今天我們要來介紹更加 Privacy-protect 的方法--使用虛擬資料 (Synthetic data)的方法!這類方法考慮著你無論如何使用遮擋或者轉換真實資料,那不都還是有用了真實資料來訓練我們的模型嗎?例如前一晚的介紹中講到的 Image augmentation & Image transfer都是有拿原始真實圖片做操作或者使用來訓練一個預訓練模型!所以我們乾脆直接使用從無到有的資料不就好了!那今天我們會來介紹科技圈是如何建構虛擬資料的以及又是如何來訓練的,並且訓練時又遇到什麼問題以及可以如何解決!
打從 2014 GAN 的橫空出世之後,人們就開始發現我們其實有能力建構自己的虛擬資料集了!而時過境遷到了現在,人們除了用 GAN 來做,在建構人臉上面也多了更多技術像是我們可以使用電腦動畫 CG 或者 3DMM技術來建構出非常細膩的 3D 人臉、或者我們也可以使用更強的模型像是 Diffusion 模型來產生更好的人臉,以下我們將照著近代人臉生成發展史來跟大家介紹Synthetic datasets 產生的方法
首先我們來介紹來自ICCV 2021提出的 SynFace,他的概念基於那時候的 GAN 再生照片這件事上做到了非常好的效果所以想用 GAN 的技術來生人臉並使用來訓練 Face recognition model! 那他採用的生人臉的 GAN模型是使用了 CVPR2020 發的 DiscoFaceGAN,這個 GAN 的結構如下: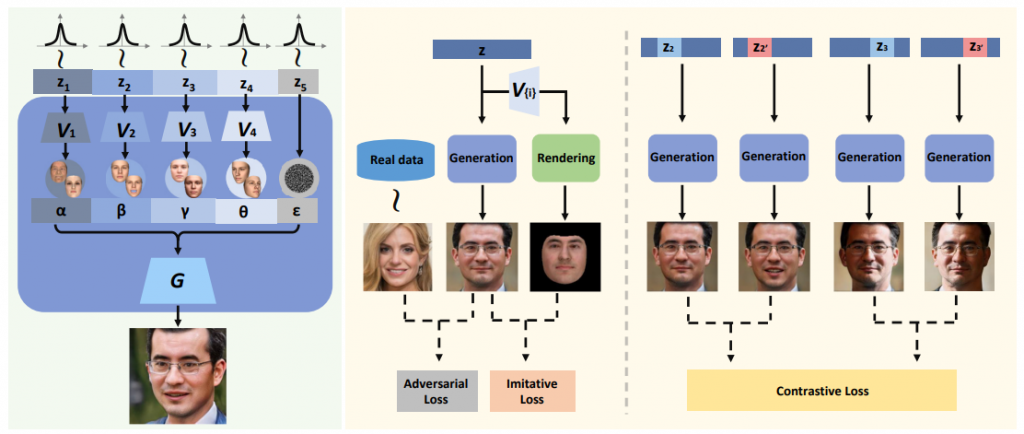
如上圖左編那他具體來說把 GAN 再生每個人臉中的 latent 做獨立拆分(disentanglement)成為 ID,Expression, light以及Pose這四個子 latent,以其希望例如控制為同一個 ID latent 時改變其他的 latent 即可以達成生出同一個人但不同效果,那訓練的部份我們這裡就先不展開討論,有興趣者可以在下面留言讓我知道大家有興趣,可能之後開一期來講~~
那效果如下:
可以看到生出來的照片有聲有色的!!那 SynFace 想更進一步加人臉的多樣性所以他在生圖片的時候有做一個 ID-mixup,亦即讓兩個 ID latent 做線性插值,就像是 mixup 一樣,那訓練時的 ID label 也會做線性差值:
但有 GAN 就沒問題了嗎?其實主要問題有兩個:
1.生成出來的照片還是可能不穩定
2.同一個ID在不同角度下可能會長出不同的人,如下圖
