今天要教大家怎麼訓練一個模型喔!
我們在下面這個界面會發現正中央有一個 "Data" 的欄位,且分成三個格子,聰明的你們應該知道他們分別要放進哪些資料的對嗎!?
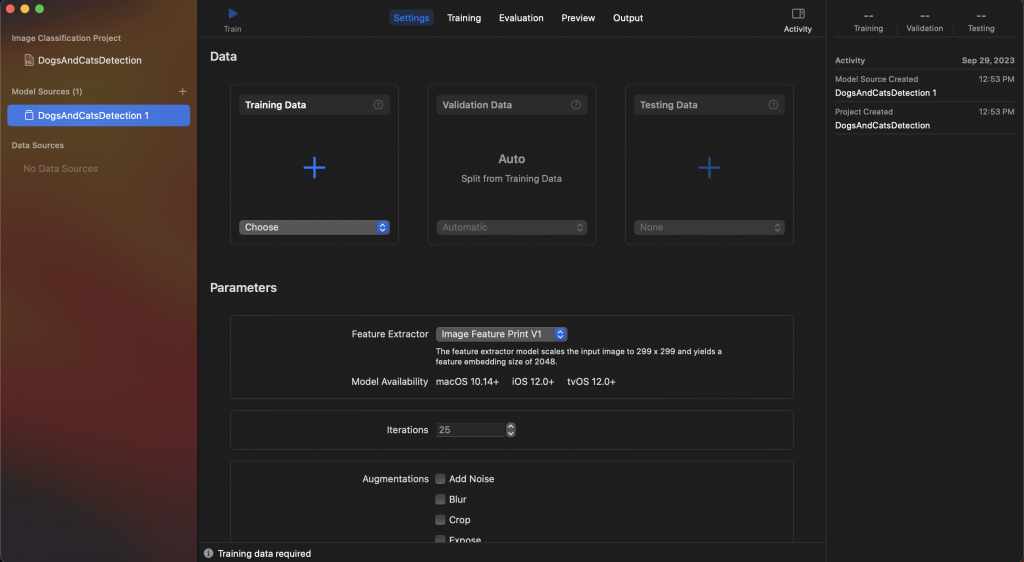
我們要分別拿出在 Day 4 切分好的
"訓練資料集" 以及 "驗證資料集"(如果有切分的話就放,沒有的話也可以讓系統自動分離出訓練資料集的資料)和 "測試資料集"
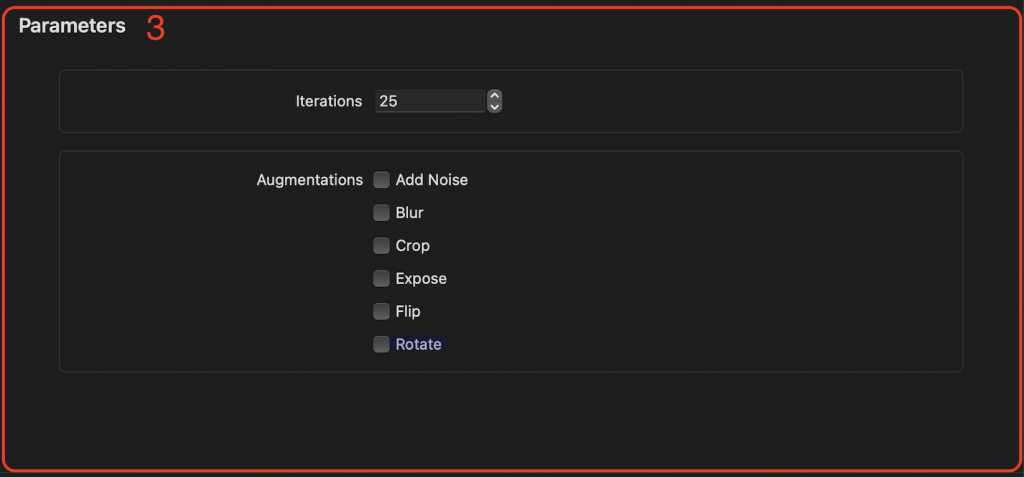
我們要調整的參數很簡單,依照剛剛在介面上介紹的,大多只需要調整 leterations 和 Augmentations 就行了。
這裡再做一下兩個參數詳細的介紹!
lterations: 訓練數據集上迭代的次數。迭代次數越多,模型就越有可能學習到數據中的模式。但是,迭代次數太多也會導致過擬合,即模型過於貼合訓練數據,而無法泛化到新數據。
Augmentations: 通過對訓練數據集中的圖像或其他數據進行隨機變換來實現。這些變換可以包括旋轉、縮放、剪裁、翻轉、添加噪聲等。
幫助模型學習到數據中的更廣泛的模式,從而提高模型的準確性和泛化性能。在某些情況下,Augmentations 甚至可以使模型在沒有額外數據的情況下提高準確性
以下是 Core ML 中 Augmentations 的一些最佳實踐:
Augmentations 項目介紹:
以上參數調整好之後就可以直接訓練了!每次訓練可以藉由慢慢調整這些參數,訓練出準確率越來越高的模型!


 iThome鐵人賽
iThome鐵人賽