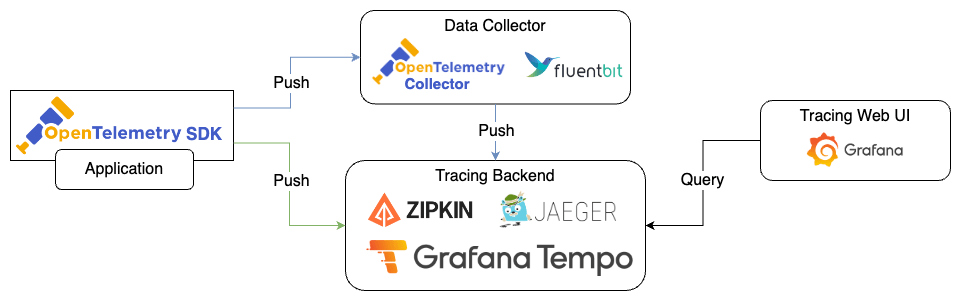
以下將以 OpenTelemetry 為例,介紹 Trace 資訊的處理流程。
生成
開發者可利用 OpenTelemetry 的 SDK,自動或手動地生成 Trace 和 Span。其格式遵循 W3C Trace Context 的規範。SDK 將在特定的程式執行階段(如 HTTP 請求或資料庫查詢)自動插入追蹤代碼,或允許開發者手動創建 Spans。
一個 Trace 通常包含多個 Spans,這些 Spans 通過一個統一的 Trace ID 進行連結。每個 Span 還具有自己的 Span ID,並在 Span 內記錄了多種資訊,例如開始時間、結束時間、耗時、標籤和事件等。
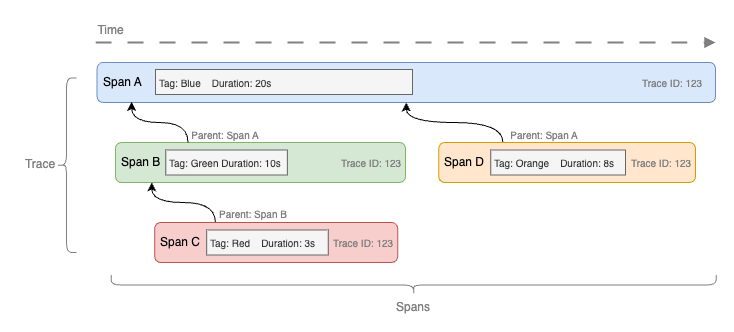
收集
使用 OpenTelemetry 時,SDK 負責將 Trace 資訊送出。這些資料會按照 OpenTelemetry Protocol 的規定,通過 gRPC 或 HTTP 進行傳輸,通常會選擇使用 gRPC,因為它基於 HTTP/2,更加高效。
在簡單的情境中資料被送到各種 Tracing Backend,如 Zipkin、Jaeger、Tempo 等,這些後端負責收集和存儲 Traces 資訊。若有特殊需求,資料也可能經過資料處理器,如 OpenTelemetry Collector、Fluent Bit 等進行加工或篩選,然後再轉發到 Tracing Backend。
儲存
根據選擇的 Tracing Backend,Trace 資料會儲存到不同的資料庫或儲存工具中:
- Zipkin:支援 Cassandra、Elasticsearch 和 MySQL。
