今天我們要來帶大家實做 HopeNet 這個 Headpose 個模型,並且訓練出自己的 HopeNet!為了避免太多單調重述的知識,我們只講述關鍵注意部份!
Headpose 要用的 dataset 其實非常單純,通常只要有提供以下數據即可:
1.`Image`
2.`Face bounding box label`(可能加上 `Landmark`):用來切下人臉區域餵給 `Headpose` 模型去學習跟預測
3.`Headpose label`
在dataloader 中很好操作只要透過 Face bounding box去切下人臉然後與 Headpose 一起回傳即可!
而這一次我們要使用的 dataset 是 300W-LP,他是3DDFA作者群當初提出的,他是由複數個 dataset 所組成的,大家可以先去這個300W-LP 下載 Link 去把 300W-LP 下載下來並解壓縮應該可以看到這樣的畫面:
300W-LP 主要由 4 個常見的人臉資料集並且加上 flip 之後的去結合起來的,並且作者特別考量以往 Headpose 的資料集中人頭的角度大都是小角度 (ex.Yaw的絕對值小於 45度),這樣並不利於學習預測大角度的 Headpose,因此 300W-LP 特別刻意收集了大量的大角度人頭以助 Headpose 模型學習,其資料分佈如下: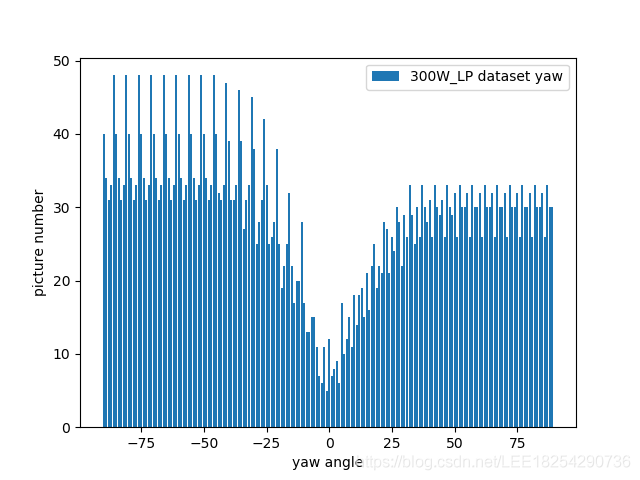
另外需要注意的是,因為 HopeNet 有先把角度做區分成幾類,然後才細分成連續的角度值,因此在dataloader的 __getitem__中我們要把 Pose 去分類,像是以下
# 從資料集中撈到 pose 資訊(pitch, yaw, roll),單位是 radians
pose = function_to_get_pose(pose_label_path)
# 轉成 degrees.
pitch = pose[0] * 180 / np.pi
yaw = pose[1] * 180 / np.pi
roll = pose[2] * 180 / np.pi
continue_labels = torch.FloatTensor([yaw, pitch, roll])
# Bin values 分類值 -99到+102度,分類需要對應的標籤,每 3 度分一類!
bins = np.array(range(-99, 102, 3))
# bins 是 np.digitize(data,bins)第二個參數(升序或者降序),第一個數據在bins 哪個區間範圍內,
binned_pose = np.digitize([yaw, pitch, roll], bins) - 1
# 最後回傳 照片, 連續的 pose label, 分類的 pose class
return image, continue_labels, binned_pose
以下為 HopeNet 的模型定義,num_bins 是每個角度我們都分成 98:
# 引入需要的庫
import torch
import torch.nn as nn
# 定義 HopeNet 模型
class HopeNet(nn.Module):
def __init__(self, num_bins=98):
super(HopeNet, self).__init__()
# 定義卷積層和全連接層
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.conv2 = nn.Conv2d(64, 128, kernel_size=5, stride=2, padding=2)
self.conv3 = nn.Conv2d(128, 256, kernel_size=5, stride=2, padding=2)
self.conv4 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.conv5 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
# 定義全連接層
self.fc1 = nn.Linear(256 * 7 * 7, 512)
self.fc2 = nn.Linear(512, 512)
# 定義預測出 pose 的 class
self.fc_yaw = nn.Linear(512 , num_bins)
self.fc_pitch = nn.Linear(512 , num_bins)
self.fc_roll = nn.Linear(512 , num_bins)
# 定義激活函數
self.relu = nn.ReLU()
def forward(self, x):
# 定義前向傳播過程
x = self.relu(self.conv1(x))
x = self.relu(self.conv2(x))
x = self.relu(self.conv3(x))
x = self.relu(self.conv4(x))
x = self.relu(self.conv5(x))
# 展平特徵圖
x = x.view(x.size(0), -1)
# 通過全連接層
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
# 預測 pitch, yaw, roll 的 class
yaw = self.fc_yaw(x)
pitch = self.fc_pitch(x)
roll = self.fc_roll(x)
return yaw, pitch, roll
# 實例化 HopeNet 模型
hopenet_model = HopeNet()
# 如果有興趣可以打印模型結構
print(hopenet_model)
那打到這我們應該怎麼去 inference 呢?參考下述即可:
# Forward pass
yaw, pitch, roll = HopeNet(images)
# 經過 softmax 得到各個 class 的機率值
yaw_predicted = nn.softmax(yaw)
pitch_predicted = nn.softmax(pitch)
roll_predicted = nn.softmax(roll)
# 回復出連續值!
idx_tensor = [idx for idx in xrange(66)]
idx_tensor = Variable(torch.FloatTensor(idx_tensor)).cuda(gpu)
yaw_predicted_continue = torch.sum(yaw_predicted * idx_tensor, 1) * 3 - 99
pitch_predicted_continue = torch.sum(pitch_predicted * idx_tensor, 1) * 3 - 99
roll_predicted_continue = torch.sum(roll_predicted * idx_tensor, 1) * 3 - 99
有了 inference的方法之後,那我們在 training 時只需要抓取以上值出來算 loss 即可:
classificaton_criterion = nn.CrossEntropyLoss().cuda(gpu)
regression_criterion = nn.MSELoss().cuda(gpu)
# Cross entropy loss, 因為 cross entropy 中已經有 softmax,所以我們就不用拿 yaw_predicted 等等來計算了!需要用到 dataloader 中提共的 binned_pose
label_yaw, label_pitch, label_roll = binned_pose[0], binned_pose[1], binned_pose[2]
loss_yaw = classificaton_criterion(yaw, label_yaw)
loss_pitch = classificaton_criterion(pitch, label_pitch)
loss_roll = classificaton_criterion(roll, label_roll)
loss_pose_classification = loss_yaw + loss_pitch + loss_roll
# regression loss, 需要用到 dataloader 提供的 continue_labels
label_yaw_continue, label_pitch_continue, label_roll_continue = continue_labels[0], continue_labels[1], continue_labels[2]
loss_regression_yaw = regression_criterion(yaw_predicted_continue, label_yaw_continue)
loss_regression_pitch = regression_criterion(pitch_predicted_continue, label_pitch_continue)
loss_regression_roll = regression_criterion(roll_predicted_continue, label_roll_continue)
loss_regression = loss_regression_yaw + loss_regression_pitch + loss_regression_roll
# total loss & 反向傳播和優化
total_loss = loss_pose_classification + alpha * loss_regression
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
我們今天已經講完了 HopeNet 實做中的關鍵點,相信大家基於這些步驟以及之前深度學習的經驗就可以實做出自己的 HopeNet 了!那完整個 code 我們會在跟新到這個連結

