經過這麼多篇,終於來到我們的核心演算法,Bayesian Delegation了!不用藉由通訊,即可猜測其他智能體的意圖,當然普通的類神經網路也能作到,但 Bayesian 的好處就在於不用太多資料,如果是類神經網路,為了達到很好的泛化性,複雜度越高的任務越要更多的資料。
首先,我們的 Bayesian Delegation 在這裡的應用就是要完成一個分配問題,對於單純只有兩種 sub-task ([T1, T2]) 以及兩個智能體 ([i,j]) 對於這兩種兩個的組合,總共的輸出則有四種組合 ta=[(i:T1, j:T2), (i:T2,j:T1),(i:T1,j:T1),(i:T2,j:T2)] 看到這四個組合,便可以發現有兩個是分開的,另外兩個是投入到相同的sub-task,在這個範例,可以看到,我們模型就是要對這四個組合預測個別的機率。在每一次的 step 中,模型都希望可以選到最可能的分配 ta*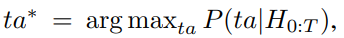
一般來講,Bayesian還有一個分母的項,但我想是為了好說明後面的公式而消掉,這邊直接用正比的符號來簡化。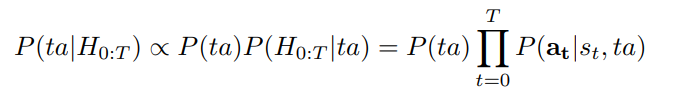
最終可以看到,藉由H0:T的歷史資訊,我們的先驗資訊,正比與下面這條指數函數。B的話為我們實質上的Bayesian model,Q則為一般的Q function,用來估計後面的獎勵值。當如果B越小,代表其他的智能體行為越隨機,B趨近於無窮大,則代表其他模型的表是完美的最佳化。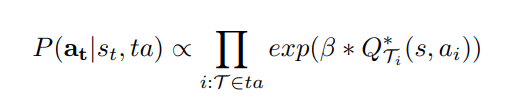
至於該論文使用了一個 bounded real-time dynnamic programming (BRTDP)拓展為去找最佳化的Q-function以及policies,這個 BRTDP 的研究可以參考過去這篇論文。
雖然我有點不太確定,Q function 與 Bayesian的結合,收歛性的保證性如何,但看這篇研究效果是很好的,對我自己來 Q 估計的方法,的確在其他的研究 Cross Entropy Method 也過看過,只能說這個概念很直觀,也不是限定於在強化學習,我猜演化計算或許也有類似個應用
Too many cooks: Bayesian inference for coordinating
multi-agent collaboration


 iThome鐵人賽
iThome鐵人賽