過去我們已經完成了情緒分析、文字生成、去識別化等等的NLP任務,這些任務分別代表分類、生成、及命名實體(NER) 這些也就是自然語言處理中的三大任務,基本上市面上的90%模型都是通過這三大任務完成的,但我們仍有一項任務未有詳細解釋,所以我計劃在介紹ELMo模型之後,將會馬上告訴你這個任務的詳細訓練方式。而在今天的目標中的詞向量使用方法與前幾天相似,所以不會在執行訓練的動作,所以在今天中主要舊視教會大家如何在Pytorch中使用到ELMo,並將其可視化。
今天的程式碼雖然只有短短幾行,但這裡有一點需要留意,由於ELMo所處的時代較為老舊所以大多函式庫並未支援,所以我們今天所使用的函式庫會先將GPU版本的Torch解除安裝,不過不會影響到我們今天的使用。
首先下載的就是ELMo這個模型,可以在vectors.nlpl.eu中找到該模型的json檔案與權重hdf5兩個檔案,該模型的使用方式如下程式碼所示:
# pip install allennlp
from allennlp.modules.elmo import Elmo, batch_to_ids
options_file = "options.json"
weight_file = "weights.hdf5"
elmo = Elmo(options_file, weight_file, 1, dropout=0)
sentence_lists = [['I', 'love', 'you', '.'], ['Sorry', ',', 'I', 'don', "'t", 'love', 'you', '.']]
character_ids = batch_to_ids(sentence_lists) # (2, 8, 50)
當我們載入模型後,我們可以將被斷詞的文本一次性地輸入到batch_to_ids()函數進行轉換,此時我們可以得到一個(2, 8, 50)大小的character_ids,其中,2代表輸入了兩句話,8代表輸入文本的最大長度,而50則代表該詞彙透過詞彙建立之Embedding的輸入形式。
在這兩個例句中:I Love You. 和 Sorry, I don 't love you,傳統的詞嵌入方式會將I、Love、You的詞嵌入都放在相同的維度,然而我們之前提到ELMo會根據上下文的關係來整合詞嵌入,因此為了驗證該模型的結果,我們將編寫一段詞嵌入可視化的程式碼。
但在進行此步驟之前,我們需要用PCA方法對ELMo的Embedding進行降維,因為其維度為1024,而不是我們之前設定的2維。
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
pca = PCA(n_components=2, random_state=2526)
v1 = tsen.fit_transform(embeddings[0].detach().numpy())
v2 = tsen.fit_transform(embeddings[1].detach().numpy())
all_vec = np.concatenate((v1,v2), axis = 0)
flattened_list = ['I', 'love', 'you', '.', 'None', 'None', 'None', 'None', 'Sorry', ',', 'I', 'don', "'t", 'love', 'you', '.']
接下來我們將以前寫的程式碼呼叫回來,在這一步中加入我們上述的文字向量和對應的文字。
def visualization(embedding_matrix, flattened_list):
# 提取降維後的坐標
x_coords = embedding_matrix[:, 0]
y_coords = embedding_matrix[:, 1]
# 繪製詞嵌入向量的散點圖
plt.figure(figsize=(10, 8))
plt.scatter(x_coords, y_coords)
# 標註散點
for i in range(len(embedding_matrix)):
plt.annotate(flattened_list[i], (x_coords[i], y_coords[i]))
plt.xlabel('Dimension 1')
plt.ylabel('Dimension 2')
plt.title('Visualization of Embedding Vectors')
plt.show()
visualization(all_vec, flattened_list)
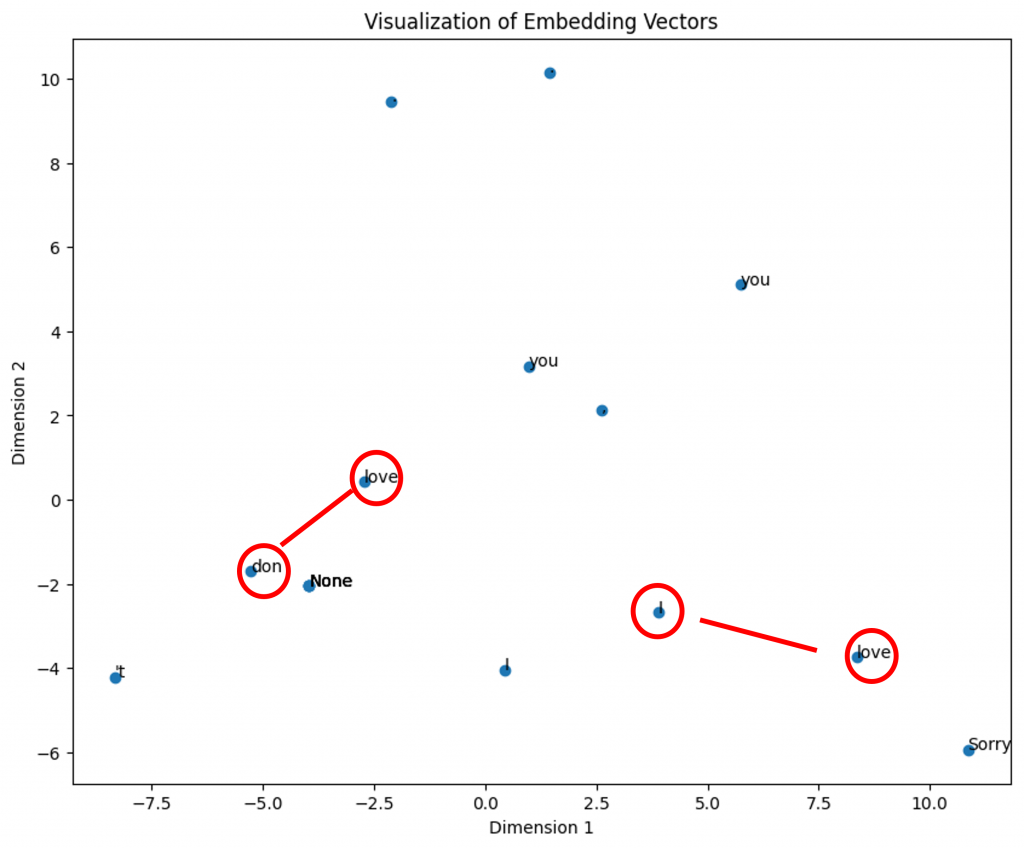
在此我們可以觀察到,其中一個Love的向量更接近don't,另一個Love則更接近I,這種特性正是ELMo模型最重要的部分。
這時這些詞向量也就是我們在Word2Vec等章節中所需要的詞嵌入向量了,我們需要使用它時只需將這些向量拼接回來後方入到模型即可。
我們今天學習了如何使用ELMo模型,同時將每個詞彙的結果可視化,不過你可能會發現這次的詞嵌入向量與先前相比,格式似乎有所差異,這種狀況導致在訓練ELMo模型時,讓我需要不斷地依據上下文轉換這些向量,並且這些轉換後的結果還要放入模型中進行運算並與時間序列模型的進一步計算結合,這將會使推理速度降低,因此我將在明天介紹你目前自然語言處理中最強的架構Transformer是如何解決這些問題的。
那麼我們明天再見!
內容中的程式碼都能從我的GitHub上取得:
https://github.com/AUSTIN2526/iThome2023-learn-NLP-in-30-days


 iThome鐵人賽
iThome鐵人賽