
前言
終於進入最後一個主題,好感動呀😭
前面介紹的 Spark 雖然改進了 MapReduce 的缺點,讓運算效率變得更快,更是有 Spark Streamiing 來處理實時數據流,但硬要說的話,Spark 終究還是批處理架構 (微批處理),缺點是延遲較高。
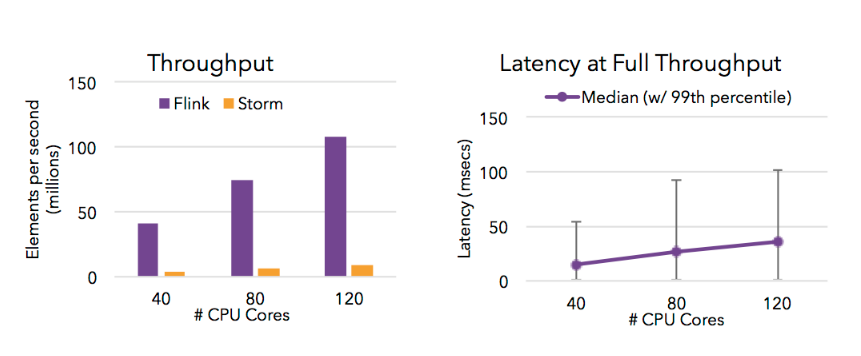
而今天要介紹的 Flink 則是真正的流處理架構,擅長處理連續的數據流,通常擁有更低的延遲!
Apache Flink 是 Apache 軟體基金會的頂級專案,Flink 主打的是一個高效率的大數據流處理 + 批處理架構,也就是所謂「流批一體」。
除了流批一體外,Flink 有幾個特色:
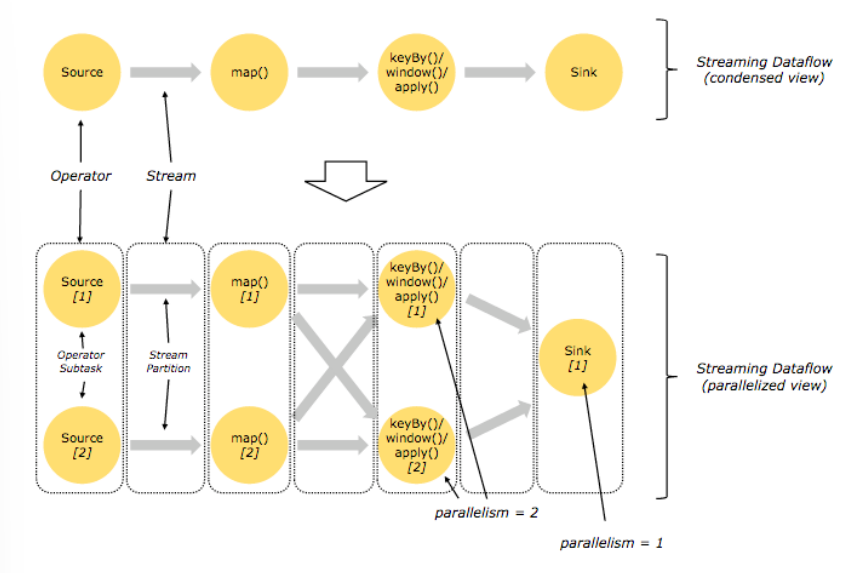
Flink 也是主從架構 (Master/Slave),由一個 JobManager 與一個或多個 TaskManager 組成。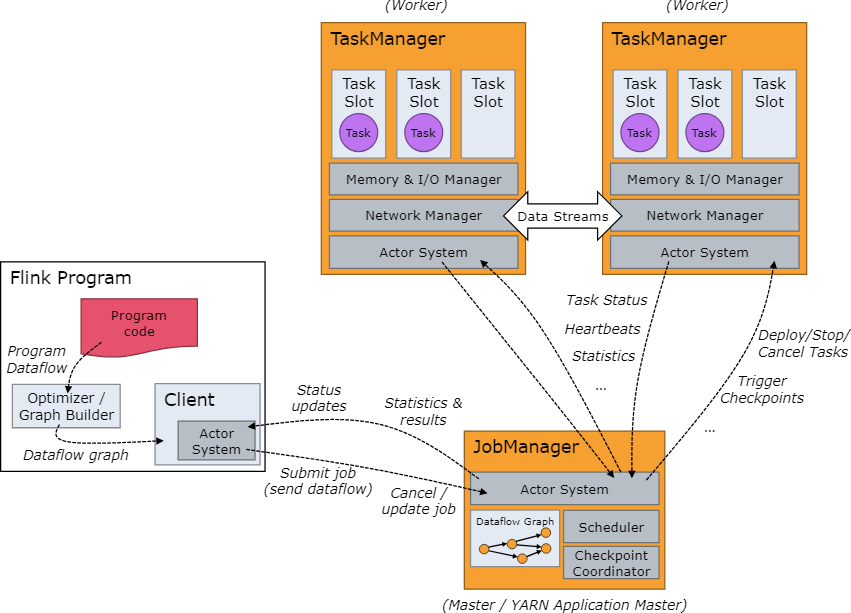
JobManager
