其實8堂課上完,還是很多東西不太懂,似懂非懂。
有看過書,但他的書也跟他講的課一樣,突然就會飛進來一小節額外的內容
就像前一陣講怎麼玩minst影像,突然就會插進來額外的:彩色影像處理
但minst 是黑白的阿…突然跟我講彩色影像怎麼處理…
所以總結,看他的書之前,需要有基礎
看他的課(影片)之前,需要看過他的書
這樣才能「比較」理解他在做什麼
所以他標榜的有點不實😆😆😆 課程應該是給有經驗的人上的才對。
那我就想藉由第4課的美國專利片語相似度大賽開始
因為第四課只是讓我們知道「nlp」是怎麼一回事,並沒有好好打比賽
雖然講師留了一個更精進的notebook,但是對於上了四堂課的人來說,其實是看不太懂的。
所以我預計看幾篇比較多人投票的筆記,來好好研究一下這個比賽要怎麼打。
所謂知己知彼,百戰百勝?
要想打好比賽,資料的認識應該要更完整。
在前幾天美國專利片語相似度大賽的筆記中,我已經分享了一些講師用到的EDA,
今天就來分享另一名網友的EDA,看看他是怎麼分析資料的。
一開始他分享了什麼是皮爾森相關係數的公式,這個寫得很好,但是沒人想看,
因為直接call library就可以幫忙算了XD
所以焦點放在其他部份
以下分三個部份討論:片語1(anchor)、片語2(target)、分類編號(context)
這邊劇透一下,他的context 是有專門去查專利(CPC classification (version 2021.05))的內容,所以不再是沒文字意義的編號了!
這邊講師直接是用summary,但是這位網友提供了info 跟 isnull 也不錯
info() 的資訊其實kaggle 頁面就有,但是我們用程式看的話,還是要學一下
isnull 顧名思義就是找有沒有缺失值,這個在鐵達尼的資料中就有缺失值,所以保持習慣檢查也是必要的。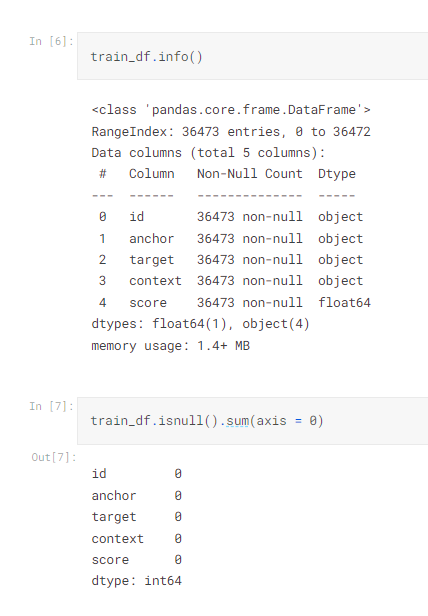
檢查完缺失值,就檢查有沒有重複值
train_df[train_df.drop("id", axis = 1).duplicated()]
這個技巧也蠻重要
結果是沒有重複值,也沒有缺失值。
所以這邊網友沒有用summary ,這個是我們之前上課用的,可以觀看各資料頻率
以下就來看看各資料屬性
來看看這作者有哪些花招
print(f"Number of uniques values in ANCHOR column: {colored(train_df.anchor.nunique(), 'yellow')}")
