首先我們先匯入要用到的模組,因為TensorFlow Keras內建數據集,主要集中在分類任務的數據集上,所以我們用Scikit-learn來匯入回歸數據集-加州房價,此外如果想要分析其他的資料也可以上網搜尋喔!
有興趣的人可以參考:https://zhuanlan.zhihu.com/p/618818240
#匯入模組
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split #將數據集劃分為訓練集和測試集
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Dropout
from tensorflow.keras import optimizers
import numpy as np
載入數據,這邊的寫法跟之前有些不一樣。在Scikit-learn中,fetch_california_housing函數返回的數據是NumPy數組,而不是像Keras中的數據集那樣有load_data方法(之前是這樣寫:(X_train, y_train), (X_test, y_test)=mnist.load_data())
# 載入加州住房價格數據集
california_housing = fetch_california_housing()
X, y = california_housing.data, california_housing.target
# 將數據集劃分為訓練集和測試集(80%訓練,20%測試)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
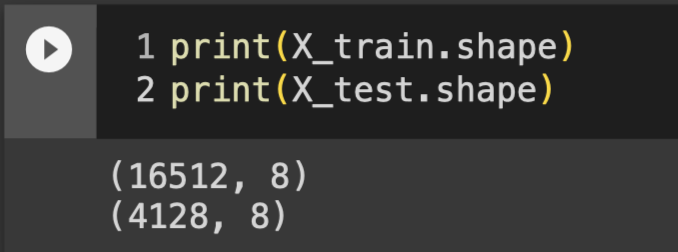
可以發現我們的訓練樣本有16512筆,測試樣本有4128筆
#可以用print一次就顯示X_train和X_test的shape
print(X_train.shape)
print(X_test.shape)
也可以用分兩個儲存格分別寫
X_train.shape
X_test.shape
fetch_california_housing 函數載入的加州住房價格數據集包括加州不同地區的住房價格相關變量。這個數據集包含:MedInc(該地區的中位數收入)、HouseAge(該地區的中位數住房年齡)、AveRooms(該地區的平均房間數目)、AveBedrms(該地區的平均臥室數目)、Population(該地區的人口數)、AveOccup(該地區的平均住房占用率)、Latitude(該地區的緯度)、Longitude(該地區的經度)共八個
X_train[0]

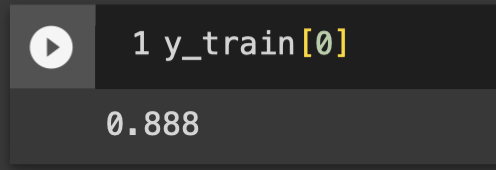
#查看實際房價中位數
y_train[0]
雖然輸入變量只有8個,但訓練樣本有16512筆,所以我們分別給第一、第二隱藏層64神經元和32神經元,並且加上前幾天學的批次正規化還有丟棄法。最不一樣的地方在輸出層,激活函數用了一個沒有介紹過的linear,因為我們在架設回歸模型,預測的結果會是連續變量,線性激活函數linear可以幫助模型不會對輸出進行任何非線性變換。
#建構神經網路
model = Sequential()
#輸入層+第一隱藏層
model.add(Dense(64, activation='relu', input_shape=(8,)))
model.add(BatchNormalization())
#第二隱藏層
model.add(Dense(32, activation='relu'))
model.add(BatchNormalization())
model.add(Dropout(0.2)) #每批次隨機丟棄此層 20% (1/5)神經元
#輸出層
model.add(Dense(10, activation='linear'))
因為對於回歸模型,輸出並非機率,所以我們把損失函數改用MSE,並且把準確率(accuracy)拿掉
#編譯模型
model.compile(loss='mean_squared_error', optimizer='adam')
訓練40週期,訓練完之後我們再來用實際資料去看看我們架設好的神經網路模型進步的空間。其實訓練出來的損失函數蠻飄忽不定的,可以從1.多到0.4多
#訓練模型
model.fit(X_train, y_train, batch_size=8, epochs=40, verbose=1,validation_data=(X_test, y_test))
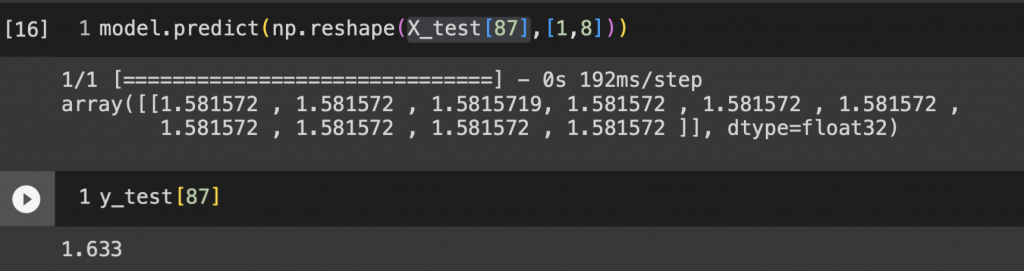
我們來預測第87筆資料,因為資料是矩陣模式,所以我們先轉換為 [1, 8] ,這是因為模型通常預期輸入是一個二維陣列,其中每行代表一個樣本,每列代表一個特徵。預測結果出來雖然說沒有差距到非常多,但也有進步的空間,大家都可以用前面介紹過的功能持續優化這個加州房價回歸模型喔!
#預測
model.predict(np.reshape(X_test[87],[1,8]))
#查看87筆的實際價格
y_test[87]


 iThome鐵人賽
iThome鐵人賽