前幾日我們已經把自然語言處理的基礎知識都學習完畢了,所以在今日最主要的目的就是將這些理論都轉換成程式碼,而我會在撰寫這些程式碼的同時告訴你,該部分對應的理論內容,今日的學習重點如下:
資料型態(Data type)
批次量(Batch Size)對效能的影響在深度學習的程式中,五個核心步驟包括讀取資料、資料前處理與資料正規化、定義模型/優化器/損失函數、前向傳播、以及反向傳播這幾個動作,而我為了解釋這些動作的涵義,我將逐一拆分這些步驟,來簡單解說程式碼中的內容。
首先我們要載入今天會使用到的所有函式庫,這些函式庫大部分都在【Day 3】電腦該怎麼理解人類的語言 (下) - 模型理解文字的方式中使用過,只有import torch.optim as optim是新引入的函式庫,這個函式庫內包含許多實用的優化器,所以我們需要用到它來幫助我們優化模型的損失。
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
from tokenizer import Tokenizer # 昨日建立的函式庫
接下來我們會先建立正面與負面的詞彙資料,接著將它們合併,以便使用Tokenizer()建立詞彙表。
negative_words = ["disappointed", "sad", "frustrated", "painful", "worried", "angry"]
positive_words = ["happy", "successful", "joyful", "lucky", "love", "hopeful"]
# 建立初始值
all_words = negative_words + positive_words
tokenizer = Tokenizer(all_words, special_token = ['[UNK]','[PAD]'], max_len = 1)
token2num, num2token = tokenizer.token2num, tokenizer.num2token
在我們建立完成之後,就能透過tokenizer變數來進行詞彙轉換,同時也能從中呼叫出能映射詞彙與數字的兩個字典token2num和num2token。
當我們獲取資料後就可以進行資料前處理和資料的正規化了,在這裡我們僅進行簡單的資料正規化操作,即將文字轉換為數字,並定義One-Hot Encoding標籤。
input_data = torch.tensor([token2num[i] for i in negative_words + positive_words])
labels = len(negative_words) * [[1., 0.]] + len(positive_words) * [[0., 1.]]
labels = torch.tensor(labels)
print('第0筆訓練資料:', input_data[0])
print('第0筆訓練標籤:', labels[0])
#---------------------輸出---------------------
第0筆訓練資料: tensor(3)
第0筆訓練標籤: tensor([1., 0.])
在上述程式中,我們先將負面和正面的詞彙數值化,然後轉化為張量格式,以配合模型的輸入和計算需求。接著,我們開始定義標籤。在標籤的定義部分,我們直接使用One-Hot Encoding的方式,將負面定義為[1,0],正面定義為[0,1]
但我們需要注意這個標籤的型態必須定義為float,因為我們的模型輸出的機率是小數點(float)而非整數(int),如果我們之後沒有加上「.」,模型在計算時就會發生錯誤。
在Pytorch中建構模型需要兩個步驟,首先我們需要建立模型的結構,再來定義模型的前向傳播方式,在這過程中繼承nn.Module類別是關鍵一步,因為這個類別包含了許多模型常用的操作,如模型儲存、獲取參數、及凍結參數等功能。因此我們在初始化模型時,可以使用以下的寫法:
class EmbDNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, output_size, padding_idx):
super().__init__()
self.embedding = nn.Embedding(
num_embeddings = vocab_size,
embedding_dim = embedding_dim,
padding_idx = padding_idx
)
self.fc = nn.Linear(embedding_dim, output_size)
在上述的程式中,我們先使用super()繼承nn.Module所定義的一些方法,接著我們就能夠定義模型的層,在今日的內容中,我們需要定義一層詞嵌入層和一層深度神經網路層,而在詞嵌入層中,我們需要知道以下幾個重要的參數:
| 參數名稱 | 說明 |
|---|---|
| num_embeddings | 詞彙表的總數量 |
| embedding_dim | 詞嵌入層的維度 |
| padding_idx | 填充字元的索引值 |
根據上表我們仍需要從外部輸入一些資訊進入模型中,為了能夠直接將詞嵌入層可視化,我們在這裡將其設定為2,同時我們也必須將詞彙表的總數量與填充字元的索引值一同輸入模型,因此我們可以用以下的程式取得必要的資料。 |
vocab_size = len(token_nums) # 詞彙表大小
embedding_dim = 2 # 詞嵌入層维度
output_size = 2 # 輸出大小(分類數量)
padding_idx = token2num['[PAD]'] # 取得PAD索引
model = EmbDNN(vocab_size, embedding_dim, output_size, padding_idx)
我們之前已經提到,除了定義模型結構外,我們還需要定義前向傳播的方式,因此我們將在這個類別中建立一個forward()方法,使模型能夠推理出答案。
class EmbDNN(nn.Module):
def __init__(self,...)