#output is Number of uniques values in ANCHOR column: 733
這邊用了train_df.anchor.nunique() 來計算有多少種anchor ,也就是重複的不計算,
一共有 733 種anchor
接下來想看一下都是哪些anchor

如果想要查
"anchor" 欄位的值必須為 "component composite coating"。
"target" 欄位中必須包含字串 'base'。
則程式如下
pattern = 'base'
mask = train_df['target'].str.contains(pattern, case=False, na=False)
train_df.query("anchor =='component composite coating'")[mask]
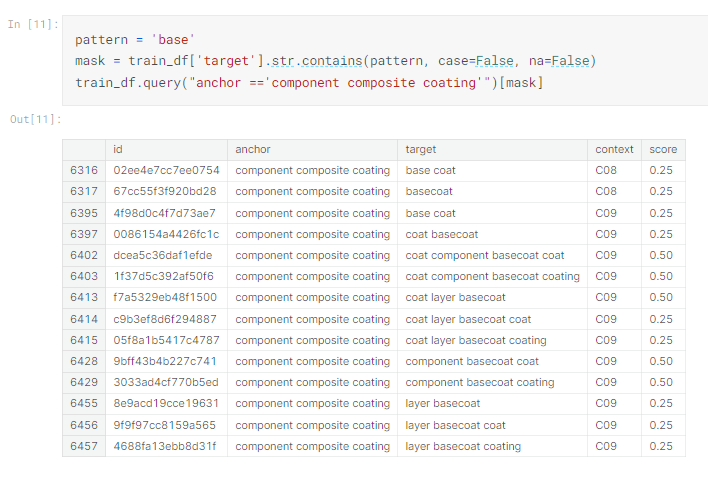
這邊就可以看到同樣的anchor ,不同的target 的得分有所不同
然後還花俏的展示了文字雲,但我覺得不必要。
這個比較實用一些,我們看一下怎麼寫
train_df['anchor_len'] = train_df['anchor'].str.split().str.len()
print(f"Anchors with maximum lenght of 5: \n{colored(train_df.query('anchor_len == 5')['anchor'].unique(), 'yellow')}")
print(f"\nAnchors with maximum lenght of 4: \n{colored(train_df.query('anchor_len == 4')['anchor'].unique(), 'green')}")
其實他會這樣寫就表示他已經跑過程式,知道最多5個詞
所以第一行他新建了一個欄位'anchor_len',是用anchor這個欄位做空格分隔,然後計算長度,但這邊比較特別的是.str.len():這是計算每個文本值(經過分割後的單詞列表)的長度,也就是詞的數量,然後返回一個列表
我們可以用剛才算好的詞數量,來畫直方圖,看看分佈情況
train_df.anchor_len.hist(orientation='horizontal', color='#FFCF56')
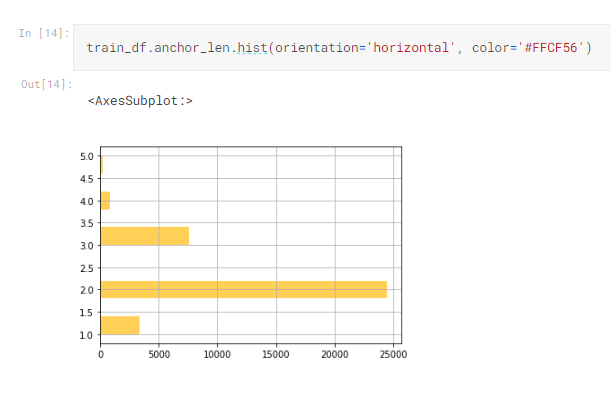
所以看得出來最多5個詞,但2個詞的佔大多數(觀察到這個不知有什麼差?)
