
| 資訊處理流程 | 生成 | 收集 | 儲存 | 使用 |
|---|---|---|---|---|
| Tempo | ✓ | ✓ |
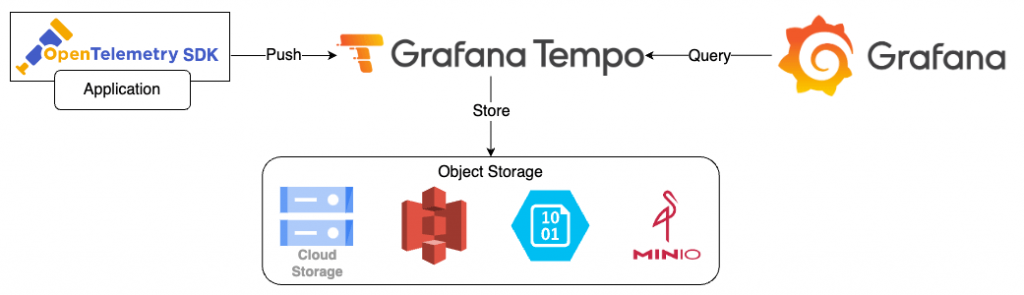
Tempo 是由 Grafana Labs 在 2020 年 10 月推出的一款高效、使用便捷以及成本低廉的 Tracing Backend。Tempo 主要解決了其他 Tracing Backend 因儲存成本過高而無法保留所有 Traces 的問題,避免落入發生問題卻找不到 Trace 的窘境。Tempo 的策略是將 Traces 存放到 Object Storage 中,例如 Google Cloud Storage 或 Amazon S3,除了利用 Object Storage 低成本的優勢,也同時避免了需要維護像是 Elasticsearch 或 Cassandra 這類其他儲存服務的成本。
在資料收集方面,Tempo 秉持 Grafana Labs 的開放精神,支援多種 Tracing Protocol,包括 Jaeger、Zipkin 和 OpenTelemetry。至於在使用者介面方面,Tempo 主要透過 Grafana 進行操作。簡言之,Tempo 負責接收和儲存 Traces,並透過 API 方式將 Traces 提供給 Grafana 進行查詢,整體架構相對單純。
Grafana Labs 在 2023 年 2 月發佈 Tempo 2.0 時,也隨之推出了 TraceQL。這是一種專為 Trace 設計的查詢語言,靈感來自於 PromQL,並且延續了 LogQL 的 Pipeline 設計。通過使用 TraceQL,使用者可以更加精準地查詢 Span 資料,並且支援多種聚合函數,如 count()、avg()、min()、max()、sum() 等。
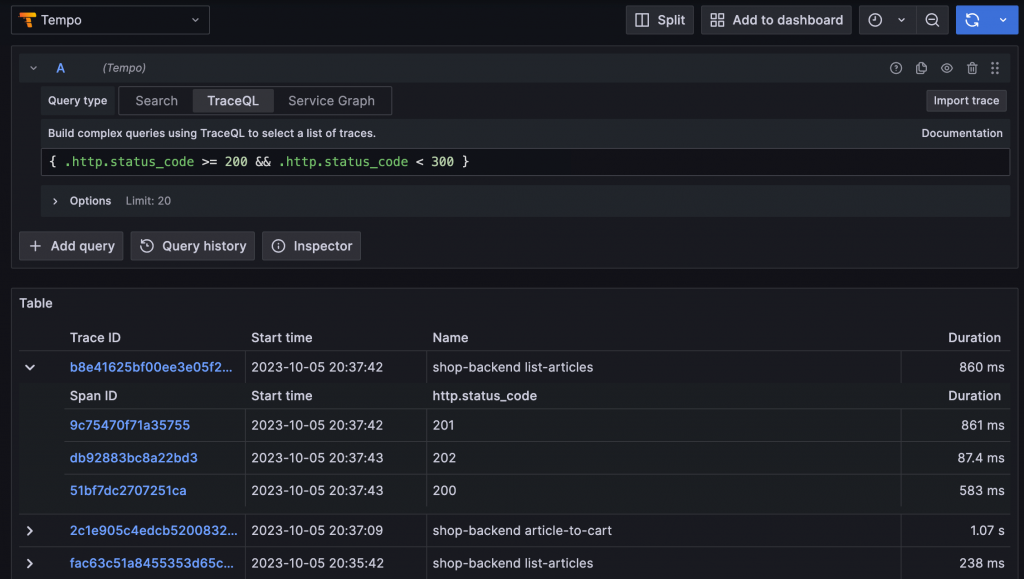
TraceQL 查詢範例圖
TraceQL 查詢案例:
查詢 http.status_code 為 200 的 Span
{ .http.status_code >= 200 && .http.status_code < 300 }
查尋執行時間介於 0.5 秒到 1 秒的 Span
{ duration >= 0.5s && duration < 1s }
使用正規表達式查詢 http.url 符合 /api/v1/.* 的 Span
{ .http.url =~ "/api/v1/.*" }
查詢 Trace 內有 Span db.statement 符合 INSERT.* 且這些 Span 的平均執行時間超過 1 秒
{ .db.statement =~ "INSERT.*"} | avg(duration)>1s
查詢 http.status_code 為 500 且 http.url 符合 /api/v1/.* 且 http.method 為 POST 或 PUT 的 Span
