我想任何資料工作者,甚至任何現代坐辦公室的人,都應該用過GSheet、Excel這類Spreadsheet工具。而(至少我個人認為 :P)會不會用VLOOKUP則是Spreadsheet進階用戶(Power User)的分水嶺。VLOOKUP是Excel最早一批函數之一,包含在1985年麥金塔 1 (Macintosh 1)平台上發佈的EXCEL 1,也是根據微軟統計EXCEL上第三常用的函數(排在SUM和AVERAGE之後)。
VLOOKUP的函數語法如下:
=VLOOKUP(搜尋值, 範圍, 索引, [已排序])
我猜大部分看這篇文章的人應該都知道如何使用VLOOKUP,就不多做解釋了。不了解的人建議可以參考GSheet的說明文檔: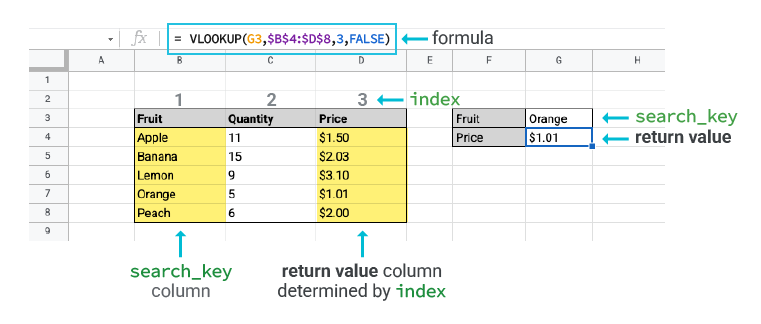
出處:Goole文件編輯器說明
比較有趣的是VLOOKUP的第四個參數已排序 / is_sorted。可以從Google的解釋文檔看出端倪:
4. 已排序:選填。請選擇下列任一選項:
為什麼_建議選項_不是_預設值_呢?
已排序 / is_sorted 解釋輸入VLOOKUP(..., 0)或VLOOKUP(..., FALSE)已經成為大多數進階使用者的習慣,但很多人可能也沒有去鑽研VLOOKUP(..., TRUE)的實際意義。
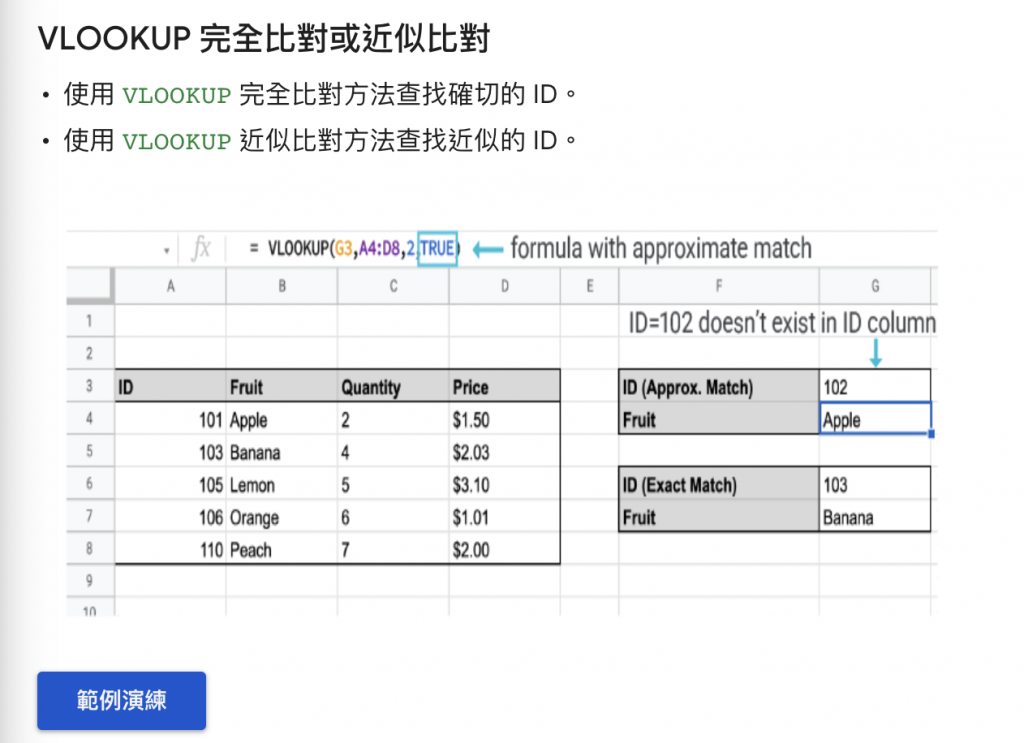
Google的範例中有簡單提到,傳回的是”近似的值“,但其實不太準確。要到詳細說明內才有比較精準的解釋:
如要搜尋資料表中不存在的 ID 值「102」,則近似比對方法會傳回較小的近似值「101」,因為在搜尋值資料欄中找到的「101」是小於且最接近「102」的值。
採用近似比對方法時,系統會沿著搜尋值資料欄向下搜尋,*直到找到比指定搜尋值還大的值為止。系統會停在該較大近似值的前一個資料列,然後傳回該資料列位於傳回值資料欄中的值。*換句話說,如果未依遞增順序排序搜尋值資料欄,則很可能會傳回不正確的值。
···
採用完全比對方法時 (例如,已排序 = FALSE),系統會傳回完全相符的值。舉例來說,ID = 103 的水果名稱是「香蕉」(Banana)。如果找不到完全相符的值,系統就會顯示 #N/A 錯誤。我們建議使用完全比對方法,因為比較能夠預測其行為。
如果大部分的人的使用習慣是完全比對,完全比對也比較好預測,為什麼預設選項是“近似比對”呢?其實跟大部分奇怪的IT現象一樣,由於歷史和保持兼容性。