那可否利用成熟的 3D 技術來建構出完整的 3D 人物在進行拍攝呢?這樣不就可以保證拍攝的穩定性!那這邊我們就要來介紹 WACV2023 發的 Digiface-1M,他是利用他們之前發在 ICCV2021 的 Fake it till you make it: face analysis in the wild using synthetic data alone 的生圖 pipeline 來建立出資料集,流程如下:
你可以看到他是一個一個加上變化量去出捏出一個你想要的人臉的,我們附上更多示例圖如下:
那與 Synface 中用到的 Discofacegan相比較:
你可以看到在Digiface-1M在各種角度的照片確實都可以保持為同一人,並且生出來的圖也非常完整,但唯一的問題就是:
人有點太塑膠不像真實人,這樣
domain gap可能會有點大
從去年報紅的 Stable diffusion 大家一定對 Diffucison model 不陌生了對吧,那可否用他來成為一個更強的人臉生成器呢?答案是可以,例如 CVPR2023 發的 DCFace 就是一個很好的例子: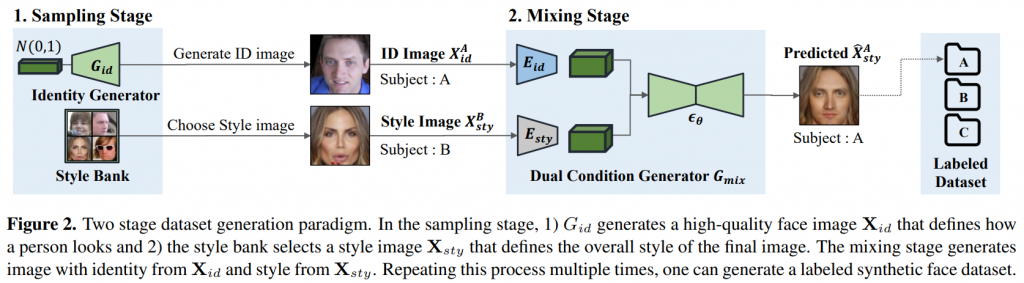
他透過兩個 Diffucion model 去建構出一個 DCFace 的模型,具體細節有興趣可以在下面留言,我們可以在開一章來講 Diffusion model 技術 detail,那我們這裡就直接上圖:
可以看到他相比 Synface 用的 GAN 更加穩定,並且比 Digiface-1M 的 3DMM 更加擬真,那使用起來訓練效果當然大幅上升並且甚至逼近使用真實照片:
聽起來生成模型來生人臉可以生一堆很不錯的人臉,那會遇到什麼問題嗎?這邊我們回顧一下昨天介紹中提到的這一張圖: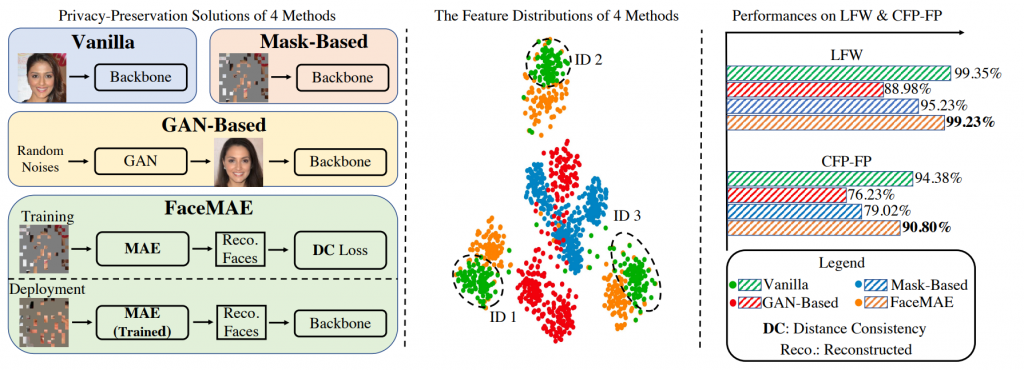
其中右邊我們可以看到GAN-based其實效果遠殊大家一大節,這其實這個原因除了生成模型可能生出來的圖形有缺損或者破圖這種舞們肉眼可以看得出的問題,最大的問題在於 Domain-Gap 問題,亦即人臉看起來可能跟真實圖篇已經足夠相似了,但對於模型來說就是與真實圖片有一個巨大的落差!那可以怎麼解決呢?除了生出更真實的照片之外其實有以下有兩種辦法:
1. 與 Real image 做 Domain mixup或者使用少量 real data 做 fintune:如 Synface & Digiface-1M
2. 做 ‵Unsupervised domain alignment‵: 如筆者自己已經放在 ‵Arxiv‵ 的 SASMU提的 ‵Frequency mixup based‵ 的方法--spectrum mixup (SMU)
那以下我們分別來介紹:
