我們之前提到的幾項技術都有其獨特的問題,例如word2vec常常會忽視詞彙的順序信息,而GLoVe則無法充分理解資料的詞性,至於時間序列模型則只能學習到下一個詞彙表示,不過在這些模型中還有一個相同的問提就是他們無法根據上下文調整詞嵌入向量,雖然他們能將相似語意的詞放在一起,但最終還是會偏向於特定向量,以GLoVe中的「Play」詞彙為例,該詞的向量會傾向於「運動」的語意。
而在理想的狀況應是根據上下文來動態的調整每個詞彙的向量位置,而這種概念也是最新的自然語言處理技術中的關鍵之一,因此我們今天的重點將會如下:
ELMo中的詞嵌入方式
Contextualized Word Embedding(上下文詞嵌入)的理解基於特徵(base-feature)與微調(fine-tine)的預訓練模型區別
ELMO(Embeddings from Language Models)是一種利用雙向雙向LSTM來學習每個詞彙在特定上下文中的向量的方法,它與一般的雙向LSTM不同的是它的LSTM層具有權重共享的特性,並且每一個詞彙都自己的詞嵌入向量,因此每一個詞彙能夠根據它的上下文能計算出不同詞嵌入空間,現在我們來看看該模型的實現方式。
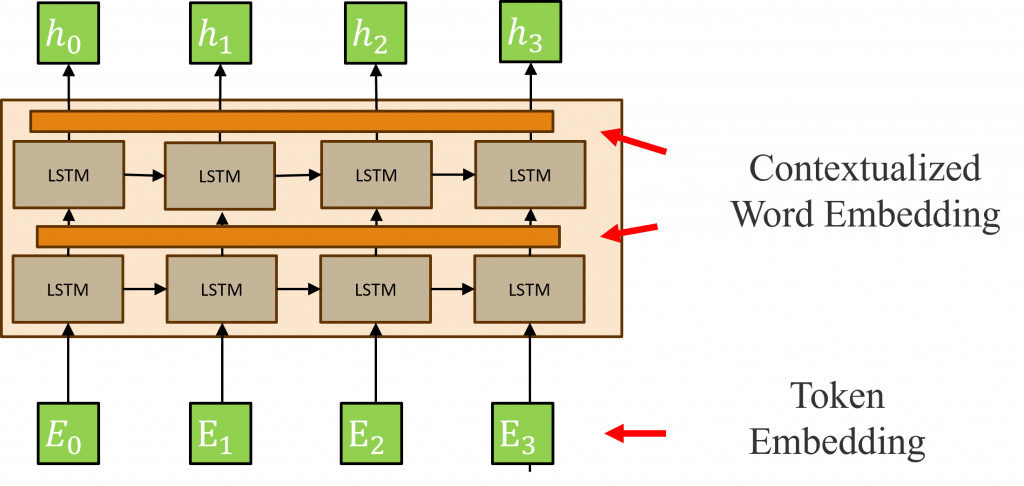
ELMo的詞嵌入與先前的詞嵌入層不同,它主要具備三個詞嵌入層以對應這些不同的特性,最底部的詞嵌入層被稱為Token Embedding(詞彙的詞向量),它針對每一個詞彙產生出不同的詞嵌入向量。
第二、第三的詞嵌入層則是分別對應該詞彙經過第一與第二層LSTM計算出來的隱狀態的詞向量,在這兩層中主要學習的是每一個隱狀態所理解的上下文意義,也就是說ELMo的預訓練過程不僅學會單字的Token Embedding,還會學習到一個雙層雙向的LSTM網路結構,而這兩層的詞嵌入被稱為Contextualized Word Embedding(上下文詞嵌入)。
由於ELMo的詞嵌入層是針對每個詞彙建構,因此在模型輸出時一個詞彙會有多個Contextualized Word Embedding,但這樣做會導致單個詞彙的表示變得更加豐富,因此ELMo的方法是將這些Contextualized Word Embedding進行加權總和以結合它們的訊息,其作法如下:
Wc(n)
Contextualized Word Embedding與該層的Wc(n)進行計算Token Embedding與每一層的Contextualized Word Embedding進行加總對於一個雙層的ELMo模型,詳細的計算過程如下:首先我們將一個詞彙轉換成Token Embedding向量,然後將這個向量交給LSTM進行計算,這部分的操作與我們在【Day 6】深度神經網路該怎麼改變Embedding向量(下)-PyTorch訓練的策略和方法中的作法相同。在這一階段每一個文字都會產生一個相對應的隱狀態h(t)。
接下來在ELMo模型中,由於它採用的是雙向的LSTM模型,所以我們需要將正反LSTM計算出來的兩個相同時序的隱狀態h(t)合併再傳遞給詞嵌入層,而這個新生成的詞嵌入就稱為Contextualized Word Embedding。接著該Contextualized Word Embedding會與參數Wc(1)進行運算,然後將這個結果傳遞到下一層的LSTM中,並重複上述的過程。
直到在ELMo模型的最後一層時,我們會將Token Embedding與兩個Contextualized Word Embedding進行加總,以產生最終的輸出結果。
小提示:
每一個Contextualized Word Embedding都會學習到上一個階段中更抽象的特徵,因此若直接將Contextualized Word Embedding作為最後一個輸出結果,將會導致原始的訊息丟失,因此再加權總合階段時我們必須將Token Embedding的資訊加入回來,才不會導致模型無法收斂。
這種複雜的計算可能導致模型無法收斂,因此需要將部分權重需要進行共享,其中最需要共享的參數便是正反兩個LSTM層中的Contextualized Word Embedding與Token Embedding權重,其原因很簡單若Token Embedding的權重與Contextualized Word Embedding在進行權重加總時不同,則可能導致序列位置與詞彙相同,卻有不一樣的輸出涵義。
這種狀況就好像一個我們已知的文字(Token Embedding)被水打翻而變模糊(Contextualized Word Embedding),但我們想要知道這個字時卻因為左側人告知的文字(左側LSTM)與右側人告知的文字(右側不同)而不同,造成你還是不知道該文字到底是什麼,而這種狀況就會造成語意混亂的情形。
不過你有沒有想起我們所說的,ELMo其實只是一種詞嵌入的預訓練模型,因此我們應該只會使用到它的詞嵌入層,雖然上述的模型架構看起來非常完整,但該模型的作用只是為了培養出好的Contextualized Word Embedding而已,而這種預訓練模型其實就是一種基於特徵(Base-feature)的方式,不會完整將這個預訓練模型給予到自己的模型中,而是指使用部分的權重,這種方式這包括我們所介紹的Word2Vec、GloVe、fastText。
而將這些詞嵌入層進行後續訓練時作者們發現在所有層級中,ELMo的第一層Contextualized Word Embedding的效果最佳,尤其在找出代詞和解答這兩個任務上其表現更是突出。
當我寫到這裡時才突然想到,我忘記在【Day 13】預訓練模型的強大之處? 我們要怎麼使用它?解說基於特徵的預訓練模型的概念了,因為這類模型的概念叫簡易,就是將已經訓練好的權重放入到自己的模型中,並且這種方式已經越來越少見了,所以我那天主要只解釋了微調方式的預訓練模型,所以我在今天將這方面的知識補充近來,不過剛好今天是基於特徵的預訓練模型的最後一個理論章節,這樣子應該會更讓你能記住這些基於特徵的模型概念,而在明天我將教導你如何使用這個ELMo模型。
那麼我們明天再見!
內容中的程式碼都能從我的GitHub上取得:
https://github.com/AUSTIN2526/iThome2023-learn-NLP-in-30-days


 iThome鐵人賽
iThome鐵人賽