
🔥【Vue.js → Nuxt 入門推薦!🌟 新書即將上市 🌟】
📘《想要 SSR 嗎?就使用 Nuxt 吧!Nuxt 讓 Vue.js 更好處理 SEO 搜尋引擎最佳化》
👀 Nuxt v4 內容與範例也可以參考並購買本系列文筆著所著書籍
📦 預計於 2025/08/14 出版,目前天瓏書局預購有 7️⃣8️⃣ 折優惠
👉 點此前往購買:https://pse.is/7yulnj
注意:Nuxt 4 已於 2025/07/16 釋出,本文部分內容或範例可能和最新版本有所不同
搜尋引擎之所以能搜尋到世界各底的網頁,全歸功於網路爬蟲 (Web crawler),也有人稱之為網路蜘蛛 (Spider),爬蟲是一種機器人即是搜尋引擎檢索器它存在的目的就是邊攥網路索引,但因為機器人會對伺服器發送請求,對於伺服器而言也是一個流量負擔,本篇將會介紹 robots.txt 與 Robots Tags 的差異與如何有效的設置來讓搜尋引擎爬蟲讀懂你的設定。
當網路爬蟲蒐集到網路世界存在的網址,它將會去訪問網頁內容去蒐集更多的網址,以此來拓展網頁的索引資料,以供使用者搜尋瀏覽,如果你的網站不想被這些網路爬蟲所收錄,那你可以透過搜尋引擎服務商如 Google 的搜尋引擎檢索器,可以存取網站上的哪些網址,而不是讓特定網頁無法出現在 Google 搜尋引擎結果頁 SERP (Search Engine Results Page),簡單來說就是為了避免爬蟲的請求對網站造成過於龐大的流放負擔。
顧名思義 robots.txt 是以文字的形式來進行描述,通常我們也會遵循 Google 所提出的規則來進行設定,以下是一個包含兩項規則的簡單 robots.txt 檔案:
# 1
User-agent: Googlebot
Disallow: /admin/
# 2
User-agent: *
Allow: /
# 3
Sitemap: https://www.example.com/sitemap.xml
該 robots.txt 檔案代表以下含義:
https://example.com/admin/ 開頭的網址。https://www.example.com/sitemap.xml。我們可以透過 Nuxt 的模組 Nuxt Simple Robots 來協助我們建立 robots.txt,也是本篇分享的重點。
Nuxt Simple Robots 可以幫 Nuxt 網站以程式的方式產生或合併現有的 robots.txt,模組的內建組合式函式能協助你管理頁面的 X-Robots-Tag 標頭與 Robots Meta Tag。
Step 1. 安裝套件
安裝 Nuxt Simple Robots 模組。
npm install -D nuxt-simple-robots
Step 2. 配置使用模組
在 ./nuxt.config.ts 中的 modules 屬性,添加模組的名稱 nuxt-simple-robots。
export default defineNuxtConfig({
modules: ['nuxt-simple-robots']
})
當你配置好 Nuxt Simple Robots 模組後,預設情況下,模組使用伺服器中間件於執行時建立 rotbots.txt,或者在預渲染時在 ./public 目錄下建立 rotbots.txt 檔案。
在非生產環境下,判斷方式為 process.env.NODE_ENV !== 'production',模組將產生一個 rotbots.txt 來禁止所有的機器人檢索。
User-agent: *
Disallow: /
反之,在生產環境下模組將產生一個 rotbots.txt 來允許所有的機器人檢索。
User-agent: *
Disallow:
你可以在瀏覽器中瀏覽 /robots.txt 來查看產生的規則,也可以加入 ?indexable=true 於開發環境下查看如生產環境下允許檢索的規則。
// 依據環境,產生禁止或允許的規則的 robots.txt
https://example.com/robots.txt
// 不論環境,產生允許檢索的規則
https://example.com/robots.txt?indexable=true
// 不論環境,產生禁止檢索的規則
