
我們回想一下顧慮資料隱私的方法目標,基本上主要是希望目標部屬模型 不要看到原本完整的真實資料,如果我們沒有考慮Federated learning那種使用的環境或者直接使用 Synthetic image的話,那我們可以考慮真實資料去識別化(De-Identification)的方法 這類型的方法,那實務上可能的方法有兩種:
1.Image augmentation:原本的圖片經過處理讓我們看不出原本的照片
2.Image transfer:原本的圖片經過轉換處理換成其他人讓我們看不出原本是誰照片
這兩種方法雖然相較於使用 Synthetic image 不夠更高等級的 Privacy-protect,但相較於原本使用完整資訊的方法來說已經保護了一定的 Privacy!
Image augmentation這類型的方法旨在透過將原本的真實資料做一定的處理(ex.挖孔)然後讓人們看不出來原本的資料,進而達到 Privacy-protect 的目標,那以下我們將透過幾篇論文來介紹:
像是在人臉辨識的任務中,我們思考一下模型在學習過程最主要的任務是不是盡力分開兩張不同人的照片即可,可能有否大鬍子就可以辨別兩個人了,所以不一定要真的能到完整的照片呀!如下圖: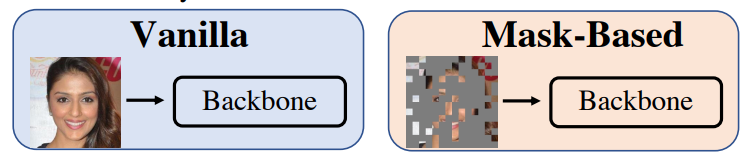
其中Mask-based就是挖孔的方法, Vanilla 就是原本直接使用真實資料訓練的方法!
那這樣感覺是不是我們其實可以透過挖孔的方式來遮擋人臉的可辨識資訊進而達到保護隱私的目的呢?聽起來很美好,但如果遮得太多是不是模型在學習過程他等於在看一堆沒有可辨識的資訊的洞中找分辨兩人的線索,這本身就不合理的事情呀!!!所以效果確實也不好,如見下方圖中測試在 LFW 以及 CFP-FP 這兩個非常有名的測試集上的 Mask-based 與 Vanilla的比較: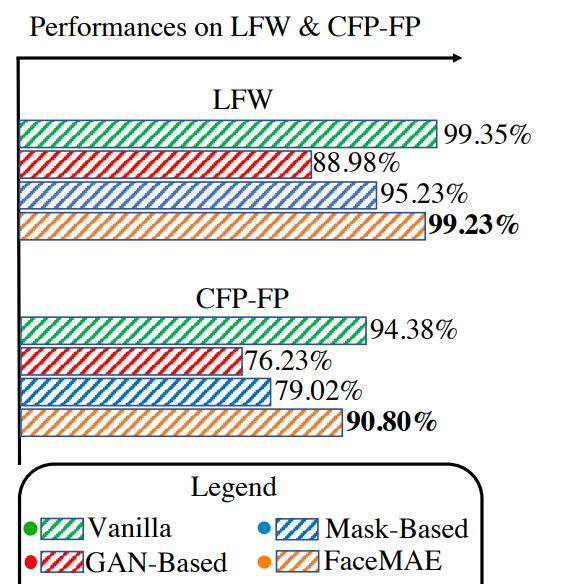
我們可以看到原本 Vanilla 的方法在 LFW 以及 CFP-FP Acc 分別可以達到 99.35% 以及 94.38% 而 Mask-based的方法只能達到 95.26% & 79.02% ,這樣的 performance 真的差太遠了!
