前言:我們前面講用密集神經網路處理MNIST手寫圖片數字,第一步驟就是把28 * 28的二維降為一維陣列,還記得當初說每個像素值都被視為一個特徵,需要784個神經元去接收嗎?如果影像的像素質很大(以手機為例,Apple iPhone 14 主鏡頭就有1200萬像素了),神經網路計算量就會爆開,這時侯我們就需要派上卷積神經網路了(Convolutional Neural Networks,CNN)。
卷積神經網路會比較兩張圖片裡的各個局部,這些局部被稱為特徵(feature),而卷積層的主要任務就是負責做特徵擷取。
在卷積神經網絡(CNN)的捲積層中,卷積核(Convolutional Kernel)負責掃描和處理輸入圖像。這些卷積核又有人稱為:過濾器(Filter),用於特徵提取,它們透過滑動(卷積)輸入圖像,並計算局部區域的特徵。
卷積的計算:
假設我有張一4X4的像素圖,以及我想擷取特徵的2X2矩陣
白色像素格值為1,黑色像素格值為-1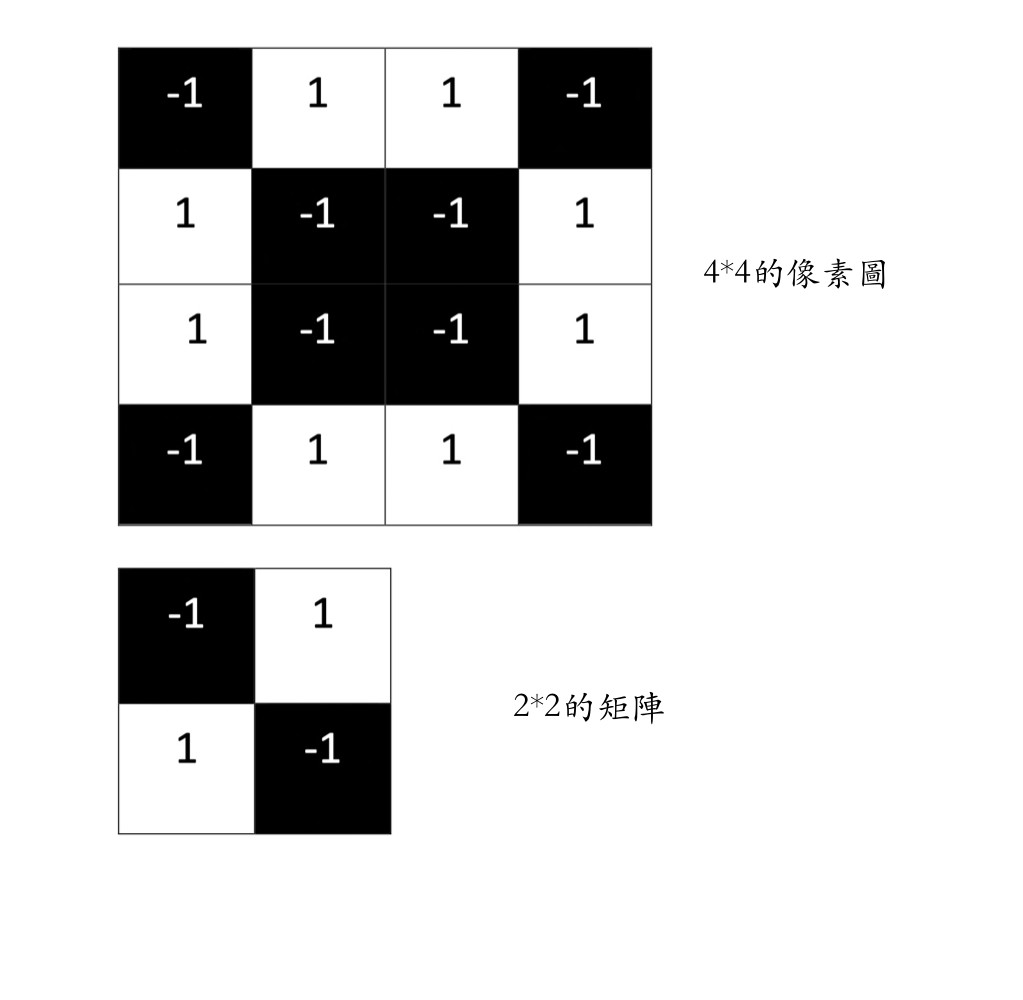
要計算特徵和圖片局部的相符程度,需要將兩者(4X4的像素圖&2X2矩陣)像素上的值相乘=總和,然後總和/擷取特徵