# 定義模型區塊
.
.
.
# 定義模型區塊
#定義前向傳播方式
def forward(self, x):
embedded = self.embedding(x)
out = self.fc(embedded)
return out
今天我不打算詳細討論我們所用的損失函數criterion和優化器optimizer這些實際的運算原理,我會在接下來的章節中向你們詳細解說。因為這部份的理論非常複雜,因此我認為有必要把它視為一個獨立的主題進行探討。
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
在訓練過程中,我們通常會參考Loss曲線來找出可能出現的問題,所以我們需要繪製一張訓練過程的折線圖作為參考。這時我們可以利用matplotlib這個工具來幫助我們繪製折線圖,而我們只需要撰寫一個函數,讓這個函數會接收每次訓練時的Loss值就可以了。
def show_training_loss(train_loss):
plt.plot(train_loss)
#標題
plt.title('Result')
#y軸標籤
plt.ylabel('Loss')
#x軸標籤
plt.xlabel('Epoch')
#顯示折線的名稱
plt.legend(['train'], loc='upper left')
#顯示折線圖
plt.show()
在模型訓練時,最基本的單位稱為Epoch,我們稱一次完整的訓練過程為一個Epoch,通常在這個完整的Epoch中,會將資料拆分為多個批量(Batch Size)來進行訓練,這樣做的原因是因為電腦的記憶體空間有限,無法一次將大量資料輸入模型。
然而在今天的內容中,我們只有14筆輸入資料,因此並不需要將資料集拆分成批次,可以直接進行訓練。
loss_record = []
epochs = 30000
for epoch in range(epochs):
# 梯度初始化
optimizer.zero_grad()
# 前向傳播計算答案
outputs = model(input_data)
# Loss計算損失
loss = criterion(outputs, labels)
loss_record.append(loss) # 紀錄該次Epoch的損失值
# 反向傳播計算梯度
loss.backward()
# 優化器更新權重
optimizer.step()
# 每訓練1000次顯示Loss值
if (epoch + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{epochs}], Loss: {loss.item()}')
在以上的程式中,我們可以看到除了前向傳播、反向傳播、更新權重之外,還多了一個梯度初始化的步驟,這一步驟的必要性是因為程式的設計方式。
當我們將資料轉換成張量後,程式會自動追蹤神經元的權重梯度,讓我們能快速進行反向傳播操作,但在執行過程中,我們無法預知每一個Epoch將包含多少批量的運算,若我們沒有進行梯度初始化,程式會把每個批量的計算結果累加到下一次的運算中,導致運算錯誤,所以我們必須要在每一次運算前進行梯度初始化的動作。
show_training_loss(loss_record)
當模型訓練完畢後,我們可以將loss_record這個儲存模型訓練Loss值的變數,提供給STEP 4所完成的函數,這樣就能夠從該曲線中即可觀察到模型訓練的過程。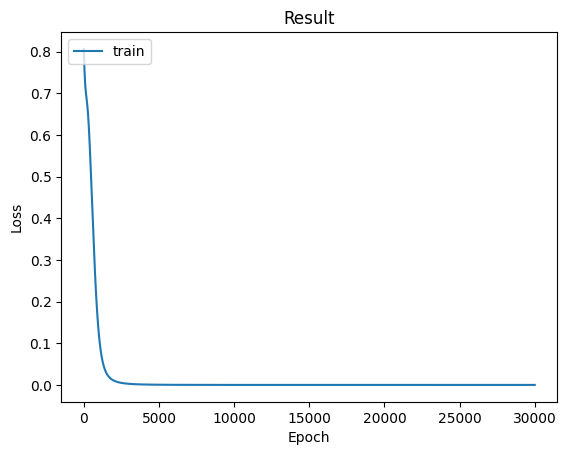
我們可以看到模型的收斂狀態顯示得非常良好,這是因為我們的任務較簡單,所以可以輕鬆的收斂。
在Pytorch中,我們可以藉由呼叫模型的 __init__ 方法中的參數,來獲取該神經元層的資料,在這裡我們只需要得到模型中的詞嵌入權重,所以我們可以使用下列的程式碼來進行這個動作。
