在先前的「dbt 基本操作」、「dbt 資料建模」的討論裡,已經概括地介紹了最基礎的 dbt 功能。讀者如果要應用 dbt 來做一些資料工程相關的工作,之前的內容再加上一點基礎的 SQL、查一查線上的 dbt 文件,已經足以做出簡單的專案。
另一方面,如果要做的專案會日益複雜、多人一起使用、長期使用的話,就像軟體一樣,許多的小細節,都必須細細討論、建立規範,日後專案才會容易維護。
這邊列舉了一些專案從「可以動」到「容易維護」需要思考的議題:
參考下圖,其實資料建模的程式碼,即 models 資料夾下的程式碼,總共有兩個執行環境 (runtime):一個是 Jinja 語言的執行環境、另一個則是 SQL 語言的執行環境。這兩個執行環境都有提供模組化、抽象化的機制。
那使用者如何判斷,應該要用哪一個執行環境的模組化、抽象化機制呢?原則上先考慮 SQL 語言,如果 SQL 語言做不到,再考慮透過 Jinja 語言來做。
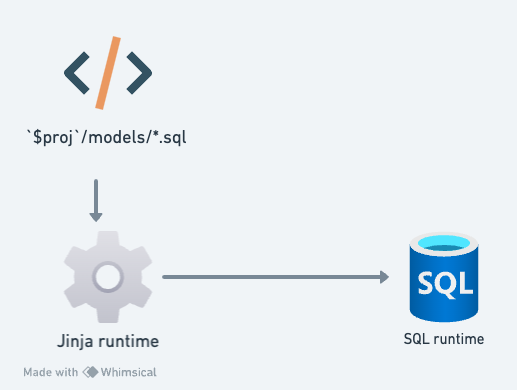
而如果要重複使用 SQL 片段的話,這就是適合用 Jinja 語言來處理的問題。而要用 Jinja 來開發自己的 Jinja macro 的話,程式碼可以放在 macros 資料夾下。
客戶問我,他有好幾個資料建模,都有一模一樣的 join 。這是因為要做資料的映射 (mapping) ,所以都得要 join 同一張表。他有在考慮,是否應該對此做模組化、抽象化。但是,心裡也覺得怪怪的,總覺得好像又有哪裡不對?
「你就放心地用 Jinja 來寫這一段程式碼的模組化、抽象化吧。」我回答了客戶。
我很確定,上述的這種對 join 的模組化、抽象化機制,在 SQL 是不存在的。但是,我曾經用過一種資料庫叫 Datomic ,它提供的查詢語言 (Datalog),就有提供 join 語句的模組化、抽象化,而且我覺得,這對程式的可讀性、可維護性,極有幫助。
也因此,我認為,客戶透過 Jinja 來補足 SQL 的不足,這是很正確的作法。
dbt 有提供 package 機制,可以讓我們跨 dbt 專案來共用程式碼。這也很近似於應用軟體開發 (application programming) 常見的作法。
引用、安裝程式碼套件:
這邊特別推荐幾個常用、好用的 dbt 套件:
dbt-labs/dbt-utils
dbt-labs/codegen
dbt-labs/dbt_project_evaluator
這些套件有什麼好用之處,已經遠超過本文的篇幅,就留待讀者自行研究了。
非 SQL query 類別的輔助用 SQL 還是有很多類,這邊先分成:
權限管理類的功能,在新版的 dbt 已經提供了 grant 關鍵字。換言之,這部分的功能,已經有一大部分被整合進入 dbt 的核心裡了,簡單的應用案例,很可能透過 dbt grant 就可以搞定,一行 SQL 也不用寫。
如果是需要被事件觸發的指令的話,dbt 提供了數個「觸發」的選項:
最後,dbt 所建議 SQL 自訂函數 (user defined function) 的管理方式是:
dbt 有提供一個叫客製命名空間 (custom schema) 的功能,它很適合把有相似功能、相似屬性的視圖,集中起來,放到一個獨立的命名空間裡。
比方說,最後產生的視圖,有 5 個是給公司的銷售團隊用的、有另外 6 組是給公司的運營團隊用的,就可以考慮產生兩個命名空間,一個叫 dev_sale 包含前 5 個視圖,另一組叫 dev_operation 包含後 6 個視圖。如此一來,使用資料的人也會覺得清楚多了。
dbt 官方有提供最佳實踐 (best practices),好好地去研究最佳實踐,貫徹最佳實踐背後內含的思想是達成長期可維護最有效的方式。
另一方面,偷懶速成的方式,則可以考慮好好地去應用之前提到的 dbt 套件 dbt-labs/dbt_project_evaluator ,它會給予一堆的警告 (warning) ,讓你去反思現在的專案裡,哪些地方可能需要改進。
不少的客戶、朋友跟我講過,覺得 dbt 的官方文件,包羅萬象,令人感到吃力與挫折。這是很正常的現象,因為軟體的文件至少有四種形式,而且其中的第三、第四項都不適合初學者看。
而本系列文是自我定位為第二項「解釋」,重點放在「背後的為什麼」,希望能幫助大家去連結:「手邊要解決的問題」與「還缺什麼關鍵知識」的落差。


 iThome鐵人賽
iThome鐵人賽