那有沒有甚麼辦法可以幫助模型在一堆挖孔的照片裡學習呢?如果 model 只看到挖孔後的照片還是能夠大概幻想出原本的照片是不是代表模型其實對整張人臉的概念是存在的這樣應該可以有所幫助!那我們可以引入 Reconstruction loss 概念進來
我們接下來介紹這一篇 FaceMAE 就是 Mask-based結合reconstruction,那架構上也結合這兩年非常有名發在 CVPR2022的 Mask auto encorder(MAE)(對 MAE 有興趣的人可以去參考這個解說,其餘人可以先當作一個 backbone 就好)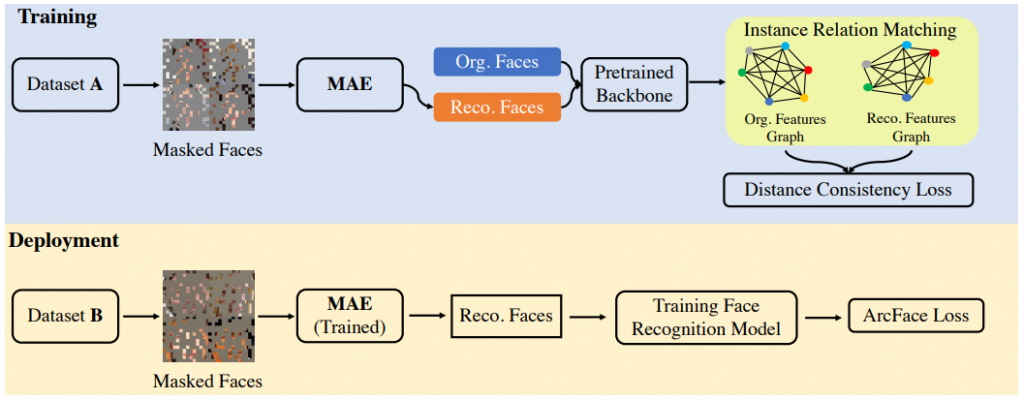
我們可以看到他想讓 MAE模型去預測出原本照片的樣子(reconstruction loss),在使用上也會使用這個訓練好的 MAE 去還原原本的照片!須注意的是其實這裡有用一個使用原始資料 pretrained 好的 Face recognition model(可以當作就是一個 vanilla),只是作者強調了最後測試時用到的 Face recognition(在 Depolyment)裡是沒有看到完整原始圖的!
他們的概念講就是測試時每個人的照片都 mask 了,進而達到保護測試人員!但注意其實訓練時有完整原始圖(ex.MAE 訓練
那在 MAE 裡訓練的 pretrained 好的 Face recognition model 主要是用來收斂 mask 經過 MAE 還原與原圖在 Model 眼裡的 feature 應該要一致(這裡用到 Distance Consistency Loss希望兩張圖的 關係graph 一致)!
最後效果我們也可到FaceMAE可以拿到與Vanilla相似的精準度!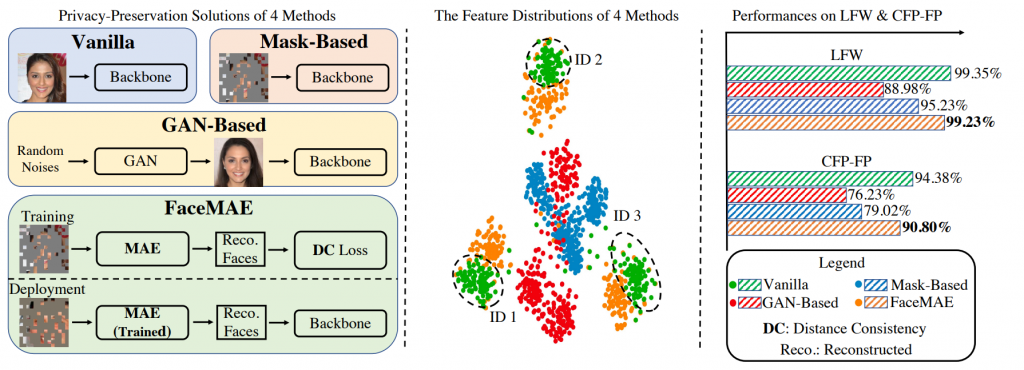
Image transfer那如果我們可以把原本訓練資料集裡的人都轉成其他人,這樣的 Privacy-protect 是不是可以更上一層樓?沒錯!Image transfer 方法想做的就是這一件事!我們來參考 Sface,提出的方法如下圖: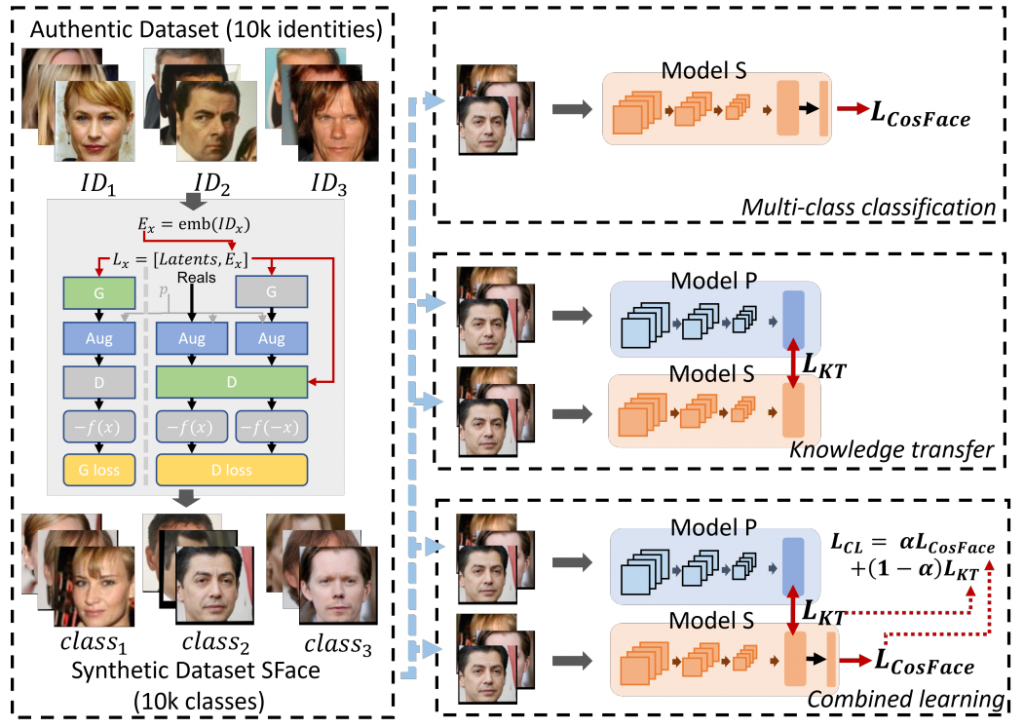
圖中左邊為把照片做 Image transfer轉成其他人(至少不跟原本一致)的樣子,又圖示提出的訓練方法。我們先看他提出的轉換方法,主要為訓練一個 StyleGAN2-ADA 去做 Image transfer:
* 每張真實人臉資料(Authentic data)都用一個 CNN 壓出 ID feature,叫做 E_x,其中具有這個 ID 的特徵
* 然後 random 生出 latent 並與這個 E_x concate 起來放進 StyleGAN2-ADA 裡去生出 Fake data 並且連同原本的 Authentic data 一起做 GAN 的訓練(關於 GAN 訓練可詳看 StyleGAN2-ADA 或者從台大李弘毅影片中簡單了解
然後訓練上有三種設計,為右圖這三張,其中 model S 為實際上要用來部屬的,而 model P 為預先使用真實資料訓練好的模型:
1. Multi-class classfication(CLS):就是直接把轉換過的 dataset 去跑 Cosface 訓練出 model S
2. Knowledge transfer(KT) : 希望 model S 的預測可以接近 model P