https://example.com/robots.txt?indexable=false
只要有使用 nuxt-simple-sitemap,在 Nuxt Simple Robots 模組無需任何配置,模組預設會自動整合資料,例如產生的 rotbots.txt 會添加一條 sitemap 的路徑。
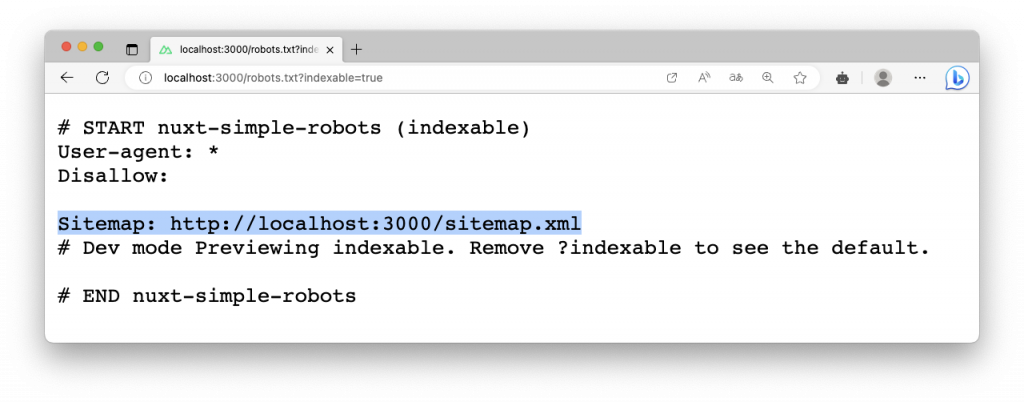
在還沒有使用 Nuxt Simple Robots 模組之前,robots.txt 通常會遵循命名,如果使用了 Robots.txt 或 robots 作為檔案名稱,可能導致無法正確被解析,官方也建議使用 robots.txt 作為檔案名稱,因為這更接近標準。
此外 robots.txt 檔案通常會放置於,./public/robots.txt 提供訪問,檔案網址也建議放置在根目錄,例如 http://localhost:3000/robots.txt。
當你啟用了 Nuxt Simple Robots 模組,且存在 ./public/robots.txt 檔案,這表示發生了衝突,模組為了會將該檔案移動重新命名,並在訪問 /robots.txt 時合併規則。
例如建立一個檔案 ./public/robots.txt。
User-agent: Googlebot
Disallow: /admin/
在啟動開發伺服器並訪問 /robots.txt,模組會將原 ./public/robots.txt 移動至 ./public/_robots.txt,而模組產生的規則也會與 ./public/_robots.txt 進行合併。
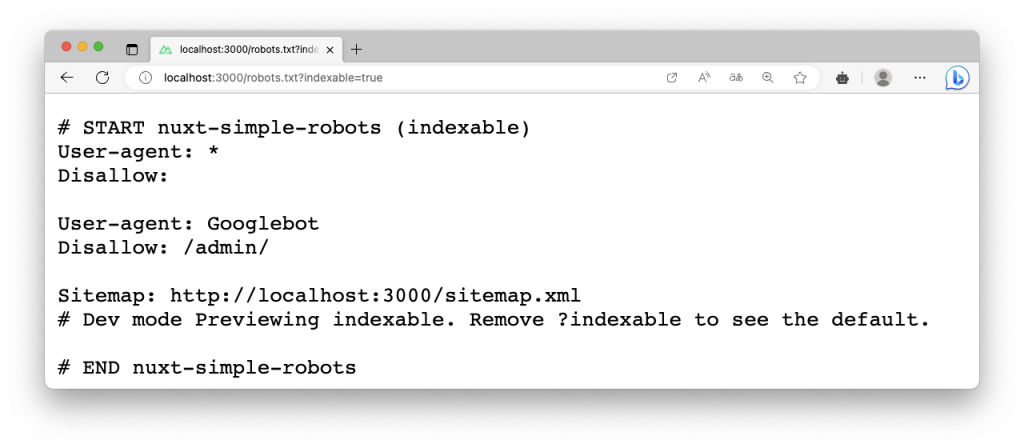
如果手動建立 robots.txt 來提供模組進行合併,你可以調整 ./nuxt.config.ts 檔案內的模組選項 mergeWithRobotsTxtPath 來設置從任何路徑載入 robots.txt。
export default defineNuxtConfig({
modules: ['nuxt-simple-robots'],
robots: {
mergeWithRobotsTxtPath: 'assets/custom/robots.txt'
}
})
你可以編輯 ./nuxt.config.ts 檔案內的模組選項 disallow 與 allow,來控制規則的產生。
例如,為所有機器人 (user-agent: *) 提供簡單的禁止規則:
export default defineNuxtConfig({
modules: ['nuxt-simple-robots'],
robots: {
allow: '/admin/login'
disallow: ['/secret', '/admin'],
}
})
這將產生下列規則:
User-agent: *
Allow: /admin/login
Disallow: /secret
Disallow: /admin
當需要針對特定機器人時,你可以使用 group 選項來建立更精細的控制。
export default defineNuxtConfig({
modules: ['nuxt-simple-robots'],
robots: {
groups: [
{
userAgent: ['AdsBot-Google-Mobile', 'AdsBot-Google-Mobile-Apps'],
disallow: ['/admin'],
allow: ['/admin/login']
},
{
userAgent: ['*'],
disallow: ['/secret']
}
]
}
})
這將產生下列規則:
User-agent: AdsBot-Google-Mobile
User-agent: AdsBot-Google-Mobile-Apps
Allow: /admin/login
Disallow: /admin
User-agent: *
Disallow: /secret
很多人會誤以為設定 robots.txt 就可以讓特定網頁不被索引到,不會出現在搜尋引擎的結果上,其實不然,正確的做法應該是要使用標記 noindex,而這個指令是需要撰寫在 HTML 的 Meta Tag 或是 HTTP 請求的回應標頭 X-Robots-Tag。