embedding_layer = model.embedding
embedding_weights = embedding_layer.weight.data
torch.save(embedding_weights, 'embedding_weights.pth')
此時我們就能夠通過【Day 3】電腦該怎麼理解人類的語言 (下) - 模型理解文字的方式的方式將最終結果可視化。
def visualization(embedding_matrix, num2token):
# 提取降維後的坐標
x_coords = embedding_matrix[:, 0]
y_coords = embedding_matrix[:, 1]
# 繪製詞嵌入向量的散點圖
plt.figure(figsize=(10, 8))
plt.scatter(x_coords, y_coords)
# 標註散點
for i in range(len(embedding_matrix)):
plt.annotate(num2token[i], (x_coords[i], y_coords[i]))
plt.xlabel('Dimension 1')
plt.ylabel('Dimension 2')
plt.title('Visualization of Embedding Vectors')
plt.show()
token_nums = [i for i in num2token]
token_nums = torch.tensor(token_nums)
emb = nn.Embedding(len(token_nums), 2)
loaded_embedding_weights = torch.load('embedding_weights.pth')
emb.weight = nn.Parameter(loaded_embedding_weights)
embedding_vector = emb(token_nums).detach().numpy()
visualization(embedding_vector, num2token)
上述程式碼執行完畢後,我們將能夠獲得如下圖中所示的結果。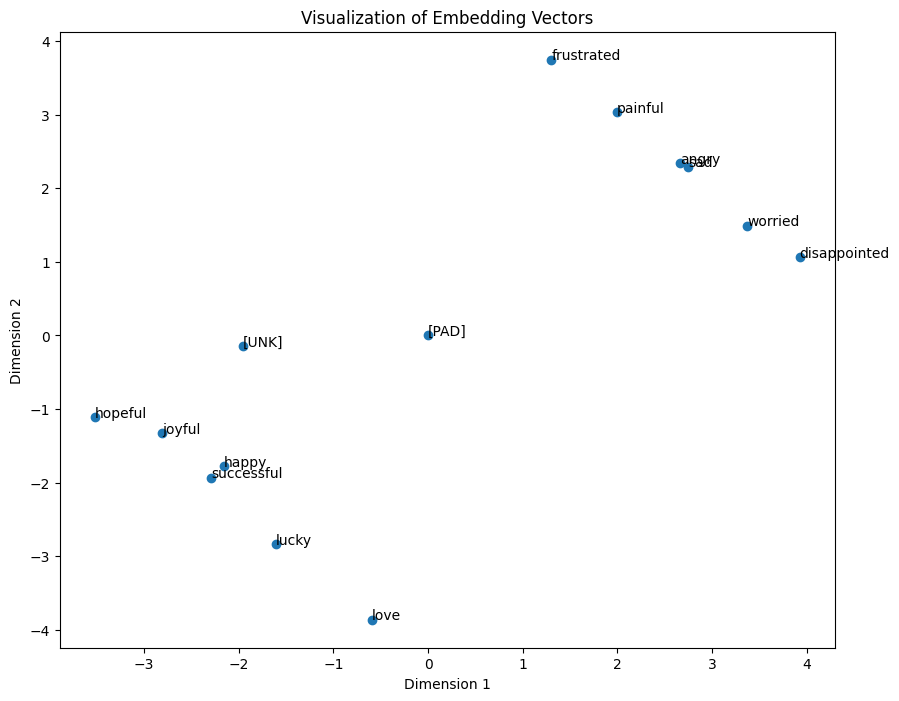
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
from tokenizer import Tokenizer # 昨日建立的函式庫
negative_words = ["disappointed", "sad", "frustrated", "painful", "worried", "angry"]
positive_words = ["happy", "successful", "joyful", "lucky", "love", "hopeful"]
# 建立初始值
all_words = negative_words + positive_words
tokenizer = Tokenizer(all_words, special_token = ['[UNK]','[PAD]'], max_len = 1)
token2num, num2token = tokenizer.token2num, tokenizer.num2token
input_data = torch.tensor([token2num[i] for i in negative_words + positive_words])
labels = len(negative_words) * [[1., 0.]] + len(positive_words) * [[0., 1.]]