的像素的數量(2X2=4)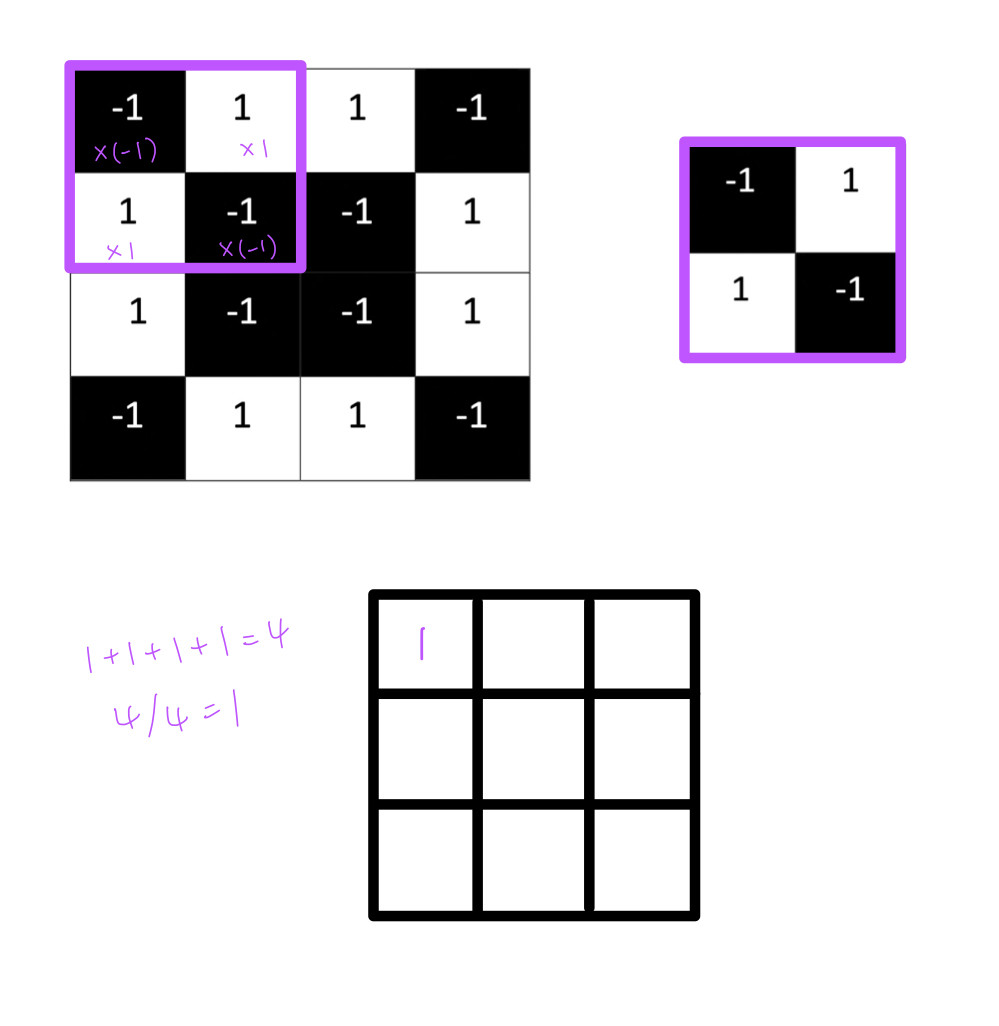
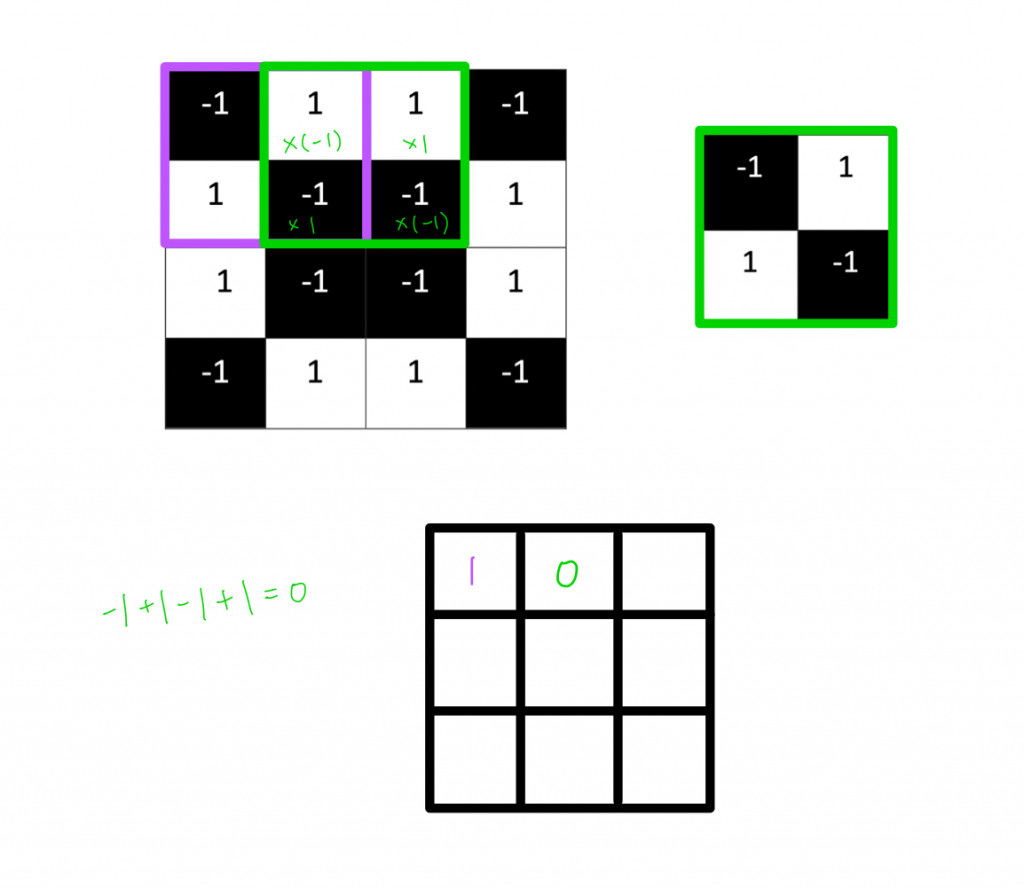
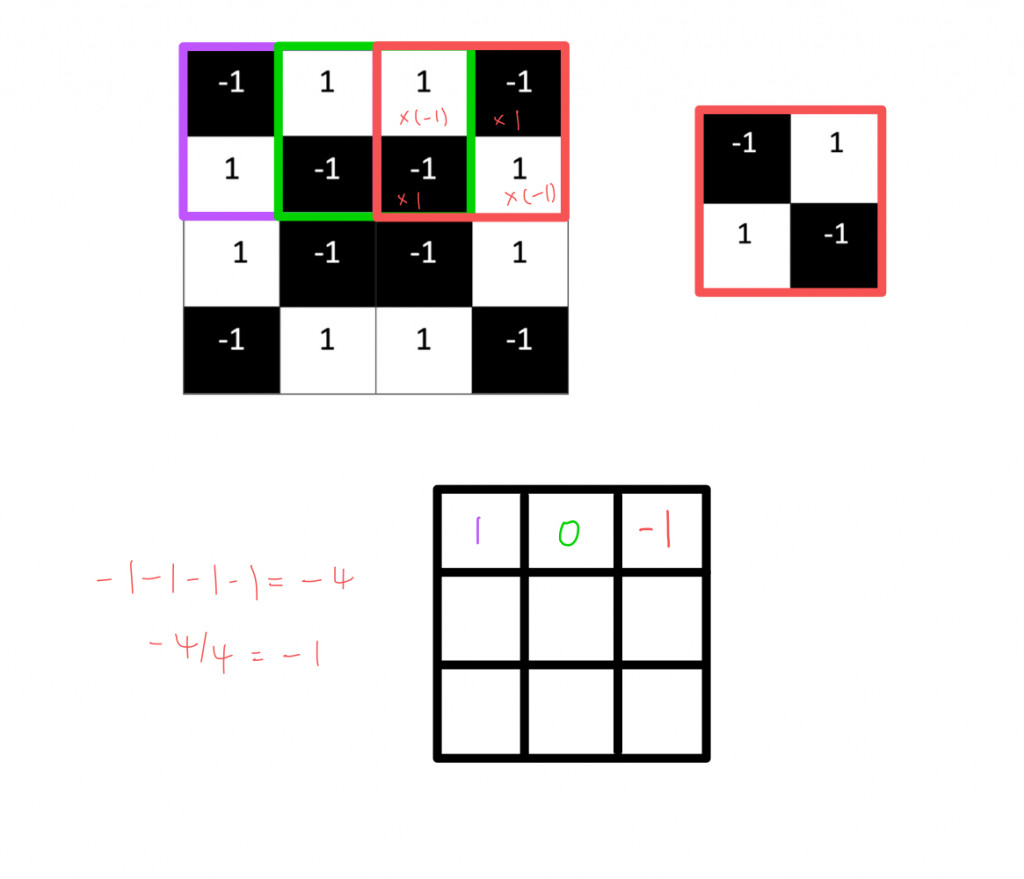
我們會發現,如果兩張圖的每個相素都相符,計算出來就會得到1,不管是白色白色(1X1)還是黑色黑色(-1X-1);反之,如果兩者的像素完全相異,就會得到-1。
我們只要重複上述過程,就可以很簡單地歸納出圖片各種的特徵。我們可以根據每次卷積的值和位置,製作一個新的二維矩陣。