也就是說 Robots Tags 與 robots.txt 分別告知搜尋引擎爬蟲不同的資訊:
你可以在網頁的 添加 Robots Meta Tag 來標記網頁不允許索引。
<meta name="robots" content="noindex">
你可以選擇使用 Nuxt3 的 useHead 或 useServerHead 組合式函式來產生:
<script setup>
useHead({
meta: [{ name: 'robots', content: 'noindex' }]
})
</script>
Robots Meta Tag 標籤規則以 name 表示提供給特定搜尋引擎爬蟲,通常 robots 適用各家爬蟲,而標籤的 content 則表示規則,常見的規則有 all、noindex、nofollow、nosnippet、none 等,詳細的規則與說明可以參考 Google 提供的有效的索引建立和摘要提供規則。
預設情況下,Nuxt Simple Robots 模組僅使用 /robots.txt 和 HTTP 請求回應的標頭 X-Robots-Tag 來控制索引 (Index)。
X-Robots-Tag 可做為特定頁面的 HTTP 回應標頭,任何在 Robots Meta Tag 所標記的規則,也可以指定給 X-Robots-Tag。
例如爬蟲發送請求一個網頁,HTTP 請求回應的 X-Robots-Tag 標頭標示為 noindex,表示該頁面不允許索引。
HTTP/1.1 200 OK
Date: Sat, 09 Sep 2023 00:00:00 GMT
(…)
X-Robots-Tag: noindex
(…)
當使用 Nuxt Simple Robots 模組,你可以透過 Nitro 路由規則,添加 robots 的選項設定來讓特定路由自動產生 X-Robots-Tag。
舉例來說,當爬蟲爬取到 /secret 頁面,就算爬取了也不允許索引收錄至搜尋引擎資料庫內。
export default defineNuxtConfig({
routeRules: {
'/secret': { robots: 'noindex' },
}
})
若你在 Nitro 路由規則,將特定路由的 index 選項設定為 false,則等同於設定模組robotsDisabledValue 的值,預設為 noindex, nofollow。
舉例來說,當爬蟲爬取到管理相關 /manage 開頭的頁面,頁面請求將會回傳 noindex, nofollow,意即就算爬取了也不允許索引及不允許繼續前進其他網頁內的其他連結。
export default defineNuxtConfig({
routeRules: {
'/manage/**': { index: false },
}
})
對於網站來說,Robots Tag 與 robots.txt 都是 SEO 的一環,對於一些未完成的或測試的頁面,甚至是網站後台或不應該被揭露出來的頁面,你都應該使用 Robots Tag 來禁止索引,避免一些悲劇或敏感網頁出現在搜尋引擎的搜尋結果上。
robots.txt 通常會設定禁止一些敏感的後台、私密的頁面或需要登入的情況才能瀏覽資料,但是這個規則並沒有辦法控制爬蟲不索引你的頁面,因為真正控制索引的並不是這個 robots.txt,robots.txt 只是為了提醒爬蟲這些特定頁面你不應該爬取了,這些頁面你爬了也沒有用只是增加我伺服器的負擔罷了。
Robots Tag 的較關注的是索引 (Index),而 robots.txt 是在爬取 (Crawl) 層面。
Robots Tag 與 robots.txt 所關注的與使用的方式都有點不大一樣,或許你的需求僅是不希望爬蟲索引收錄你的資料,那麼你就應該要直接使用 Robots Tag,但是有模組可以幫助我們產生 Robots Tag 與 robots.txt 那何樂而不為,本篇簡單的分享了用法與常用設定,更多的 API 與配置也可以參考官方文件。
感謝大家的閱讀,歡迎大家給予建議與討論,也請各位大大鞭小力一些:)
如果對這個 Nuxt 3 系列感興趣,可以訂閱接收通知,也歡迎分享給喜歡或正在學習 Nuxt 3 的夥伴。
參考資料