{
.http.status_code = 500 &&
.http.url =~ "/api/v1/.*" &&
(.http.method = "POST" || .http.method = "PUT")
}
從 2.0 版本開始,Tempo 支援 Apache Parquet 作為預設的儲存格式。Parquet 是一種 Column-based 的開源資料格式,它不僅能有效地壓縮資料,而且查詢效率高。它還支援多種程式語言,如 Java、Python 和 Go。
在介紹 2.0 版本新功能的文章中提到,改採用 Parquet 格式的其中一個原因是希望使用者能更全面地控制 Tracing Data,能夠依需求搭配其他工具分析資料,而不受限於 Tempo 的功能範疇。同時間推出的 TraceQL 也是基於 Parquet 設計,從而實現更高效和便捷的資料查詢。
Metrics-generator 是 Tempo 的一個可選功能,需要手動啟用。其主要作用是根據 Traces 生成與 Request 相關的 Metrics,如執行次數和執行時間分布。由於 Trace 完整記錄了 Request 的時間、來源與目標,Metrics-generator 能提供以下兩個主要功能:
要啟用 Metrics-generator,需要在 Tempo 的設定檔中添加以下設定:
metrics_generator:
storage:
path: "/tmp/metrics"
remote_write:
- url: "http://prometheus:9090/api/v1/write"
overrides:
metrics_generator_processors:
- service-graphs
- span-metrics
其他 Metrics-generator 的詳細設定可以參考官方文件。
因為 Metrics-generator 僅負責生成 Metrics,而 Tempo 本身不儲存 Metrics,所以必須透過 Prometheus Remote Write API 將 Metrics 儲存至 Prometheus 或其他支援的服務,例如 Mimir、Cortex 等。因此,在設定檔中,我們需要指定 storage.remote_write 以設定 Metrics 儲存的服務,而 storage.path 是用於暫存 Metrics 的目錄。Span Metrics 和 Service Graphs 則是透過 overrides.metrics_generator_processors 來個別啟用。
Span Metrics 提供的 Metrics 包括:
這些 Metrics 預設的 Label 有 service、span_name、span_kind、status_code,如果要設定其他的 Label,可以透過 metrics_generator.processor.span_metrics.dimensions 設定,例如增加 http.status_code。