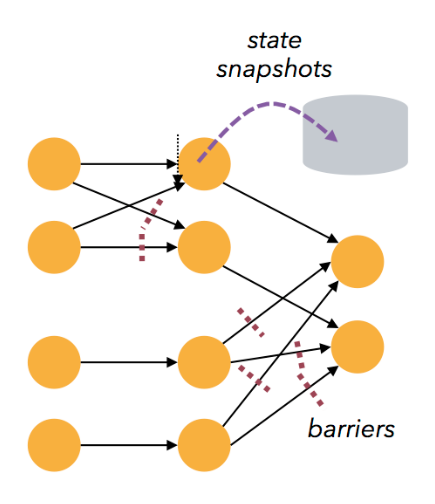
JobManager 決定任務的安排、對完成或失敗的任務作出反應、協調故障恢復等工作,其由三個部分組成,分別是:
TaskManager
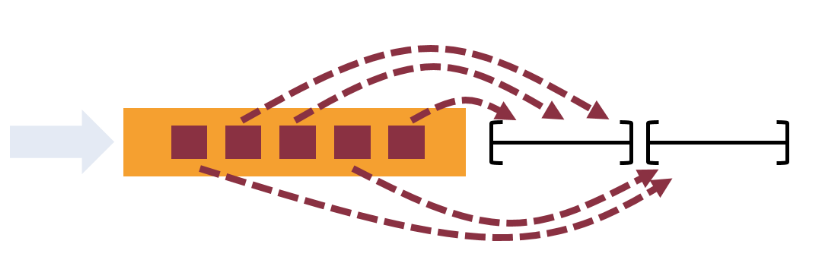
TaskManagers(也稱為工作程序)執行數據流的任務,負責接收、處理、存儲和轉發數據,同時管理和優化數據的流動。Task Slot 是 TaskManager 中資源使用的單位。
map、filter 等,而 Operator Chains (運算子鏈) 則是將 Operator 鏈接起來的一種優化機制,透過將相鄰的運算子串聯在一起以減少數據的傳輸。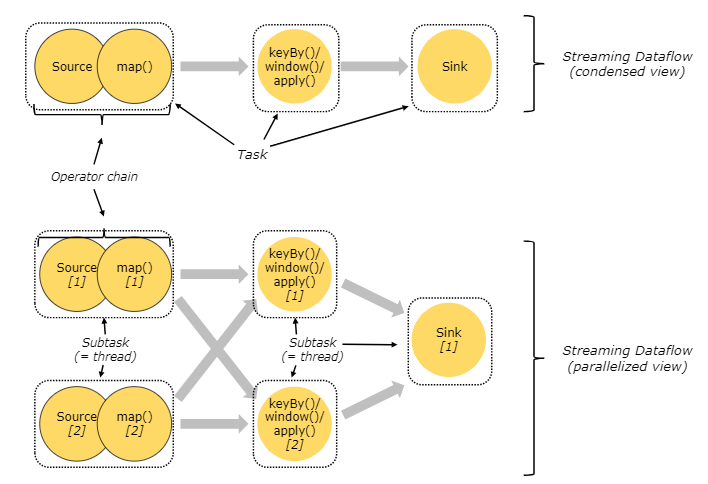
明天會介紹 Flink Ecosystem,以 Flink Ecosystem 為切入點補充一些部署與 API 的東西。
Introduction to Apache Flink
Flink Architecture
(今天的圖都來自參考資料。)


 iThome鐵人賽
iThome鐵人賽