利用特徵篩選過後的原圖,它可以告訴我們在原圖的哪些地方可以找到該特徵。值越接近 1 的局部就會和原圖越相符,值越接近 -1 則相差越大,至於值越接近 0 的局部,則幾乎沒有任何相似度。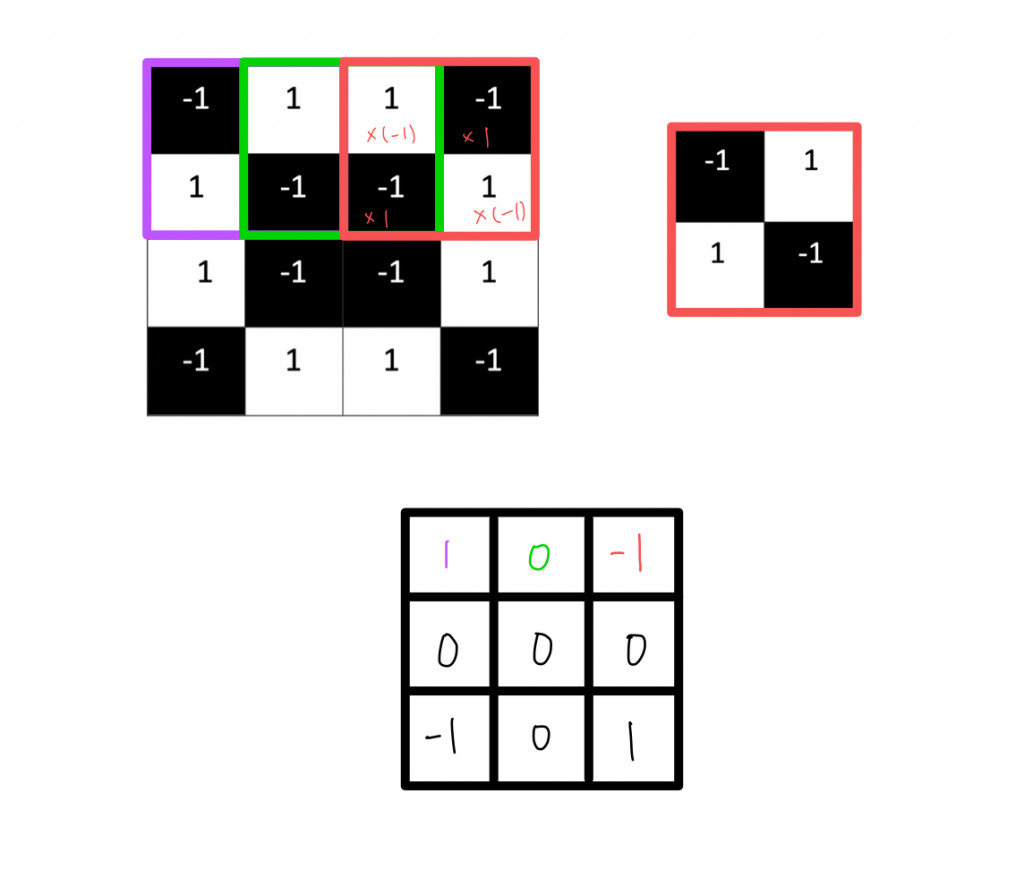
依照上面的運算方式,發現每做一次卷積,出來後的特徵圖就會變小,做越多次就會越來越小,原本4X4的圖片跟2X2的矩陣做卷積出來後的圖變成3X3的,那到底怎麼運作出我們想要的樣子呢?我們明天繼續!


 iThome鐵人賽
iThome鐵人賽