Synface 提出的方法如下圖: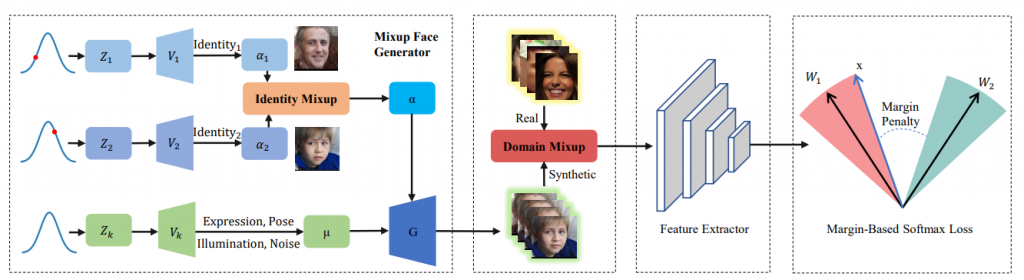
你可以看到關鍵點適中間在生出 ID-mixup 後的照片後有拿取少量的 real image 再做一次 mixup(domain mixup) 進而達到消除 domain gap 的期望
而 Digiface-1m 則是使用少數 real image 來做 fine tune 如下圖效果: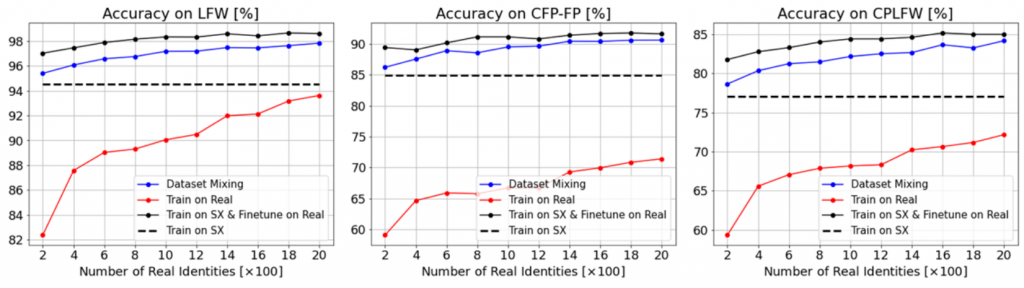
其中,黑色虛線為使用提出的虛擬資料(標記為 sx)訓練出來的準確度,可以看出確實使用一小部份真實資料就捨以大幅解決 Domain gap,但一方面就是確實訓練時模型還是有看到 real image 的真實資訊的 (這一張照片是誰)
筆者自行提出的方法是想要來在解決 Domain gap 的過程中是否可以不須用到 real image的真實資訊(這一張照片是誰)以及可以不要讓模型看過原始照片長什麼樣的,因此筆者參考了 Frequency mixup這個領域:
Frequency mixup 為一種希望透過混合 Frequency domain 的資訊來達到 domain mixup 的方法,他的特點在於為 Unsupervised(這樣更不會知道 real info),並且是做在人眼看不懂的 Frequencydomain 上,是一個在 2020 ~2021提出時在各大頂會都是 oral的方法,大致方法(以下皆為 CVPR 的 oral)如下: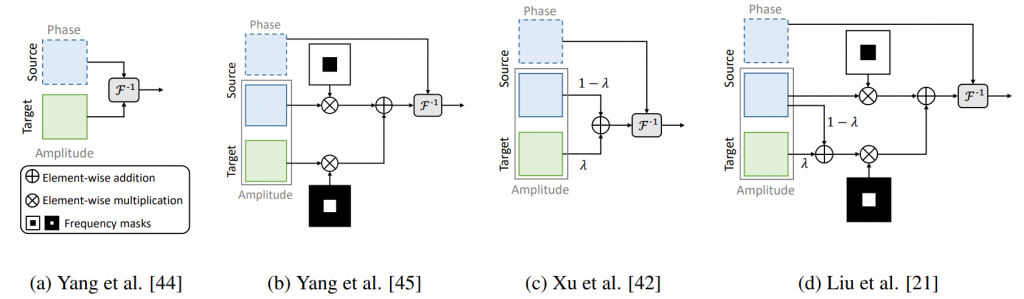
其中 target 為 real image,而 source 則為 synthetic image,而 F 為傅立葉轉換,F^-1則為你傅立葉轉換,可以看得出來作法主要為將 synthetic image 經過傅立葉轉換後(會得到 Phase & Amptitude)把 Amptitude拿出來與 real image 的 Amptitude 做融合!那這樣的方法確實有點道理因為我們知道模型在看圖的時候為有在看頻率的部份,那基於以下理由:
1.Phase 與一張圖片的結構有關,因此我們不會亂動,因此選用 amptitude 這個跟能量有關的來混合
2.但一張圖片通常高頻為細節,因此如果不是將完整 Amptitude 線性混合的化,會想要把 Source domain 的Amptitude中的高頻保留與 Real的Amptitude中的低頻混合,這樣設計成保留 Source domain / 結構以及混合 real 的一些特徵進去!那透過這樣的混合確實能增加一些 real domain 的特色進來。但這樣混合出來的圖片如下:
可以看到以前的 frequency mixup 的方法混合出來的照片非常的髒亂,並且我們以 PSNR 這個比較去語源圖計算(越高代表越接近原圖),可以看到與原本的 synthetic image 差了非常遠!那這代表著中間有太多細節損失掉了QQ,這樣應該會不利於模型學習,如下圖: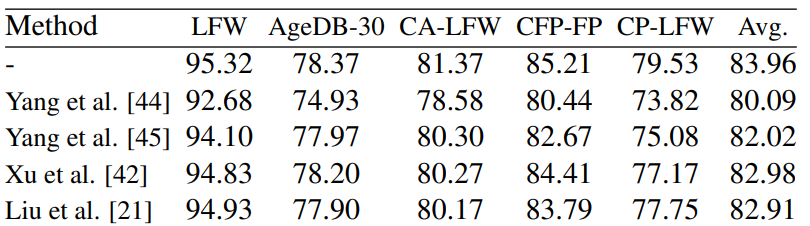
你可以看到用了這樣的
Frequency mixup甚至比不用還差
筆者自己提出的 spectrum mixup (SMU) 也是一種Frequency mixup,但基於以下原因而做了修改:
1.結構資訊資本上已經存在於 Phase圖中了,因此 Amptitude 中的結構資訊可以不用太擔心沒有了會怎麼樣
2.大部分的資訊會與能量的高低有關,並且通常一張圖片的轉成 Amptitude 後可以看到中間低頻的能量較強代表資訊較多,因此如果去除的話會損失大量資訊
3.大都以前的 frequency mixup 中用的 mask 都為 0-1 分佈,這樣的 mask 變化太過劇烈會導致 ringing-effect(如上上圖示範Yang et al. [45]那一行),因此我們改成 gaussian 分佈 mask 這樣比較緩和
在論文中我們還有闡述其他理由,但因為比較複雜因此在這裡我們就簡單提這三個,有興趣可以去看我們放在 ARxiv上的 SASMU~~
我們提出的方法如下圖: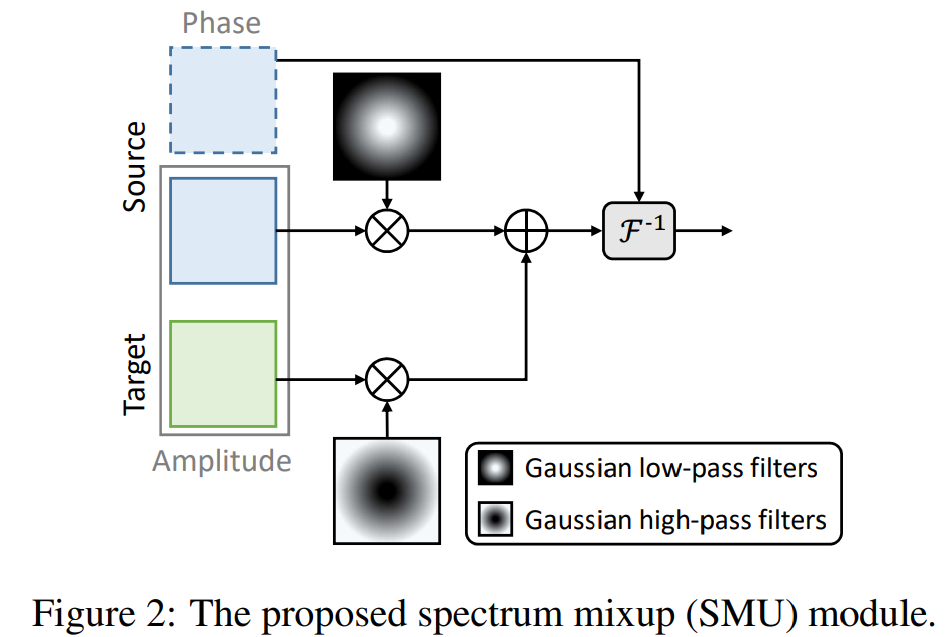
實作上也非常簡單,Pseudo-code如下: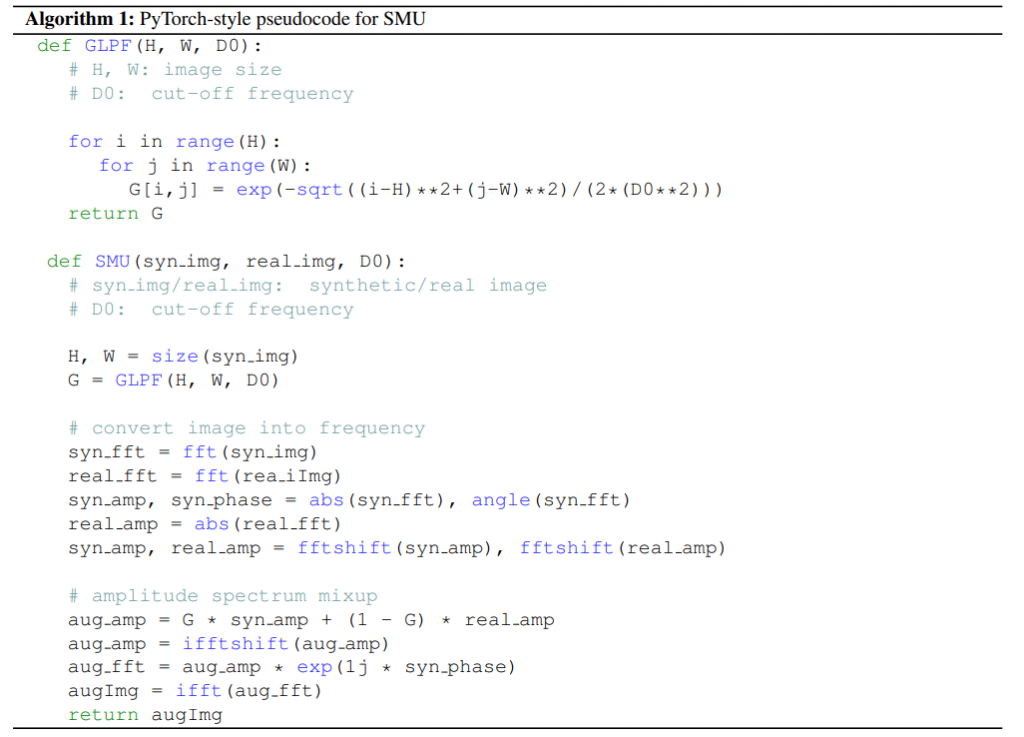
這樣出來的效果非常好看,有混合到真實資料的特徵又敬量保持原本的照片資訊(細節結構等等),如下圖:
而訓練效果也一掃之前方法會變差,有著明顯提昇: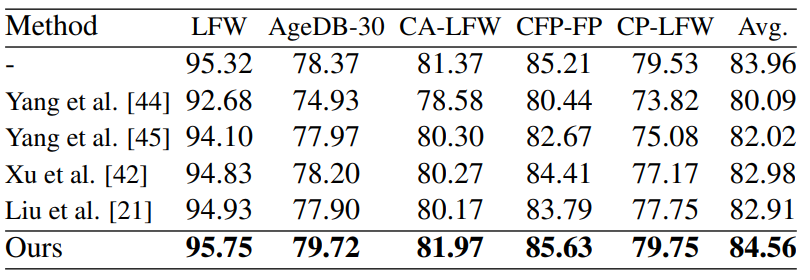
那論文中筆者其實也有做其他實驗放在論文中正文 & suplementaty,例如證明用gaussian 分佈 mask去除掉 ringing-effect其實效果會更好、無論是哪個方法只要是Synthetic image 較傾向保留低頻 一定會好於Synthetic image 較傾向保留高頻、以及強的 data augmentation對於改善 Domain-gap 在 GAN-based 以及 3DMM based(Digiface-1M)都會有效等等,歡迎有興趣的朋友到 Arxiv 上看看我們這一篇 SASMU
那我們也將 SMU 放在最新的 DCFace 資料集上,也是證明有幫助的(目前也正在趕稿中><~好累~)!歡迎大家後續繼續關注我們的工作~~