雖然不知道數字有沒有影響,但是可以先看看
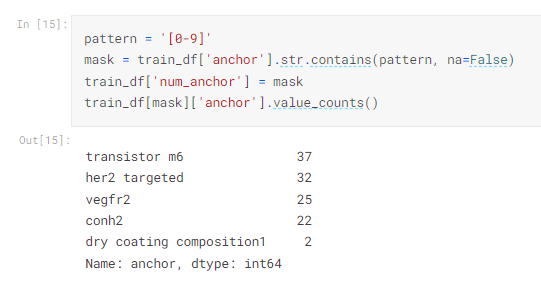
pattern = '[0-9]'
mask = train_df['anchor'].str.contains(pattern, na=False)
train_df['num_anchor'] = mask
train_df[mask]['anchor'].value_counts()
到此對anchor 觀察完畢,然後我們也會target做一樣的事
因為同anchor的方法 ,所以不贅述
這邊先去查專利的分類來源:https://en.wikipedia.org/wiki/Cooperative_Patent_Classification
作者還另外找到2個資料集
Cooperative Patent Classification (CPC) Data -> https://www.kaggle.com/datasets/bigquery/cpc
Cooperative Patent Classification Codes Meaning -> https://www.kaggle.com/datasets/xhlulu/cpc-codes
由Wiki可以知道這個分類的編號代表什麼意思
A: Human Necessities
B: Operations and Transport
C: Chemistry and Metallurgy
D: Textiles
E: Fixed Constructions
F: Mechanical Engineering
G: Physics
H: Electricity
Y: Emerging Cross-Sectional Technologies
可以知道前面的英文字母,叫做Section ,後面的編號,叫做class
所以這邊可以將他們拆開來,分別統計看看
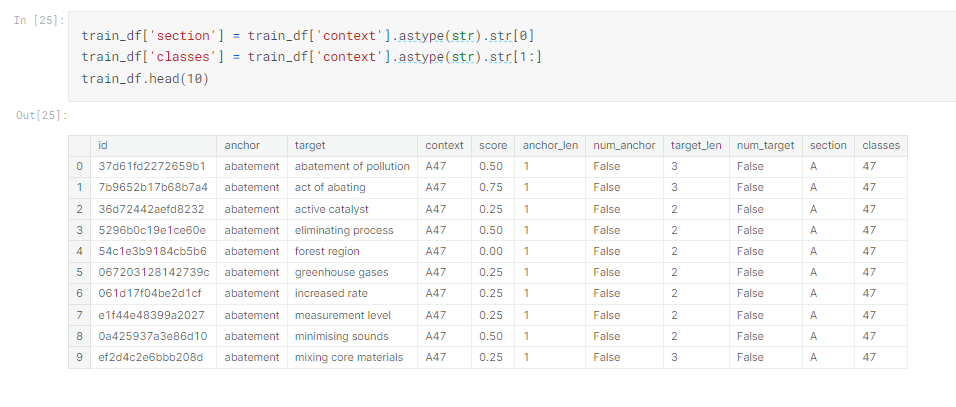
train_df['section'] = train_df['context'].astype(str).str[0] #section
train_df['classes'] = train_df['context'].astype(str).str[1:] # class
train_df.head(10)
不能免俗的要看算一下有幾種,雖然不知道有什麼用,可能要跟數據培養感情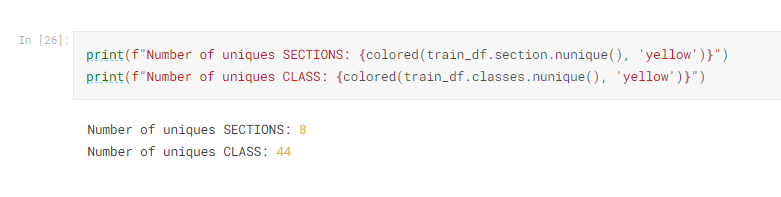
這邊一樣做個直方圖,只是換掉欄位名稱~一個小技巧
di = {"A" : "A - Human Necessities",
"B" : "B - Operations and Transport",
"C" : "C - Chemistry and Metallurgy",
"D" : "D - Textiles",
"E" : "E - Fixed Constructions",
"F" : "F- Mechanical Engineering",
"G" : "G - Physics",
"H" : "H - Electricity",