- Jaeger:主要使用 Cassandra 和 Elasticsearch。
- Tempo:使用 Object Storage,例如 Amazon S3 或 Google Cloud Storage。
使用
Tracing Backend 通常提供專屬的 UI,方便用戶查詢和分析 Trace 資訊:
- Zipkin UI:搭配 Zipkin 使用
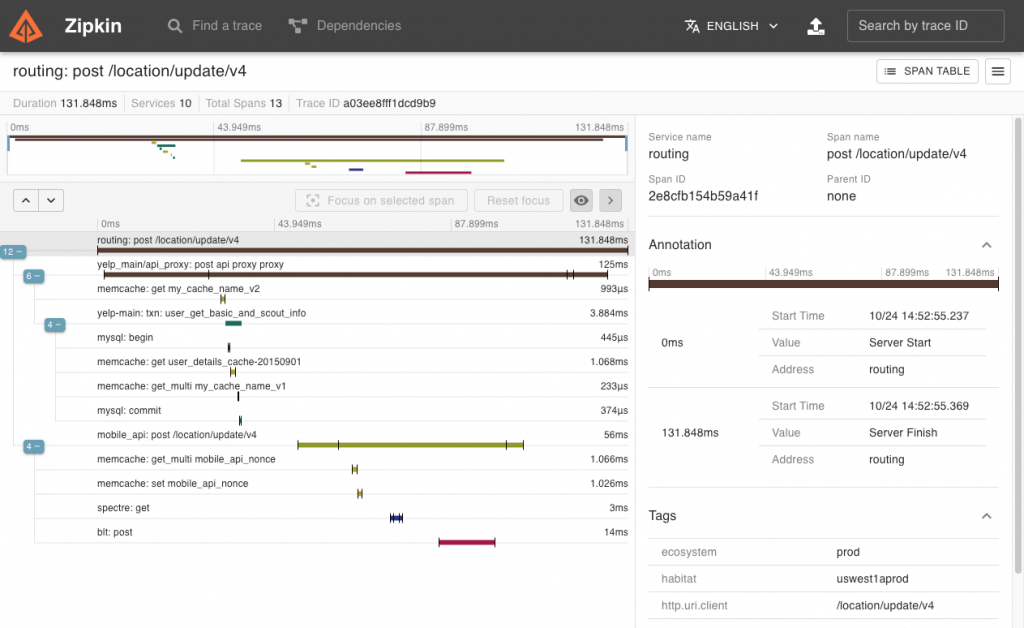
圖片來源:Zipkin
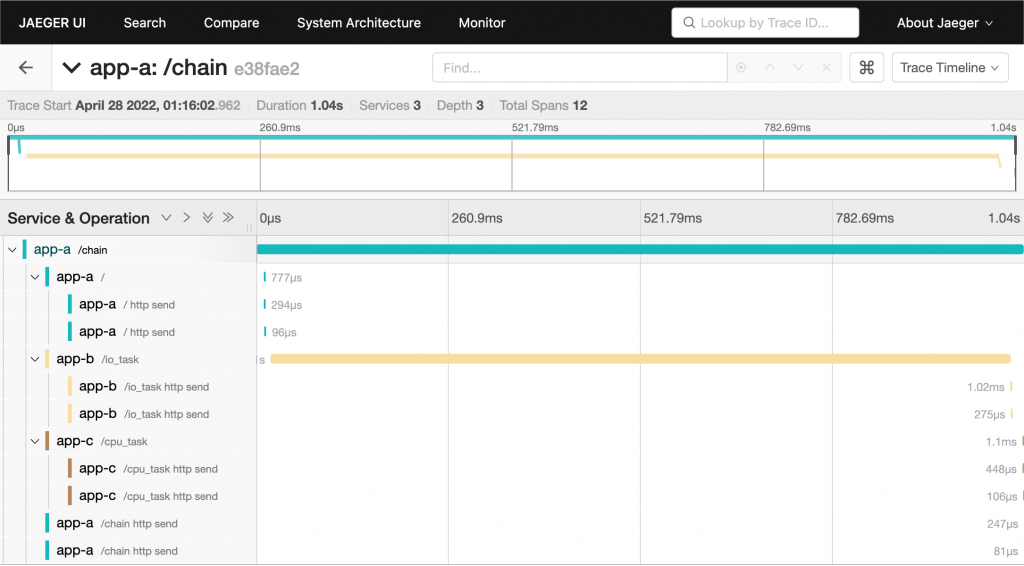
- Jaeger UI:搭配 Jaeger 使用
- Grafana:可以檢視 Zipkin、Jaeger、Tempo 的資料
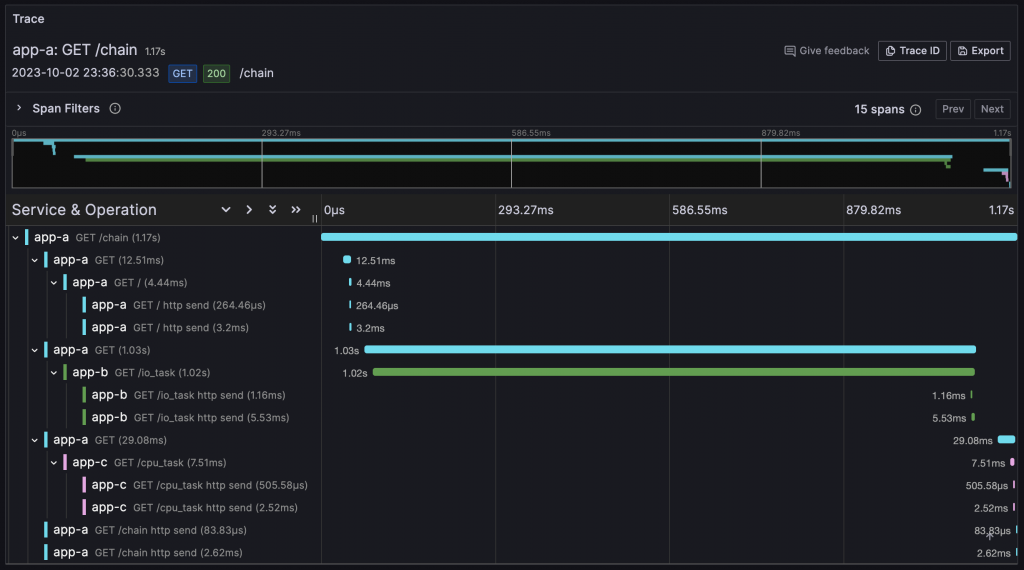
通過這些 UI,使用者不僅可以查詢和分析 Traces,還能更深入地理解系統的運行狀態。
小結
Tracing 在經過十多年的發展後,已經漸漸走向成熟。特別是 OpenTelemetry 的出現,使得整個 Tracing 生態系統更加完善。無論使用哪種語言透過 SDK 就能夠生成和發送 Trace 資訊,這大大簡化了開發的工作。不僅如此,目前市面上有超過 40 家的服務商都已經支援 OpenTelemetry Protocol,使得整合變得更加容易,未來若要切換也可以輕鬆的將資料轉移到其他服務商。
參考資料
-
A History of Distributed Tracing
-
Tracing the History of Distributed Tracing & OTel
-
OpenTelemetry