3. Combined learning(CL) : 結合以上兩個 loss 訓練,其中設一個 alpha 來平衡兩個 loss
訓練測試結果如下:
可以看到雖然直接訓練CLS效果不是很好,但KT就可以讓 LFW 跳上 91!甚至 CL 經過適當的調整之後可以跳上 96 !這樣我們可以這樣看待 Sface
經過
GAN轉換出來的照片大概足以讓Face recogniton model學習如何分辨人!但效果上需要在提昇一點以及不要忘記是使用真實圖片轉換出來!
但你可能會想這樣轉換出來的照片是不是其實與原圖有點像,或者說轉出來的有一點不夠穩定跟不夠好,如下圖:
那在 Image transfer 上有沒有可以做得更好呢? 答案是有的(畢竟人類科技一直進步嘛~)而這個領域就是 Face Dataset Anonymization。如下面今年 CVPR 2023 發的Attribute-preserving Face Dataset Anonymization via Latent Code Optimization 中提出的 FALCO
,效果可見下圖:
可以看到他們的方法除了有成功做到 ID anonymized同時也成功讓attribute有保留好,這樣的好處是人臉生成時不用重新想一個人臉細節(光影、頭髮、表情等等),模型可以更穩定的生不同的人。那他們的方法細節跟 StyleGAN2 有很大的關聯,今天這一章就不展開討論了,有興趣可以先去看原論文。
今天我們介紹了 Image augmentation 以及 Image transfer 這兩種嘗試去做真實資料去識別化(De-Identification)的方法,相較於原始資料已經做到了一定的 Privacy-protect 的能力,但還是有使用原本真實資料的疑慮。明天我們將介紹更加Privacy-protect的方法--Use Synthetic image 的方法
1.LFW
2.CFP-FP
3.Wang, Kai, et al. "FaceMAE: Privacy-Preserving Face Recognition via Masked Autoencoders." arXiv preprint arXiv:2205.11090 (2022).
4.He, Kaiming, et al. "Masked autoencoders are scalable vision learners." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.
5.Boutros, Fadi, et al. "Sface: Privacy-friendly and accurate face recognition using synthetic data." 2022 IEEE International Joint Conference on Biometrics (IJCB). IEEE, 2022.
6.Mask auto encorder 解說
7.T. Karras, M. Aittala, J. Hellsten, S. Laine, J. Lehtinen, and T. Aila. Training generative adversarial networks with limited data. In NeurIPS, 2020.
8.台大李弘毅GAN講解