"Y" : "Y - Emerging Cross-Sectional Technologies"}
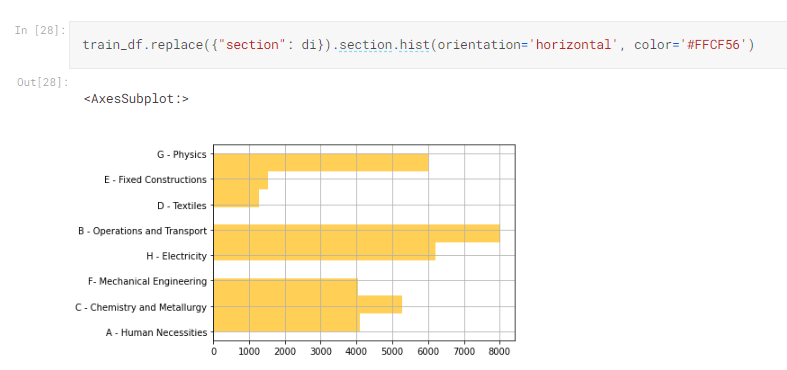
這邊是我覺得比較特別的了~因為有特別去查詢CPC資料,讓我們對於section 後面的數字應該會比較有感覺
例如A01,由wiki 查的資料只知道是Human Necessities,但不知道細部的是什麼,如果可以再細分的話,應該對於自然語言分析會更有幫助
根據注解的那個網址,我們可以找到這個notebook,裡面有教我們怎麼去query cpc 的資料
# Cooperative Patent Classification (CPC) Data -> https://www.kaggle.com/datasets/bigquery/cpc
cpc = bq_helper.BigQueryHelper(active_project="cpc", dataset_name="cpc")
def get_cpc_row(cpc_code):
query = f"""
SELECT * FROM `patents-public-data.cpc.definition` WHERE symbol="{cpc_code}";
"""
response = cpc.query_to_pandas_safe(query)
return response
get_cpc_row('A47')

然後透由第二個資料集 https://www.kaggle.com/datasets/xhlulu/cpc-codes
,也可以查到「titles」,看來第二個資料集的titles 的品質較好一點
所以我們把第二個資料集,拿來合併,希望是可以讓anchor, taget , titles ,這3個欄位來做NLP
# Let's join two datasets and add descriprion of context to our training DS
train_df['context_desc'] = train_df['context'].map(cpc_codes_df.set_index('code')['title']).str.lower()
train_df.to_csv("us-train.csv", index = False)
train_df.sample(10)
所以這2份資料可以合併,主要是我們的context ,跟第2份的code 相同,所以train_df['context'].map(cpc_codes_df.set_index('code')['title']):這一行 train_df 中的 'context' 列中的每個元素(CPC 代碼)映射到 cpc_codes_df 中 'code' 列對應的 'title' 列,這樣就可以把title 附加上去。
來看一下整理好的資料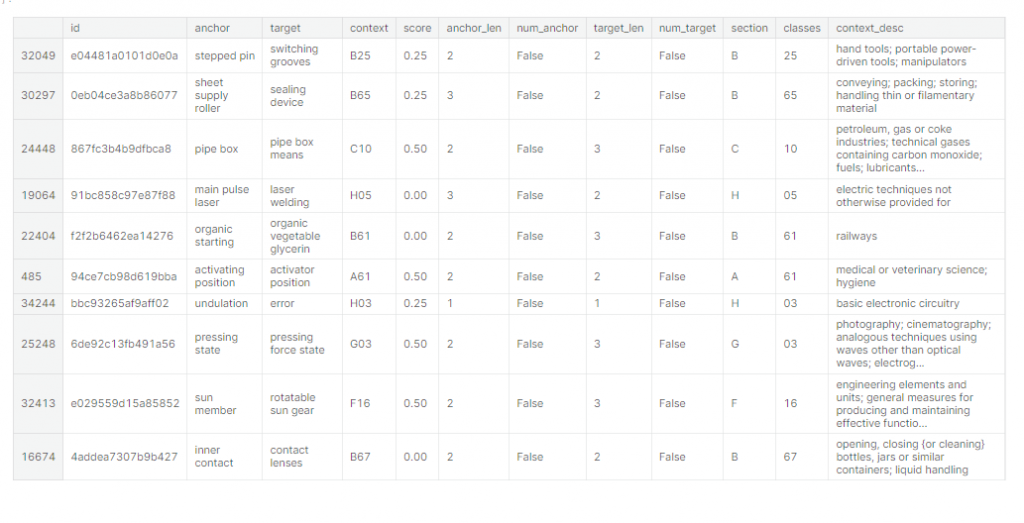
所以從這篇筆記,可以學到要怎麼觀察資料,檢查資料,還有尋找資料。
這樣至少有一點進步了,明天再來看一篇比較多人推薦的建model的notebook