Service Graphs 是透過 Prometheus Metrics 的方式紀錄服務間的關係,所以需要在 Tempo 的 Data Source 設定 Metrics 來源的 Prometheus,並且啟用 Grafana 的 tempoServiceGraph feature 才能使用。
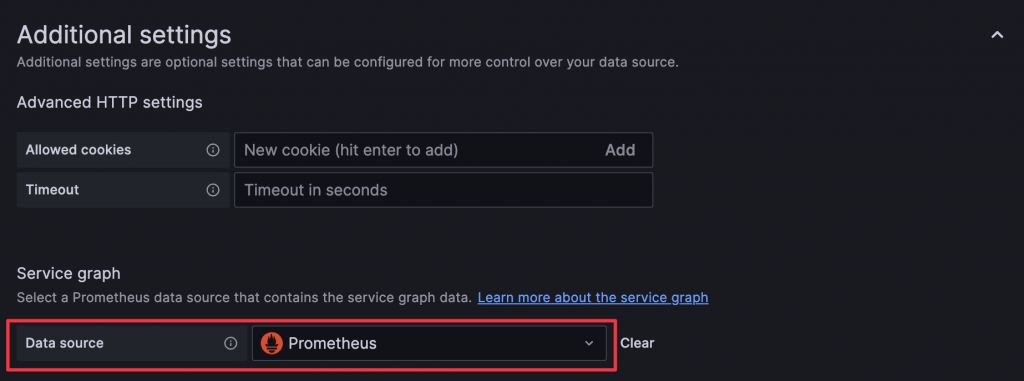
Tempo Data Source 設定 Prometheus 方式
Grafana 要啟用 feature 的方式有兩種:
於 Grafana config 中設定 feature_toggles,例如:
# grafana.ini
[feature_toggles]
enable = tempoServiceGraph
使用環境變數 GF_FEATURE_TOGGLES_ENABLE,例如:
# docker-compose.yaml
grafana:
image: grafana/grafana:10.1.0
environment:
GF_FEATURE_TOGGLES_ENABLE: "tempoServiceGraph"
Service Graphs 的畫面如下:
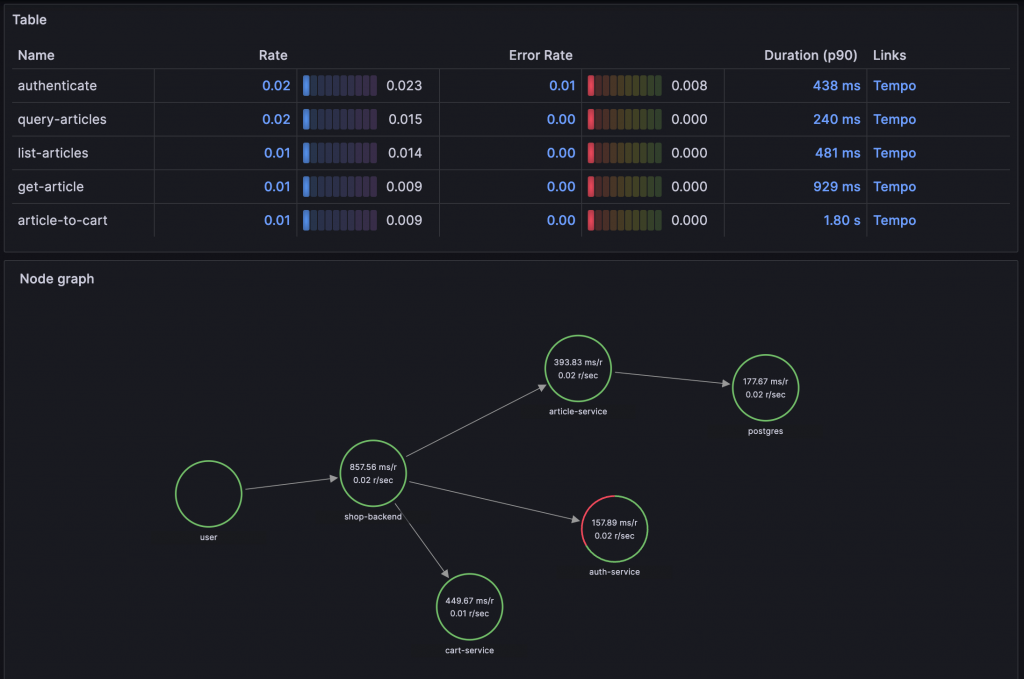
可以查看 Service 之間的關係,並且可以看到根據 Span Name 分析的 RED Metrics
範例程式碼:20-tempo
啟動所有服務
docker-compose up -d
檢視服務
admin/admin
點擊左上 Menu > Explore,左上 Data Source 選擇 Tempo
透過瀏覽器對 application 的 /chain 發送 Request,可以在 Trace 資訊中看到 app-a、app-b、app-c 互相呼叫的順序
或是使用 k6 發送 Request
k6 run --vus 1 --duration 300s k6-script.js
關閉所有服務
docker-compose down
啟動所有服務
docker-compose -f docker-compose.fake.yaml up -d
檢視服務
admin/admin
Tempo
關閉所有服務
docker-compose -f docker-compose.fake.yaml down
Tempo 在 Tracing Backend 領域具有明顯的優勢,尤其是在成本和簡易性方面。它不僅允許使用者選擇將資料儲存在 Local Disk 或 Object Storage,而且安裝和部署過程也相對簡單。如果已經是 Grafana 的使用者,那麼 Tempo 絕對是值得考慮的選項。除此之外,Tempo 也提供了強大的 Metrics-generator 和 TraceQL 功能,進一步方便了使用者從 Traces 資料中獲取有用的服務資訊。