我們今晚講完了使用 Synthetic image 來做訓練的效果以及可能遇到的問題並且可以如何解決!非常感謝大家一路追這個系列到今天,這 30 天裡我們帶著大家一起看過許許多多人們在臉這個領域上面做的電腦視覺技術,從 2D 的資訊 Face detection & Facial landmark detection,接著 3D 的 Head pose & EyeGaze ,最後到了整體特徵資訊的 Face recognition,我們一起看過了各種有趣的模型以及設計!除此之外我們也介紹了考慮資料隱私我們應該怎麼做,但可惜因為時間安排等因素沒有走到後面更有趣的主題,像是 人臉情緒識別(Face emotion recognition)& 3D 人臉建模(3DMM) 等主題,希望之後有機會可以再跟大家介紹~
那大家對我們這個系列有任何建議或者想說的話都可以在下面留言喔!或者大家想看什麼主題(或者想讓我們去填什麼坑><)都可以在下面留言給我們!
最後感謝未婚妻的持續鼓勵以及支持讓我可以順利打完這30 天 <3 <3
1.Karras, Tero, et al. "Analyzing and improving the image quality of stylegan." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020.
2.Qiu, Haibo, et al. "Synface: Face recognition with synthetic data." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
3.Deng, Yu, et al. "Disentangled and controllable face image generation via 3d imitative-contrastive learning." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020.
4.Wood, Erroll, et al. "Fake it till you make it: face analysis in the wild using synthetic data alone." Proceedings of the IEEE/CVF international conference on computer vision. 2021.
5.Bae, Gwangbin, et al. "DigiFace-1M: 1 Million Digital Face Images for Face Recognition." arXiv preprint arXiv:2210.02579 (2022).
6.Kim, Minchul, et al. "DCFace: Synthetic Face Generation with Dual Condition Diffusion Model." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.
7.Chung, Chia-Chun, et al. "SASMU: boost the performance of generalized recognition model using synthetic face dataset." arXiv preprint arXiv:2306.01449 (2023).
8.Qinwei Xu, Ruipeng Zhang, Ya Zhang, Yanfeng Wang, and Qi Tian. A fourier-based framework for domain generalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14383–14392, 2021.
9.Yanchao Yang, Dong Lao, Ganesh Sundaramoorthi, and Stefano Soatto. Phase consistent ecological domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9011–9020, 2020.
10.Yanchao Yang and Stefano Soatto. Fda: Fourier domain adaptation for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4085–4095, 2020.
11.Quande Liu, Cheng Chen, Jing Qin, Qi Dou, and Pheng-Ann Heng. Feddg: Federated domain generalization on medical image segmentation via episodic learning in continuous frequency space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1013–1023, 2021.