labels = torch.tensor(labels)
print('第0筆訓練資料:', input_data[0])
print('第0筆訓練標籤:', labels[0])
class EmbDNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, output_size, padding_idx):
super().__init__()
self.embedding = nn.Embedding(
num_embeddings = vocab_size,
embedding_dim = embedding_dim,
padding_idx = padding_idx
)
self.fc = nn.Linear(embedding_dim, output_size)
def forward(self, x):
embedded = self.embedding(x)
out = self.fc(embedded)
return out
vocab_size = len(token2num) # 詞彙表大小
embedding_dim = 2 # 詞嵌入層维度
output_size = 2 # 輸出大小(分類數量)
padding_idx = token2num['[PAD]'] # 取得PAD索引
model = EmbDNN(vocab_size, embedding_dim, output_size, padding_idx)
# 定義損失函數與優化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
loss_record = []
epochs = 30000
for epoch in range(epochs):
# 梯度初始化
optimizer.zero_grad()
# 前向傳播計算答案
outputs = model(input_data)
# Loss計算損失
loss = criterion(outputs, labels)
loss_record.append(loss) # 紀錄該次Epoch的損失值
# 反向傳播計算梯度
loss.backward()
# 優化器更新權重
optimizer.step()
# 每訓練1000次顯示Loss值
if (epoch + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{epochs}], Loss: {loss.item()}')
def show_training_loss(train_loss):
plt.plot(train_loss)
#標題
plt.title('Result')
#y軸標籤
plt.ylabel('Loss')
#x軸標籤
plt.xlabel('Epoch')
#顯示折線的名稱
plt.legend(['train'], loc='upper left')
#顯示折線圖
plt.show()
show_training_loss(loss_record)
embedding_layer = model.embedding
embedding_weights = embedding_layer.weight.data
torch.save(embedding_weights, 'embedding_weights.pth')
def visualization(embedding_matrix, num2token):
# 提取降維後的坐標
x_coords = embedding_matrix[:, 0]
y_coords = embedding_matrix[:, 1]
# 繪製詞嵌入向量的散點圖
plt.figure(figsize=(10, 8))
plt.scatter(x_coords, y_coords)
# 標註散點
for i in range(len(embedding_matrix)):
plt.annotate(num2token[i], (x_coords[i], y_coords[i]))
plt.xlabel('Dimension 1')
plt.ylabel('Dimension 2')
plt.title('Visualization of Embedding Vectors')
plt.show()
token_nums = [i for i in num2token]
token_nums = torch.tensor(token_nums)
emb = nn.Embedding(len(token_nums), 2)
loaded_embedding_weights = torch.load('embedding_weights.pth')
emb.weight = nn.Parameter(loaded_embedding_weights)
embedding_vector = emb(token_nums).detach().numpy()
visualization(embedding_vector, num2token)
今天我們初步探討了Pytorch中的訓練方式和模型堆疊方法,不過這次我們僅用了一些簡單的資料作為測試,結果使得程式碼顯得相對簡單,所以在接下來的幾天,我將開始使用網路上的經典資料集,並會向你展示如何編寫一個完整的Pytorch訓練程式。
那麼我們明天再見!
內容中的程式碼都能從我的GitHub上取得:
https://github.com/AUSTIN2526/iThome2023-learn-NLP-in-30-days


 iThome鐵人賽
iThome鐵人賽