前言
這是 Flink 介紹的第二篇,還沒看過第一篇的可以先去看看:Day21 - Flink 介紹 (1):簡介、架構、數據處理
昨天講的部分屬於 Flink 的 Rnutime,往下還有存儲與部署,往上則有 API 與函式庫,今天我們就來看一下 Flink Ecosystem。
Flink 雖然沒有自己的存儲系統,不過可以從多種來源讀取與寫入資料,包括檔案系統 (如:HDFS)、資料庫 (如:HBase、MongeDB)以及訊息佇列 (如:RabbitMQ、Kafka) 等。
Flink 有三種部署模式,分別是 Application Mode、Per-Job Mode 與 Session Mode: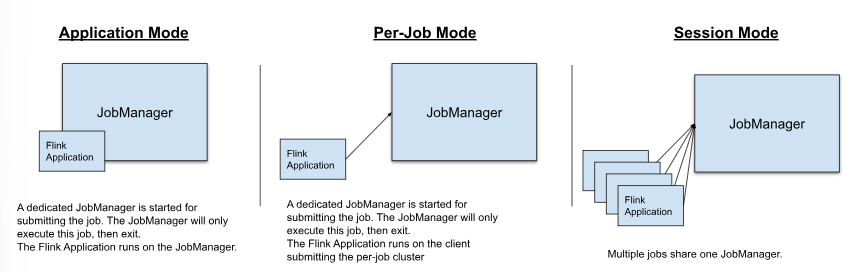
Flink 可以在單機部署,如果是部署在集群中,Flink 預設為 standalone 模式,使用自己的資源管理器 (Flink ResourceManager),不過他也可以使用外部資源管理器 (如:YARN、Mesos) 或容器管理平台 (如:Kubernetes),一些雲服務也支援 Flink (如: Amazon EMR、Google Cloud Dataproc 等)。
Flink 有階層式的 API,如下圖: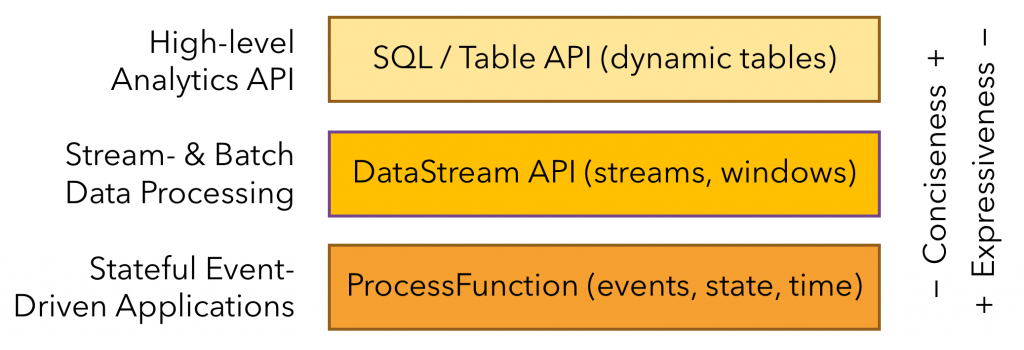
補充說明:
Flink 還有另一個核心 API:DataSet API (Legacy),用來處理有界數據、批處理,但在 1.12 版後就被軟棄用了 ,官方建議直接用 SQL / Table API 來進行批處理操作。
明天是進入 Flink 的安裝與配置教學!


 iThome鐵人賽
iThome鐵人賽